
【競馬AI開発#9】予測時のコードを作成して競馬AIを完成させる

この【競馬AI開発】シリーズでは、競馬予想AIを作ることを通して、機械学習・データサイエンスの勉強になるコンテンツの発信や、筆者が行った実験の共有などを行っていきます。
■今回やること
今回は、実際の予測時におけるコードを作成します。
今回のコードが完成すると、出馬表からデータを取得し、機械学習による予測結果を出力することができます。
▼実行コード
from feature_engineering import PredictonFeatureCreator
pfc = PredictonFeatureCreator()
# レース直前のデータで特徴量を更新
features = pfc.create_features(race_id="202405021012")
# 予測
prediction.predict(features)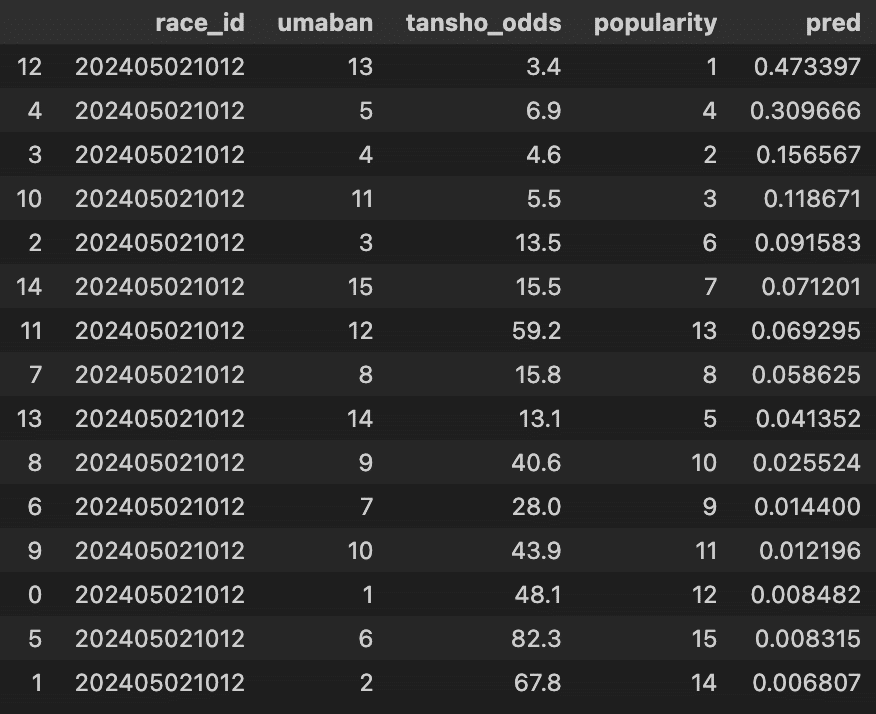
■今回のポイント
LightGBMのようなテーブル形式でデータを扱うタイプの機械学習モデルにおいては、以下のことに気をつけなければなりません。
機械学習モデルに入れるデータは、学習時と予測時で
1. 同じ列数で、全ての列の型が同じでなければならない
2. 全ての列について、入っているデータの意味が同じでなければならない
ただ、これをちゃんと実現させることが意外と難しいんです。なぜなら学習時は時間が経っている過去のデータを使うのに対して、予測時はリアルタイムで更新される現在のデータを使うからです。
実際、これから作成する競馬予想AIの場合も、学習時と異なるページからデータを取得する必要があります。
https://race.netkeiba.com/race/shutuba.html?race_id=202405030201
さらに、このデータを見ると分かるように、馬体重(増減)がまだ入っていません。
馬体重はレース当日にならないと発表されないデータなので、前日の段階で取得することができません。
一番厄介なのは「単勝オッズ」と「人気」です。これらはレース直前まで変動します。
一方学習時に使っている「単勝オッズ」と「人気」のデータは、レース後に確定したものを使っているので、厳密に一致させることは難しいです。この「確定オッズ本来使えない問題」は、将来的にも課題になってくるでしょう。
それでも少しでも学習時と予測時のデータを合わせた方が良いので、単勝オッズと人気はなるべくレース直前のデータを取得するのが理想ですが、それを実現するためには、どんな処理の流れを作れば良いでしょうか?
■予測時の処理の全体像
先に全体像を載せてしまうと、予測時には以下のように処理を設計します。
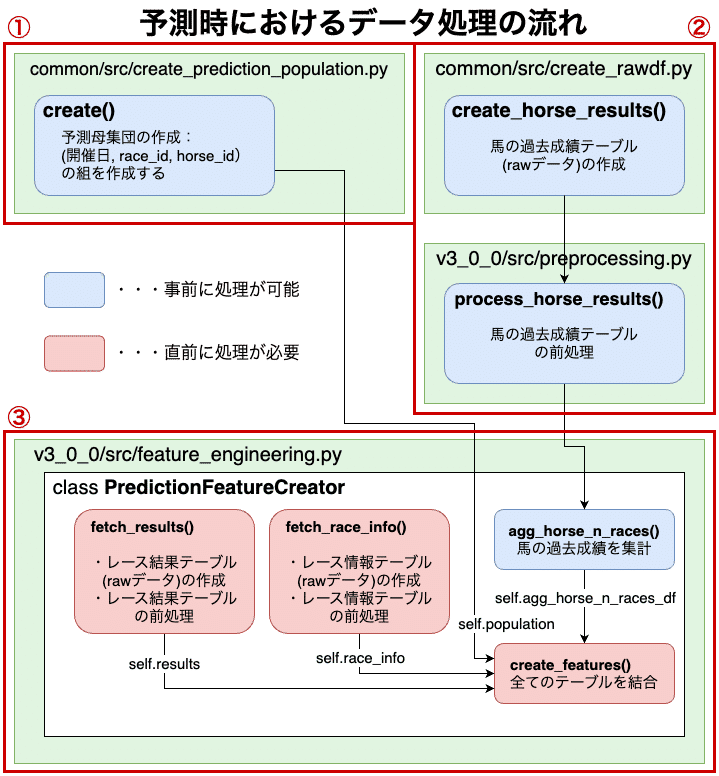
①事前に予測母集団である(開催日, race_id, horse_id)の組をまとめたテーブルを作っておく
②事前に出走する馬について過去成績テーブルのスクレイピング〜前処理まで進めておく
③レース結果テーブルとレース情報テーブルの処理については、レース出走直前に、PredictionFeatureCreatorクラス内でデータを取得して前処理を行う
ポイントとしては、事前に集計できる部分と、直前に処理しなければならない部分を切り分けてコードを書くことです。
こうすることで、最新の単勝オッズ発表〜特徴量作成までに行う処理を最小限に抑え、なるべくレース出走直前のデータを取得して機械学習モデルにインプットすることができます。
このように本シリーズでは、一度きりの「機械学習で競馬予測してみた」で終わるものではなく、本格的に運用できる競馬予想AIの作成を目指し、ソースコードを解説付きで公開しています。
ソースコードは下に進むとダウンロードできますので、解凍してお使いください。
■動画(概要編)
■筆者のプロフィール
東京大学大学院卒業後、データサイエンティストとしてWEBマーケティング調査会社でWEB上の消費者行動ログ分析などを経験。
現在は、大手IT系事業会社で、転職サイトのレコメンドシステムの開発を行っています。
ソースコード
ここから先は
¥ 1,980
この記事が気に入ったらサポートをしてみませんか?