
BigQueryでUplift Modeling分析

電通デジタルで機械学習エンジニアをしている今井です。
本記事では、BigQueryでUplift Modeling分析を行うための方法について紹介します。
広告効果を上げるためには?
広告効果とは、広告に接触した場合と接触していない場合とのその後のコンバージョン(CV)の差である、と言えます。
介入が無作為に割り当てられるランダム化比較試験(randomized controlled trial, RCT)において、広告効果は平均処置効果(average treatment effect, ATE)として推定できます。
詳しくは過去記事[1]にまとめています。

Uplift Modelingは「広告施策において、その効果を上げるためには誰を広告配信対象とするべきか」を推定するための方法です。
ユーザーの特徴量を 𝐱𝑖 とすると、Uplift Scoreは下記のように算出されます。
![]()
Uplift Scoreを正しく推定できると、スコアが高いユーザー群には「介入があればCVし、介入がなければCVしない」ユーザーが多く含まれます。
反対に、スコアが低いユーザー群には「介入があってもCVしない、介入がなくてもCVする」ユーザーが多く含まれます。
従来はCVしやすいユーザー、すなわち 𝑃(𝑦𝑖=1|𝐱𝑖) が高いユーザーに広告配信を行うことで、獲得CV数を最大化していましたが、「仮に広告配信しなくてもCVしていた」ユーザーが多く含まれるという問題もありました。
そこで、CVしやすいユーザーではなくUplift Scoreが高いユーザーに広告配信をすることで、先述のUplift Scoreの特徴により、広告効果による獲得CV数の最大化を実現できるようになります。
Uplift Scoreの推定方法
本記事では、BigQuery MLを使ってUplift Scoreを推定するための方法を紹介します。
BigQuery MLの使い方は過去記事[1]にまとめています。
分析用のサンプルデータには、MineThatData E-Mail Analytics And Data Mining Challenge dataset を使用します。
このデータには、64,000名の顧客の購買実績とともに、1/3ずつ無作為に分割したユーザー群に対して実施された、男性向けメールを送る/女性向けメールを送る/メールを送らない、というそれぞれの施策とCV結果が含まれています。
ここでは、男性向けメールを送る/女性向けメールを送るをそれぞれTreatment群/Control群とし、サイト来訪の有無(visit)をCVとします。
また、モデル学習用と予測用とで無作為にデータを2分割しておきます。
#standardSQL
SELECT
*,
CASE
WHEN unique_id >= 0.50 THEN "TRAIN"
ELSE "TEST"
END AS assign
FROM (
SELECT
*,
RAND() AS unique_id,
CASE segment
WHEN "Mens E-Mail" THEN 1
WHEN "Womens E-Mail" THEN 0
END AS w,
visit AS y
FROM
`project_id.dataset_id.MineThatData_orig`
WHERE
segment IN ("Mens E-Mail", "Womens E-Mail")
)
Uplift Modelingでは、
・ Treatment群/Control群とで2つの予測モデルを作成する方法(以下、Two-Model Approach)
・ class variable transformationという手法で1つの予測モデルだけを作成する方法(以下、One-Model Approach)
が広く使われています。
Two-Model Approachでは、
![]()
として推定されます。
#standardSQL
CREATE OR REPLACE MODEL
`dataset_id.model_name`
OPTIONS(
MODEL_TYPE="logistic_reg",
input_label_cols=["y"],
max_iterations=50,
early_stop=false,
l1_reg=0.01
) AS
SELECT
recency,
history,
mens,
womens,
zip_code,
newbie,
channel,
y,
FROM
`project_id.dataset_id.MineThatData`
WHERE
w = 1 -- Treatment群での予測モデル学習
-- Control群での予測モデル学習の場合は、w=0とする
AND assign = "TRAIN"#standardSQL
WITH predicts_treatment AS (
SELECT
unique_id,
y,
w,
predicted_y_probs[OFFSET(0)].prob AS p_treatment
FROM
ML.PREDICT(MODEL `dataset_id.model_name_treatment`, (
SELECT
*
FROM
`project_id.dataset_id.MineThatData`
WHERE
assign = "TEST"
)
)
), predicts_control AS (
SELECT
unique_id,
predicted_y_probs[OFFSET(0)].prob AS p_control
FROM
ML.PREDICT(MODEL `dataset_id.model_name_control`, (
SELECT
*
FROM
`project_id.dataset_id.MineThatData`
WHERE
assign = "TEST"
)
)
)
SELECT
y,
w,
p_treatment - p_control AS uplift_score
FROM
predicts_treatment
LEFT JOIN
predicts_control
USING (unique_id)一方、One-Model Approachでは、
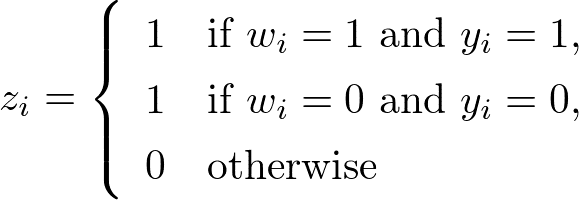
を目的変数とする予測モデルを作成することで、
![]()
として推定されます。
詳しくは参考文献[2]を一読ください。
#standardSQL
CREATE OR REPLACE MODEL
`dataset_id.model_name`
OPTIONS(
