
note の記事のバックアップを取ってみた話。

完全に、趣味というか、自己満足というか、仕事の延長線上というか…。たまにはゴリゴリの技術的な内容の記事でも書いてみます。
前に、note にはエクスポート機能がないのでいざという時に困りそうだなということを書いた気がする。なので、無いなら作ってしまおうと思い立った次第。でもせっかくなら欲張って、別の媒体(はてなブログ)もワンクッション置いてみる。理由は、何かあった時、はてなブログ側で標準搭載されているエクスポート機能を利用すればいいので。
そういったわけで、大まかな方針は、こんな感じで作る。
・note の記事データをファイルに出力
・はてなブログにも記事データを同期
note の記事データは、私なんか全然数は少ないものの、さすがに手で全部書き写すのは疲れそうだったので、ぜひともプログラムに働いてもらうことにした。ファイルに落とすとか、それぞれの媒体から記事を抜くとかは色々情報が出回っているけれど、まとまったものが無かったので、この際、一気通貫でやる。
今回は、興味本位で API を使ってみる。幸い、はてなブログは、API が参照系も更新系も揃っているし、note のほうも、非公式ながら、参照系だけはあるようだ。そして、言語は、今流行りで参考情報も結構豊富にあったPython あたりをチョイス。
開発の準備段階として、やったことは下記の通り。
1.はてなブログの作成(アカウントも含む)
2.はてなブログの編集モードをMarkdownに
3.はてなブログ側のAPI公開キー発行
4.Python開発環境を整えたら、ひたすらコードを書く
というわけでやってみました。
1.はてなブログの作成(アカウントも含む)
まずはアカウントを作成してブログ開設。
https://asaburo-bkup.hatenablog.com/
※このブログはあくまで note の内容をコピーするだけです。ここで何か更新とかはするつもりはないです。
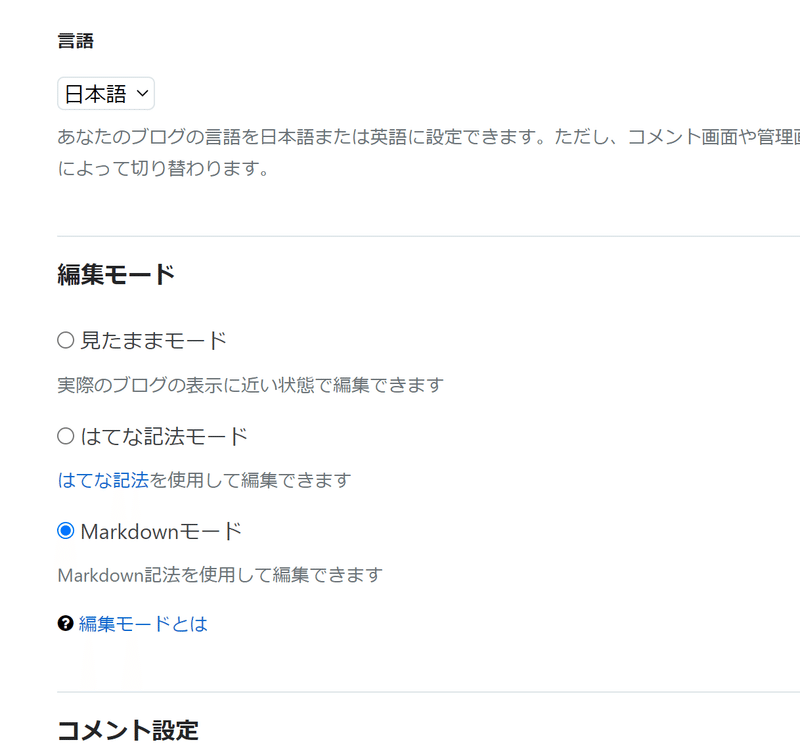
2.はてなブログの編集モードをMarkdownにしておく
これは結構盲点で、普通に同期させようと思ったらデータがうまく変換できないといった事象が発生していた。原因はどうやら同期先側のブログの設定で、「見たままモード」というやつだと、上手く xml を読み込んでくれないっぽかった。なので、設定を変えておく。
↓この「Markdownモード」というのです。
3.はてなブログ側のAPI公開キーを発行
AtomPub というのを用いるのだけれど、これは設定画面から詳細設定を開いて、API のキーを発行しておくだけ。発行されたらその文字列を、自分の大切な人以外の誰にも教えないように大事にしておく。
4.Python開発環境を整えたら、ひたすらコードを書く
Windows 環境です。別にマシンスペックとかは普通。せっかく書くなら IDE がいい。ということで、たまたま私が使っているPCに、VisualStudioCode が入っていたので、それを使った。
たしか入れた当時、Python インストールとかした気がしたけれど、詳しい手順は忘れてしまった。今、バージョンを見てみると、どうやら3.8系が入っているようなので、それを使うことにした。でも、今回のために、フォルダは切って、ちゃんと仮想環境(virtualenv)は作るようにした。開発環境を整える手順として、そんなようなことをするんだということは薄っすら覚えていた。そこで pip も最新化。
あとは、ひたすら書く。ネットで見聞きした情報を集めては組み合わせて。
全体の処理はザッとこんな感じの流れ。
1.note の記事情報をAPI で抽出
2.note の情報(1.)を Excel ファイルに出力
3.はてなブログの記事を API で抽出
4.抽出した note (1.)を繰り返し処理
4-1.note のタイトルがはてな(3.)にも存在すれば更新
4-2.はてな(3.)に存在しない場合は新規で投稿
恥を忍んで書いたものを公開してみます。コードは下記のとおり。
実は Python に関しては、ほんのり触ったことがある程度なので、お作法的に「けしからん!」な内容が含まれるかもしれないですが、大目に見てくださると幸い。
参照ライブラリについて
import re
import sys
import requests as req
