
Redshift MLでUplift Modeling分析

電通デジタルで機械学習エンジニアをしている今井です。
本記事では、Amazon Redshift MLでUplift Modeling分析を行うための方法について紹介します。
Amazon Redshift MLについて
2020年12月にAmazon Redshift MLのプレビュー提供が開始されました。
(端的に表すとGoogleが提供するBigQuery MLのAmazon Redshift版です)
執筆時点ではSageMaker Autopilotによる回帰/二値分類/多値分類と、XGBoost(SageMakerビルトインモデル版)による回帰/二値分類/多値分類/ランキング学習が使用可能です。
Redshift MLを使うための環境構築についてはこちらのAWS記事を参考にしてください。
まずはモデルを作成するためのスキーマをデータベース内に作成します。
CREATE SCHEMA schema_name;AutopilotとXGBoostに共通するモデル学習のSQLクエリ(train.sql)は以下です。
CREATE MODEL schema_name.model_name
FROM { table_name | ( select_statement ) }
TARGET column_name
FUNCTION function_name
IAM_ROLE 'iam_role_arn'
各モデルでの設定値(以下に記載)
SETTINGS ( e.g. S3_BUCKET 'bucket' );Autopilotを使用する場合は train.sql に
AUTO ON
PROBLEM_TYPE { REGRESSION | BINARY_CLASSIFICATION | MULTICLASS_CLASSIFICATION }
OBJECTIVE { 'MSE' | 'Accuracy' | 'F1' | 'F1_Macro' | 'AUC' }XGBoostを使用する場合は
AUTO OFF
MODEL_TYPE XGBOOST
OBJECTIVE { 'reg:squarederror' | 'reg:squaredlogerror' | 'reg:logistic' |
'reg:pseudohubererror' | 'binary:logistic' | 'binary:hinge' |
'multi:softmax' | 'rank:pairwise' | 'rank:ndcg' }
PREPROCESSORS 'string'
HYPERPARAMETERS DEFAULT EXCEPT ( Key 'value' )を追記してください。
Autopilotでは PROBLEM_TYPE 、XGBoostの場合は OBJECTIVE でモデルタイプを設定します。
詳しくはRedshift MLのドキュメントを一読ください。
上記を実行するとSageMakerのトレーニングジョブとしてモデル学習が行われます。
CREATE MODEL が完了後にモデルの詳細について確認できます。
SHOW MODEL schema_name.model_name;以下で予測結果を出力します。
SELECT schema_name.function_name( 説明変数一覧 )
FROM { table_name | ( select_statement ) }
;なお執筆時点ではRedshift MLのAutopilotの二値分類/多値分類は予測ラベルのみ出力する仕様のためご注意ください。
Autopilotで予測確率値を出力したい場合はRedshift MLではなくSageMaker Python SDKを使用しましょう(詳しくは過去記事[1]にまとめています)。
ここで検証時に躓いた事象を共有します。
Redshiftは「クエリエディタ」と呼ばれるマネジメントコンソールから直接SQLクエリを実行するためのブラウザ内インターフェイスを提供しています。
しかしながらクエリエディタではクエリ実行時間に制限があり、Autopilotを選択するとパラメータ調整ジョブなどで実行時間が長くなるため、学習に用いるデータ量を問わず下記のようなエラーとなってしまいました。

そこで、Autopilotでのモデル学習についてはクエリエディタの代替としてRedshift Data APIを使用することで解決しました。
なお、Autopilotでの予測やXGBoostでのモデル学習/予測についてはクエリエディタでも問題なく動きました。
(2/18追記)クエリエディタのタイムアウト時間が10分から24時間に延長されました
Redshift MLでUplift Modeling分析
ここからはRedshift MLのAutopilotを使用したUplift Modeling分析について紹介します。
Uplift Modeling分析は過去記事[2]にまとめているため一読ください。
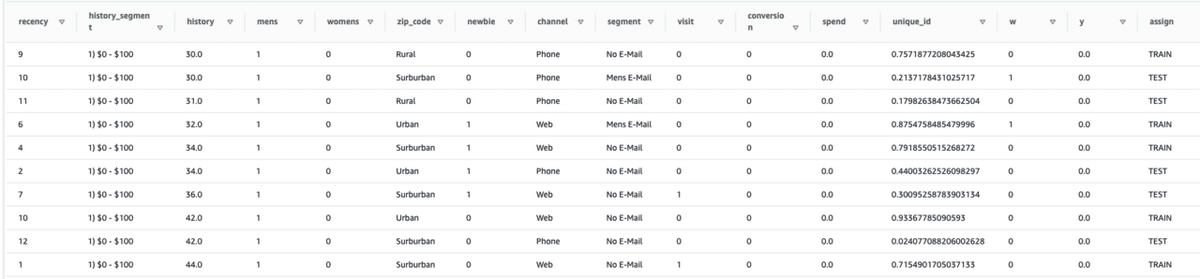