MODEL_TYPE="logistic_reg",
input_label_cols=["z"],
max_iterations=50,
early_stop=false,
l1_reg=0.01
) AS
SELECT
recency,
history,
mens,
womens,
zip_code,
newbie,
channel,
CASE
WHEN w = 1 AND y = 1 THEN 1
WHEN w = 0 AND y = 0 THEN 1
ELSE 0
END AS z
FROM
`project_id.dataset_id.MineThatData`
WHERE
assign = "TRAIN"#standardSQL
WITH predicts AS (
SELECT
unique_id,
y,
w,
predicted_z_probs[OFFSET(0)].prob AS p
FROM
ML.PREDICT(MODEL `dataset_id.model_name`, (
SELECT
*,
CASE
WHEN w = 1 AND y = 1 THEN 1
WHEN w = 0 AND y = 0 THEN 1
ELSE 0
END AS z
FROM
`project_id.dataset_id.MineThatData`
WHERE
assign = "TEST"
)
)
)
SELECT
y,
w,
2 * p - 1 AS uplift_score
FROM
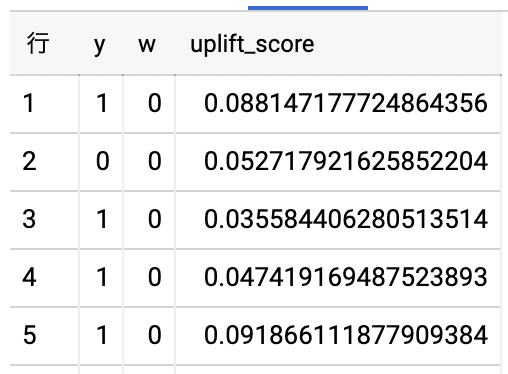
predicts実行すると下記のような結果になります。
Uplift Modelingの評価
Two-Model ApproachとOne-Model ApproachとでそれぞれUplift Scoreを推定しましたが、どちらを使うべきでしょうか?
Uplift Modelingの評価にはAUUC(area under the uplift curve)やQini係数を使用するのが一般的です。
AUUCとQini係数の算出には、Uplift Scoreが閾値 𝜙 以上/未満のユーザーに対して介入/非介入行為をした場合にどれぐらいCV件数が増えるかを表すUplift曲線とQini曲線という指標を使います。
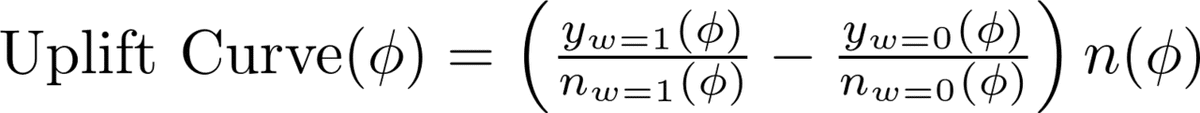

𝑦(𝜙),𝑛(𝜙) はそれぞれ Uplift Score ≥𝜙 でのCV数, ユーザー数を表します。
これらは Uplift Score ≥𝜙 での層別化マッチングと同義であり、Uplift曲線はATE, Qini曲線はATT(average treatment effect on the treated)を表します。
#standardSQL
WITH stats AS (
SELECT DISTINCT
uplift_score,
COUNT(1) OVER desc_uplift_score AS index,
SUM(w) OVER desc_uplift_score AS n_t,
SUM((1 - w)) OVER desc_uplift_score AS n_c,
SUM(y * w) OVER desc_uplift_score AS y_t,
SUM(y * (1 - w)) OVER desc_uplift_score AS y_c
FROM
`project_id.dataset_id.uplift_score`
WINDOW desc_uplift_score AS (ORDER BY uplift_score DESC)
)
SELECT
uplift_score,
index / MAX(index) OVER() AS proportion,
CASE
WHEN n_t > 0 AND n_c > 0 THEN (y_t / n_t - y_c / n_c) * (n_t + n_c)
WHEN n_t > 0 AND n_c = 0 THEN y_t
WHEN n_t = 0 AND n_c > 0 THEN - y_c
END AS uplift_curve,
CASE
WHEN n_t > 0 AND n_c > 0 THEN y_t - y_c * n_t / n_c
WHEN n_t > 0 AND n_c = 0 THEN y_t
WHEN n_t = 0 AND n_c > 0 THEN 0
END AS qini_curve,
(MAX(y_t) OVER() / MAX(n_t) OVER() - MAX(y_c) OVER() / MAX(n_c) OVER()) * index AS baseline_uplift,
(MAX(y_t) OVER() - MAX(y_c) OVER() * MAX(n_t) OVER() / MAX(n_c) OVER()) * index / MAX(index) OVER() AS baseline_qini
FROM
stats
ここで、proportion はUplift Scoreを降順に並べて閾値をずらしていったときの百分率です。
また、baseline_uplift は(0,0)と

とを、baseline_qini は
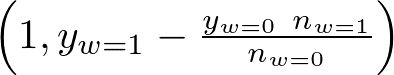
とを結ぶ直線で、無作為な介入行為を表します。
AUUC/Qini係数は、Uplift曲線/Qini曲線下の面積からこの直線下の面積を差し引いた値であり、これらが高いほどUplift Modelingの性能が高いことを意味します。
#standardSQL
WITH Riemann_stats AS (
SELECT
proportion - LAG(proportion, 1, 0) OVER asc_proportion AS Riemann_sum_width,
uplift_curve + LAG(uplift_curve, 1, 0) OVER asc_proportion AS Riemann_sum_height_uplift_curve,
baseline_uplift + LAG(baseline_uplift, 1, 0) OVER asc_proportion AS Riemann_sum_height_baseline_uplift,
qini_curve + LAG(qini_curve, 1, 0) OVER asc_proportion AS Riemann_sum_height_qini_curve,
