
囲碁界を変えた最強AI・AlphaGoから学ぶ深層強化学習

こんにちは、株式会社D4cプレミアムのデータサイエンティスト、新卒1年目の萩原です。
突然ですが、私は中学の頃まで囲碁のプロ棋士を目指しておりました。データサイエンスという分野に興味を持ったのも、AIがトッププロを破ったことに衝撃を受けたことが大きな要因としてあります。
昨今は囲碁・将棋をテレビや配信で観戦すると、必ずと言っていいほどAIによる評価値や次の予想手が画面に表示されています。ここで使われているAIには「深層学習」や「強化学習」といった、機械学習を知る上で非常に重要な手法が取り入れられています。囲碁でのAIはAlphaGoというプログラムから急速に進化し、深層学習・強化学習がいかに強力であるかを知らしめました。このことはAIの進化例として大学で紹介されるほど、大きなニュースになりました。現在はそのパターン認識のアルゴリズムを応用して、量子力学の問題や、今注目を浴びている最新の生成AIにも適用されています。
そこでこの記事では、AlphaGoというAIは一体何をしているのか、どういった経緯で生まれたのかについて、掘り下げていきたいと思います。
この記事のターゲット
・機械学習に興味があり、深層学習や強化学習のゲーム分野での活用例を知りたい方
・AlphaGoについて聞いたことはあるが、何をしているかは知らない方
初めて人間を超えた囲碁AI ”AlphaGo”
ボードゲームとAIは以前から密接な関係にあり、チェスや将棋ではAIが早い段階で人間を上回っていました。一方で囲碁はプレイヤーが取れる選択肢が多いため、AIにとって最難関と言える立ち位置にあったのです。
そんな中、2016年、Google DeepMind社により開発された囲碁AIのAlphaGoと、当時のトップ棋士の1人である韓国のイ・セドル九段との5局勝負(勝敗にかかわらず5回対局する)が企画されました。Googleが生み出した最強AIの性能を確かめるために行われた企画で、賞金は100万ドルにもなる一大イベントでした。
AlphaGoは従来のAIから急激な進歩を遂げ、このイベントの前年には中国のプロ棋士をハンデなしで破っていました。とはいえこの時点ではまだ粗い打ち方が目立ち、またかつての脆いAIの印象もあって、大方の観衆はイ・セドル九段が圧倒するものと予想していました。
しかし蓋を開けてみれば、AlphaGoは圧倒的な力を見せ、イ・セドル九段相手に4対1で勝利。特に3局目の内容が圧巻で、誰もがAIが人間を超えたことを認めざるを得ない状況となりました。
イベント序盤では「AlphaGoはイ・セドル九段には勝てても自分には勝てない」と話していた当時の世界ランキング一位の中国棋士、柯潔(カケツ)九段も、対戦が進んでいくと「自分がAIに勝てる確率は5%以下」という評価を述べるほどの内容でした。
その後さらに進化したAlphaGoはインターネット対局で正体を伏せ、Masterという名前で出没しては、プロ棋士相手に60戦無敗を記録、囲碁界隈を震撼させました。さらに、2017年には柯潔九段を相手に三連勝と、イ・セドル九段と戦った時からさらに次元が違う強さを見せつけ、対人イベントからは引退することになりました。これほどの進化を遂げたAlphaGoの仕組みはどうなっているのか、過去のAIから順を追って見ていきましょう。
AlphaGo以前のAI
以前の囲碁AIは、人力で設定した評価関数により各盤面を評価し、その評価値が最も高くなる手を選択する、といった手法で作られていました。しかしこの評価関数の定義が大きな関門でした。形勢判断のための厳密なルールを決めるのは、様々な要素が評価に関与する囲碁ではプロでも難しいのです。局面が少し複雑になると、あらぬ方向に石が行ってしまうことも多く、当時の実力はアマチュア下位~中位レベルでした。
その後使われだしたのが、モンテカルロ木探索をメインとしたアルゴリズムでした。これは今のAlphaGoの基となっています。モンテカルロ木探索は、モンテカルロ法と呼ばれるシミュレーションを応用した手法です。少々難しいので、まず(原始)モンテカルロ法について以下の図を用いて解説します。
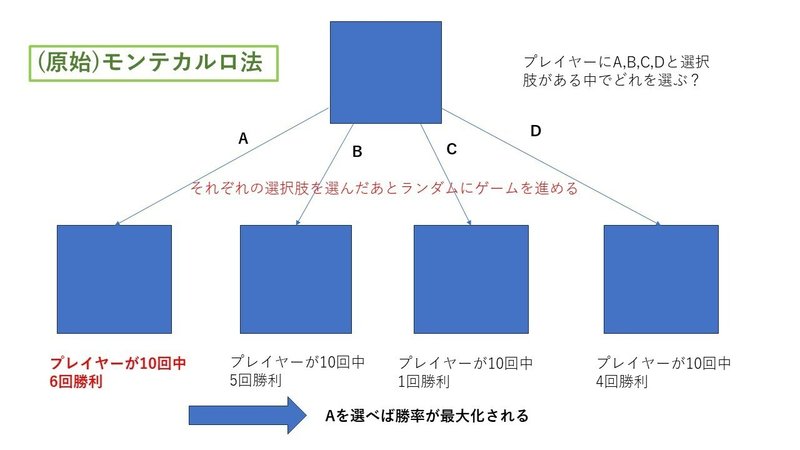
問題を簡単にするために、ある盤面から選択肢が4つだけある状況を考えます。AIには、A、B、C、Dの選択肢それぞれについて、ゲームが終わるまでランダムに試合を進めてもらいます。それを繰り返し、それぞれの選択肢に対して勝率が出せるようにします。その勝率が最も高い手を選べば、勝ちに繋がりやすい手を選択できる、という考え方です。
この考え方を発展させて生まれたのがモンテカルロ木探索です。原始モンテカルロ法で考慮するのは次の自分の手のみでしたが、実際の試合では相手がどう返してくるかを考えることも重要です。モンテカルロ木探索では以下の図のように、数手先まで判断材料に入れます。