過去記事[2]と同様にMineThatData E-Mail Analytics And Data Mining Challenge datasetをサンプルデータとして使用しますが、上述の通りAutopilotの二値分類での予測確率値が出力できない仕様のため、今回は男性向けメールを送る(Treatment群)/メールを送らない(Control群)という介入行為に対するその後の購買金額(spend)をCVとしてUplift Scoreを推定します。
SELECT
*,
CASE
WHEN unique_id >= 0.50 THEN 'TRAIN'
ELSE 'TEST'
END AS assign
FROM (
SELECT
*,
RANDOM() AS unique_id,
CASE segment
WHEN 'Mens E-Mail' THEN 1
WHEN 'No E-Mail' THEN 0
END AS w,
spend AS y
FROM
schema_name.MineThatData_orig
WHERE
segment IN ('Mens E-Mail', 'No E-Mail')
);
まずはTreatment群(w=1)とControl群(w=0)で購買金額を目的変数とする回帰モデルを作成します。
下記はTreatment群に対する回帰モデル学習のSQLクエリです。
CREATE MODEL schema_name.model_name_treatment
FROM (
SELECT
recency,
history,
mens,
womens,
zip_code,
newbie,
channel,
y
FROM
schema_name.MineThatData
WHERE
w = 1 AND assign = 'TRAIN'
)
TARGET y
FUNCTION function_name_treatment
IAM_ROLE 'iam_role_arn'
AUTO ON
PROBLEM_TYPE REGRESSION
OBJECTIVE 'MSE'
SETTINGS (
S3_BUCKET 'bucket'
);次に、それぞれのモデルによる予測値からUplift Scoreを推定します。
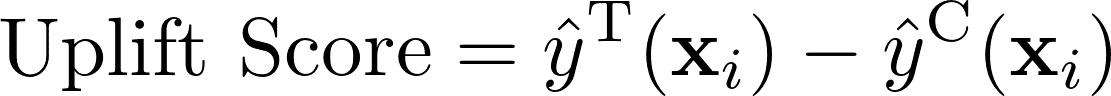
WITH predicts_treatment AS (
SELECT
unique_id,
y,
w,
schema_name.function_name_treatment(
recency,
history,
mens,
womens,
zip_code,
newbie,
channel
) AS y_treatment
FROM
schema_name.MineThatData
WHERE
assign = 'TEST'
), predicts_control AS (
SELECT
unique_id,
schema_name.function_name_control(
recency,
history,
mens,
womens,
zip_code,
newbie,
channel
) AS y_control
FROM
schema_name.MineThatData
WHERE
assign = 'TEST'
)
SELECT
y,
w,
y_treatment - y_control AS uplift_score
FROM
predicts_treatment
LEFT JOIN
predicts_control
USING (unique_id)
;
次にAUUCとQini係数を使用してUplift Modelingを評価します。
下記でUplift/Qini曲線および無作為な介入行為を表す直線(baseline)を推定します。
WITH stats AS (
SELECT DISTINCT
uplift_score,
COUNT(1) OVER(ORDER BY uplift_score DESC rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS index,
SUM(w) OVER(ORDER BY uplift_score DESC rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS n_t,
SUM((1 - w)) OVER(ORDER BY uplift_score DESC rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS n_c,
SUM(y * w) OVER(ORDER BY uplift_score DESC rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS y_t,
SUM(y * (1 - w)) OVER(ORDER BY uplift_score DESC rows BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS y_c
FROM
schema_name.uplift_score
), sort AS (
SELECT
*,
RANK() OVER(PARTITION BY uplift_score ORDER BY index DESC) AS r
FROM
stats
)
SELECT
uplift_score,