import time
import pandas as pd
from xml.sax.saxutils import escape
from datetime import datetime
from bs4 import BeautifulSoup as bs4
from markdownify import markdownify as md(解説)
試行錯誤やりすぎてしまったので、pip で入れたライブラリは山ほどあり。なのでそれは恥ずかしすぎるので公開しないです。すみません。import 内容で推し量ってください。
同期に必要な識別情報の変数について
n_id = "note のユーザー名"
h_id = "はてなブログのはてなID"
h_blog_domain = "はてなブログのドメイン"
h_api_key = "API キー"(解説)
必要なのはこれくらいかな。これらの変数はハードコードしてもいいけど、コマンドライン引数(sys.argv[xxx])で受け取るようにしておいたりするとラクです。アカウント名やドメインを変えるのも簡単なので。
メイン処理について
# 投稿元の note の記事を取得
arr = get_note_entry()
# 全記事をExcelファイルにバックアップ
bkup_excel(arr)
# はてなブログの記事タイトル一覧を取得
title_list = get_hatena_entry_title_list()
for data in arr:
key = title_list[data[0]] if data[0] in title_list else "" # 記事IDがあれば更新モード
# はてなブログに記事を投稿
ret = post_hatena_entry(data[0], str(data[2]),['noteエントリ'],data[3],key) # カテゴリ名は適当(解説)
実行方法は、私の環境は、VisualStudioCode なので普通にデバッグ実行してもいいけれど、いちいち VS Code 起動するのも面倒くさい。なので、py ファイルを pyinstaller 等で exe 化しておいたりして、あとは実行すればいいだけの状態にしておくと便利。
処理内容はコメント通りですが、まずは、note から記事のデータを取得。そして、取得したものをリスト(タイトルとか本文とか投稿日とか)で保持。そのリストを、Excel ファイルに出力。
次に、はてなブログの記事のタイトルを取得。で、取得したものをリスト(Key:タイトル/Value:記事ID)で保持しておく。
note のリストと、はてなのリストを比較して、はてなブログに記事が存在する場合は、note の内容で上書きする。はてなブログに記事がないなら、note の内容で新規に投稿。
カテゴリ名は適当(「noteエントリ」)です。
はてなブログから記事データを取得する関数
def get_hatena_entry_collection_uri():
""" はてなブログ から記事コレクションを取得 """
service_doc_uri = f"https://blog.hatena.ne.jp/{h_id}/{h_blog_domain}/atom"
res_service_doc = req.get(url=service_doc_uri, auth=(h_id, h_api_key))
if res_service_doc.ok:
soup_servicedoc_xml = bs4(res_service_doc.content, features="xml")
collection_uri = soup_servicedoc_xml.collection.get("href")
return collection_uri
return False
def get_hatena_entry_title_list(limit_max_iterations=50, wait_s=0.01):
""" はてなブログ から記事のタイトル一覧を取得 """
collection_uri = get_hatena_entry_collection_uri()
if not collection_uri:
raise Exception("Not get collection uri.")