baseline_qini + LAG(baseline_qini, 1, 0) OVER asc_proportion AS Riemann_sum_height_baseline_qini
FROM
`project_id.dataset_id.curve`
WINDOW asc_proportion AS (ORDER BY proportion ASC)
), auc AS (
SELECT
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_uplift_curve) AS auc_uplift_curve,
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_baseline_uplift) AS auc_baseline_uplift,
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_qini_curve) AS auc_qini_curve,
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_baseline_qini) AS auc_baseline_qini
FROM
Riemann_stats
)
SELECT
auc_uplift_curve - auc_baseline_uplift AS auuc,
auc_qini_curve - auc_baseline_qini AS qini_coefficient
FROM
aucAUUCは
・ Two-Model Approach: 151.32
・ One-Model Approach: 148.06
Qini係数は
・ Two-Model Approach: 75.74
・ One-Model Approach: 74.87
となり、Two-Model Approachのほうがモデル性能が高いことになります。
下記を実行すると、Uplift Modelingの結果をMatplotlibで可視化できます。
import matplotlib.pyplot as plt
from google.cloud import bigquery
client = bigquery.Client()
sql = """
SELECT
proportion,
uplift_curve,
qini_curve,
baseline_uplift,
baseline_qini
FROM
`project_id.dataset_id.curve`
"""
df_curve = client.query(sql).to_dataframe()
sql = """
SELECT
auuc,
qini_coefficient
FROM
`project_id.dataset_id.evaluate`
"""
df_evaluate = client.query(sql).to_dataframe()
fig, (ax_uplift, ax_qini) = plt.subplots(ncols=2, figsize=(10,4))
ax_uplift.plot(df_curve.proportion, df_curve.uplift_curve, label='Uplift curve')
ax_uplift.plot(df_curve.proportion, df_curve.baseline_uplift, label='baseline')
ax_uplift.set_xlabel('percentage of total number')
ax_uplift.set_ylabel('cumulative uplift')
ax_uplift.set_title('AUUC: {}'.format(df_evaluate.auuc[0]))
ax_uplift.legend(loc='lower right', frameon=False)
ax_qini.plot(df_curve.proportion, df_curve.qini_curve, label='Qini curve')
ax_qini.plot(df_curve.proportion, df_curve.baseline_qini, label='baseline')
ax_qini.set_xlabel('percentage of total number')
ax_qini.set_ylabel('cumulative uplift')
ax_qini.set_title('Qini coefficient: {}'.format(df_evaluate.qini_coefficient[0]))
ax_qini.legend(loc='lower right', frameon=False)
fig.show()
最後に、Qini曲線と無作為介入との差(conversion_lift)が大きくなる場合の閾値で介入/非介入のユーザー群を決定します。
#standardSQL
SELECT
uplift_score,
proportion,
qini_curve - baseline_qini AS conversion_lift
FROM
`project_id.dataset_id.curve`
ORDER BY conversion_lift DESC
上記の結果から、Uplift Score ≥0.02 である上位59.4%のユーザー群には男性向けメールを、それ以外には女性向けメールを送ることでメール配信の効果を上げることが期待できます(なお、簡易化のためUplift Scoreを小数第2位に四捨五入しています)。
おわりに
本記事では、広告効果を最適化するためのUplift Modeling分析について紹介しました。
最後に余談ですが、
BigQuery MLの新機能として、2020年6月にXGBoostとDeep Neural Network (DNN)がリリースされました。
これまでは線形モデルしか使用できませんでしたが、このアップデートによりBigQuery MLがデータサイエンティストにとっての”銀の弾丸”となりうるのではないでしょうか。
参考文献
[1] BigQueryで傾向スコア分析
[2] Jaskowski+, Uplift modeling for clinical trial data, 2012
[3] Radcliffe+, Using control groups to target on predicted lift: Building and assessing uplift model, 2007
[4] 有賀康顕, 中山心太, 西林孝「仕事で始める機械学習」