CAST(index AS FLOAT) / MAX(index) OVER() AS proportion,
CASE
WHEN n_t > 0 AND n_c > 0 THEN (y_t / n_t - y_c / n_c) * (n_t + n_c)
WHEN n_t > 0 AND n_c = 0 THEN y_t
WHEN n_t = 0 AND n_c > 0 THEN - y_c
END AS uplift_curve,
CASE
WHEN n_t > 0 AND n_c > 0 THEN y_t - y_c * CAST(n_t AS FLOAT) / n_c
WHEN n_t > 0 AND n_c = 0 THEN y_t
WHEN n_t = 0 AND n_c > 0 THEN 0
END AS qini_curve,
(MAX(y_t) OVER() / MAX(n_t) OVER() - MAX(y_c) OVER() / MAX(n_c) OVER()) * index AS baseline_uplift,
(MAX(y_t) OVER() - MAX(y_c) OVER() * MAX(n_t) OVER() / MAX(n_c) OVER()) * index / MAX(index) OVER() AS baseline_qini
FROM
sort
WHERE
r = 1
;
これらはUplift Score ≥ 閾値での層別化マッチングと同義であり、Uplift曲線はATE(average treatment effect), Qini曲線はATT(average treatment effect on the treated)を表します。
AUUC/Qini係数は、Uplift曲線/Qini曲線下の面積からbaselineの面積を差し引いた値であり、これらが高いほどUplift Modelingの性能が高いことを意味します。
WITH Riemann_stats AS (
SELECT
proportion - LAG(proportion, 1) OVER(ORDER BY proportion ASC) AS Riemann_sum_width,
uplift_curve + LAG(uplift_curve, 1) OVER(ORDER BY proportion ASC) AS Riemann_sum_height_uplift_curve,
baseline_uplift + LAG(baseline_uplift, 1) OVER(ORDER BY proportion ASC) AS Riemann_sum_height_baseline_uplift,
qini_curve + LAG(qini_curve, 1) OVER(ORDER BY proportion ASC) AS Riemann_sum_height_qini_curve,
baseline_qini + LAG(baseline_qini, 1) OVER(ORDER BY proportion ASC) AS Riemann_sum_height_baseline_qini
FROM
schema_name.curve
), auc AS (
SELECT
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_uplift_curve) AS auc_uplift_curve,
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_baseline_uplift) AS auc_baseline_uplift,
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_qini_curve) AS auc_qini_curve,
0.5 * SUM(Riemann_sum_width * Riemann_sum_height_baseline_qini) AS auc_baseline_qini
FROM
Riemann_stats
)
SELECT
auc_uplift_curve - auc_baseline_uplift AS auuc,
auc_qini_curve - auc_baseline_qini AS qini_coefficient
FROM
auc
;
最後に、Qini曲線とbaselineとの差(conversion_lift)が大きくなる場合の閾値で介入/非介入のユーザー群を決定します。
SELECT
uplift_score,
proportion,
qini_curve - baseline_qini AS conversion_lift
FROM
schema_name.curve
ORDER BY conversion_lift DESC
;
上記の結果から、Uplift Score ≥0.5 である上位約20%のユーザー群に男性向けメールを送ることで1400ドル相当の売上改善が期待できます(なお、簡易化のためUplift Scoreを小数第2位に四捨五入しています)。
参考文献
[1] SageMaker AutopilotをSDKを使って実行する
[2] BigQueryでUplift Modeling分析