dic_entry = {}
for i in range(limit_max_iterations):
# Basic認証で記事一覧を取得
res_collection = req.get(collection_uri, auth=(h_id, h_api_key))
if not res_collection.ok:
return False
# Beatifulsoup4でDOM化
soup_collection_xml = bs4(res_collection.content, features="xml") # entry elementのlistを取得
entries = soup_collection_xml.find_all("entry")
pub_entry_list = list(filter(lambda e: e.find("app:draft").string != "yes", entries)) # 下書きを無視
for data in pub_entry_list:
dic_entry[data.title.contents[0]]= re.search(r"-(\d+)$", string=data.id.string).group(1)
# 次のcollection_uriへ更新
link_next = soup_collection_xml.find("link", rel="next")
if not link_next:
return dic_entry
collection_uri = link_next.get("href")
if not collection_uri:
return dic_entry
# wait
time.sleep(wait_s)# 10ms
return dic_entry(解説)
全然 API の仕様を理解してないので見様見真似。
恐らくですが、記事のコレクションの中身の個数は決まっていて、次のコレクションは"next"のところにリンク貼ってあるようですね。もうほとんど参考にさせていただいたところから全部コピペです。すみません。
とりあえず、dic_entry 変数で、Key:タイトル/Value:記事IDを保持しておくようにしてます。このコレクションは、はてな側に記事があるか無いかを判定する際に使います。
note から記事データを取得する関数
def get_note_entry_body(key):
""" note から特定の記事の本文全文を取得 """
n_entry_url=f"https://note.com/api/v1/notes/{str(key)}"
res_dictEntry=req.get(n_entry_url).json()
body = res_dictEntry["data"]["body"] # 本文
return body
def get_note_entry():
""" note から記事情報を取得 """
res=[]
# 記事一覧(最大251記事。1ページあたり6記事)
for page in range(1,43):
n_list_url=f"https://note.com/api/v2/creators/{n_id}/contents?kind=note&page={str(page)}"
# API
res_dict=req.get(n_list_url).json()
for i in range(len(res_dict["data"]["contents"])):
l = res_dict["data"]["contents"][i]
title = l["name"] # タイトル
key = l["key"] # key
body = get_note_entry_body(key) # 本文(# 上記APIでは記事本文全てが取得できなかったのでKeyをもとに別のAPIを呼ぶ)
publish = l["publishAt"] # 投稿日時
tags = [ i["hashtag"]["name"] for i in l["hashtags"] ] # タグ一覧(使う予定ないけど一応取っておく)
res.append([title,key,body,publish,tags])
return res(解説)
note のほうの API も仕様が分からない。どうやら、記事を取得しようとすると特定の個数しか取れない模様。そのため、ページを繰って最後まで見に行っている。のかな・・?
で、他の方はどうやっているか分からないけれど、私のほうで API 使うと、どうやら記事データの本文のところが途中で切れちゃってた(やり方はあるのかもしれないけど、ちょっと調べて出来なかったので諦めました)。
なので、本文に関しては、get_note_entry_body() 関数を別で用意して、そこで記事のIDをもとに別のAPI を呼んで、無理やりゴソッと記事の情報そのものを取得するようにしてます。
ハッシュタグについては使わないけど、参考にさせていただいたサイトに倣って、一応取っておきました。
Excel ファイルにバックアップする関数
def bkup_excel(res):
""" Excel ファイルにバックアップ保存 """
# Pandasで整形
df=pd.DataFrame(res)
df["hashtags"] = df[4].apply(len) # ハッシュタグ数
tags=df[4].apply(pd.Series)
tags.columns=[ "tag_"+str(x) for x in tags.columns ]
df=pd.concat([df,tags],axis=1)
df=df.rename(columns={0:"title",1:"key",2:"body",3:"publishAt"})
del df[4]
# エクセルファイルとして保存
dt_now = datetime.now().strftime('%Y%m%d')
df.to_excel("export/note_entry_bkup-" + dt_now + ".xlsx") (解説)
pandas というライブラリを使ってデータ整形してます。よく分かってないですけど、DataFrame という仕組みを使って、簡単に Excel ファイルに出力できます。ちなみに、引数の res は、get_note_entry() 関数から受け取った記事データのリストです。
