
SQLでAUCを算出する方法

電通デジタルで機械学習エンジニアをしている今井です。
Advent Calendar 9日目となる本記事では、SQLでAUC(Area Under the Curve)を算出する方法について紹介します。
はじめに2値分類タスクでは以下のようなConfusion Matrix(混同行列)を算出します。
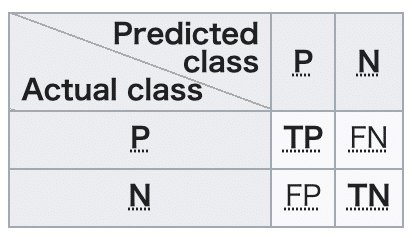
TP(True Positive, 真陽性): 正例に対して正例と予測した数
FN(False Negative, 偽陰性): 正例に対して負例と予測した数
FP(False Positive, 偽陽性): 負例に対して正例と予測した数
TN(True Negative, 真陰性): 負例に対して負例と予測した数
またこれらをもとに以下の指標も算出します。
Precision(適合率): $${\frac{\rm{TP}}{\rm{TP+FP}}}$$
Recall(再現率): $${\frac{\rm{TP}}{\rm{TP+FN}}}$$
ここで、ロジスティック回帰のように確率値を出力するモデルの場合、Confusion Matrixを算出するための閾値(予測値>=閾値ならば正例, 予測値<閾値ならば負例と分類)が必要になります。
この閾値は予測モデルの用途によって決めるのが一般的です。
例として広告配信に使用する場合は
- 配信コストを抑えてCVRを最大化したい→閾値を高く設定、Precisionを重視する
- CV想定ユーザーに網羅的に配信したい→閾値を低く設定、Recallを重視する
のようになります。
では閾値によらず作成したモデルの性能評価をするにはどうすればよいでしょうか。
機械学習の2値分類タスクでは一般的にROC曲線に対するAUCが評価指標として用いられます。
ROC曲線はTrue Positive Rate(真陽性率, $${\frac{\rm{TP}}{\rm{TP+FN}}}$$)とFalse Positive Rate(偽陽性率, $${\frac{\rm{FP}}{\rm{FP+TN}}}$$)をそれぞれ縦軸, 横軸にプロットしたグラフです。

ROC-AUCはこの曲線下の面積を計算したもので、0から1までの値をとり、1に近づくほど分類性能が高いことを意味します。
ではSQLでROC-AUCを算出する方法について紹介します。
WITH predict AS (
SELECT
y, -- 正解ラベル
p -- 予測値
FROM
テーブル名
),
stats AS (
SELECT DISTINCT
p,
SUM(y) OVER(ORDER BY p DESC) / SUM(y) OVER() AS tpr,
SUM(1 - y) OVER(ORDER BY p DESC) / SUM(1 - y) OVER() AS fpr
FROM
predict
)
, Riemann_stats AS (
SELECT
0.5 * (tpr + LAG(tpr, 1, 0) OVER(ORDER BY p DESC)) AS Riemann_sum_height,
fpr - LAG(fpr, 1, 0) OVER(ORDER BY p DESC) AS Riemann_sum_width
FROM
stats
)
SELECT
SUM(Riemann_sum_height * Riemann_sum_width) AS roc_auc
FROM
Riemann_stats中間テーブル stats で予測値に対して降順に閾値をずらしていき、True Positive Rate(TPR)とFalse Positive Rate(FPR)を閾値別に計算します。
次に Riemann_stats でTPRとFPRの前後値から各閾値区間での長方形の底辺と高さを計算します。
最後にリーマン和としてそれらの長方形の面積を足し合わせることでAUCを計算します。
参考までにPythonではsklearnを使用すると以下の数行のコードで計算できます。
from sklearn import metrics
fpr, tpr, thresholds = metrics.roc_curve(y_, p_) # y_:正解ラベル p_:予測値
metrics.auc(fpr, tpr)2値分類タスクの評価指標としてPR-AUCが使われる場面があります。
PR曲線はPrecisionとRecallをそれぞれ縦軸, 横軸にプロットしたグラフです。

観測データに正例がほとんど存在しないようないわゆる不均衡なデータの場合に、ROC-AUCよりもPR-AUCのほうが頻繁に用いられます。
これは一般的に不均衡データではマイノリティクラスよりもマジョリティクラスのほうが当てやすいため、True Negativeを評価に含まないPR曲線のほうがROC曲線よりもマイノリティクラスの誤分類に敏感に反応するという特性が好まれるためです。
PR-AUCの場合も中間テーブルを書き換えるだけで同様のSQLで算出可能です。
stats AS (
SELECT DISTINCT
p,
SUM(y) OVER(ORDER BY p DESC) / COUNT(1) OVER(ORDER BY p DESC) AS precision,
SUM(y) OVER(ORDER BY p DESC) / SUM(y) OVER() AS recall
FROM
predict
)
, Riemann_stats AS (
SELECT
0.5 * (precision + LAG(precision, 1, 0) OVER(ORDER BY p DESC)) AS Riemann_sum_height,
recall - LAG(recall, 1, 0) OVER(ORDER BY p DESC) AS Riemann_sum_width
FROM
stats
)Pythonでは以下のコードです。
precision, recall, thresholds = metrics.precision_recall_curve(y_, p_)
metrics.auc(recall, precision)UpliftModelingと呼ばれる分析手法の評価指標であるAUUC(Area Under the Uplift Curve)も同様のSQLで算出できます。
気になる方は過去記事[1][2]を一読ください。
[1] BigQueryでUplift Modeling分析
[2] Redshift MLでUplift Modeling分析