出力ファイルは出力日をファイル名に含めてます。既にファイルが存在する場合は上書き。それと、一番大切なポイントは、フォルダ「export」を事前に作成しておく。作っておかないとたしか処理はそこで落ちたはず。そもそも、別にフォルダ切らなくてもいいかなと思ったのだけれど、なんとなく何回も実行するので1か所にまとめておきたかった。
はてなブログに投稿する関数
def post_hatena_entry(title, content, categorys=[], updated="", key="",draft=False):
try:
""" はてなブログに記事を投稿 """
h_url = f"https://blog.hatena.ne.jp/{h_id}/{h_blog_domain}/atom"
updated = updated if updated else datetime.now().strftime("%Y-%m-%dT%H:%M:%S")
draft = "yes" if draft else "no"
category = lambda x: "\n".join([f"<category term='{e}' />" for e in x])
categorys = category(categorys) if category else ""
content_parsed = escape(md(content)) # content をそのまま投稿しようとするとXMLParseエラー発生するので色々変換
xml = f"""<?xml version="1.0" encoding="utf-8"?>
<entry xmlns="http://www.w3.org/2005/Atom"
xmlns:app="http://www.w3.org/2007/app">
<title>{title}</title>
<author><name>name</name></author>
<content type="text/markdown">{content_parsed}</content>
<updated>{updated}</updated>
{categorys}
<app:control>
<app:draft>{draft}</app:draft>
</app:control></entry>""".encode(
"UTF-8"
)
if key=="":
# 記事が無ければ新規投稿
r = req.post(h_url + "/entry", auth=(h_id, h_api_key), data=xml)
if r.ok != True:
raise Exception("ERROR:[" + title + "] posting failed.")
else:
# 記事があれば更新
r = req.put(h_url + "/entry/" + key, auth=(h_id, h_api_key), data=xml)
if r.ok != True:
raise Exception("ERROR:[" + title + "] updating failed.")
return r.text
except Exception as e:
print(e)
return None(解説)
コメントにも書いているけれど、貰った content をそのまま xml にはめ込もうとすると、XML Parse エラーが発生した。そのため、Markdown形式に変換。でもそれだけでは何故か特定の記事だけダメだったので、さらに escape も噛ませてます。xml のタグ内容は全然中身を知らないです。ネットのあったのそのまんま貼りつけてます。
それともう一つポイント。新規に記事を投稿するならPOSTでいいのですが、既に存在する記事を更新する場合はPUTを使わないと 400 エラーになってしまったはずなので、そこは使い分けました。
同期する記事の本文ですが、厳密には動画リンクが反映されないとか色々ありますが、とりあえず、改行とか引用くらいは最低限同期取れてるのでよしとします。多分タグ変換の関係とかだと思うけど、知識が無いのですいません。これで勘弁。
こんな感じです。
ネットの情報見てザッと作ったのでツギハギ感がすごくてお恥ずかしい限り。でも、気が向いたときに叩くだけで、一連のバックアップ作業の流れを自動でやってくれるので助かる。ほんとは、サーバ上でスケジュール実行とかにして定期的にスクリプト動かすとさらに全自動なのだろうけれど、面倒なのでやりません。普通に手動でいい。
参考にさせていただいたサイト
最後に。こちらのサイトの情報を参考にさせていただいた。「お前のコード、ほぼこの方たちのコピペじゃん」という指摘はご勘弁・・。
▼note から記事データを取得するコードの参考
https://note.com/yokkai/n/nc9837e2fc367
▼はてなブログから記事データを取得するコードの参考
https://cartman0.hatenablog.com/entry/2017/10/20/%E3%81%AF%E3%81%A6%E3%81%AA%E3%83%96%E3%83%AD%E3%82%B0API%E3%81%A7%E5%85%A8%E8%A8%98%E4%BA%8B%E3%81%AE%E4%B8%80%E6%8B%AC%E7%B7%A8%E9%9B%86
▼はてなブログに投稿するコードの参考
https://tomowarkar.github.io/blog/posts/hatena_api/
非常に分かりやすくて助かりました。ありがとうございました。
結論
参考サイトが非常に優秀だったので、ポンコツな私でもそれほど時間かからずに実現できました。恐らく不具合とか可読性とか色々あると思いますが、いったん思い通りの動きをしたので満足です。
あまり参考になる人は居ないと思いますが、もしどなたかの助けになれば幸いです。
いつもと全然違う感じの記事でしたが、以上で。
あ、言い忘れてました。
※このソースコードにより生じた如何なる損害についても、一切の責任は負いかねますのでのであらかじめご了承ください。
この記事が気に入ったらサポートをしてみませんか?