最初は原始モンテカルロ法によってそれぞれの手に勝率を付けていくのですが、均等ではなく勝率が高い手を優先的に繰り返します。繰り返し(探索)回数が一定を超えた場合、次はその盤面から相手がどう打ってきそうかを考えるために再度シミュレーションします。こうして勝率が高くなりそうな展開を優先でツリー状に探索を広げていき、A、B、C、Dのどの手について最も探索を行ったかによって実際に打つ手を決めます。探索回数が多いということは、その手が勝ちに繋がりやすいことを表すからです。
このアルゴリズムが優秀な点は、探索の際に勝率が高いと思われる手を重点的に読み、逆の場合は早々に切り上げて時間を短縮できることにあります。上の例でいえば、選択肢Cは明らかに勝率が低そうであったため、途中で探索を止めており、A、Bの探索により多くの労力を割いています。現実には選択肢が非常に多くあるため、こういった探索時間の短縮は必要不可欠になります。
一方で問題は、モンテカルロ法によって勝率を知るためには決着がつくまで盤面を進める必要があり、盤面が広く決着まで手数がかかる19路盤(19×19)では終局までたどり着くのが大変ということです。こういった課題もあり、9路盤(9×9)ではプロに匹敵するほどの実力がありましたが、19路盤ではまだまだアマ有段~高段者程度に収まっていました。
AlphaGoのアルゴリズム
その後開発されたAlphaGoは、モンテカルロ木探索に加えて、深層学習と強化学習を組み合わせることにより、以前のAIが抱えていた問題点をいくつも解決することに成功しました。ここからはAlphaGoがどのようにして囲碁を学習し、実際の対戦で打つ手を決めているかを解説します。
まず、AlphaGoに必要な機能を備えてもらうための学習フェーズについて、以下の図に沿って説明します。

最初に、AlphaGoにはあらかじめ用意したプロ棋士の棋譜(対戦の記録)を使って、現状の盤面から次に打つ手の候補手を出す「次の一手予測ネットワーク」を作ってもらいます。この予測ネットワークは画像認識の考え方を用いた深層学習によって作られ、これでAlphaGoは一応ゲームがプレイできるようになります。
その後、AlphaGoに自己対戦を繰り返してもらい、どういった盤面がどれくらい勝ちやすいかを判断する「評価ネットワーク」を構築させます。この自己対戦を繰り返すことが強化学習にあたり、繰り返すごとに評価ネットワークと先ほど作った次の一手予測ネットワークの精度を上げていきます。これで事前準備は完了です。
AlphaGoが実戦でどういった流れで次の手を選んでいるかはかなり複雑になりますので、また先ほどの例で図を使って説明します。

今回も基本はモンテカルロ木探索で考えていくのですが、先ほど用意した二つのネットワークによって、より効率的な探索が可能になります。
まず、先ほどと同じくプレイヤー側に選択肢A、B、C、Dがある盤面からスタートします。AlphaGoは次の一手を、次の一手予測ネットワークによってある程度絞り込みます。今回ネットワークは選択肢A、B、Dを予測し、Cは除外しました。
次に、予測された候補手すべてに対して評価ネットワークによる評価値を算出します。ここで評価値が高い候補手に関しては、予測の精度を高めるため重点的に探索します。今回は選択肢Aについて特に重点的に探索していくことになります。
相手の手について考える際も、同様に次の一手予測ネットワークによる絞り込みと評価ネットワークによる評価値の割り当てを行います。相手側の手番ではプレイヤー側の勝率が低くなるような手を優先して探索します。今回の例では、選択肢Aを選んだあとの相手の手番では、予測された候補手A1、A2、A3のうちでA1が最もプレイヤー側の勝率が低くなるため、この手から重点的に探索していくことになります。このように双方自分に比較的有利な展開になるような手を選んで探索していき、モンテカルロ木探索の考え方を用いて、探索回数が最も多い手を実際に選択します。
単純なモンテカルロ木探索と比べて大きく違うのが、ゲーム途中の盤面評価をモンテカルロ法ではなく、評価ネットワークで行えるようになった点です。盤面を評価する際にゲームをランダムに最後まで進めるという方法は、手数が長い囲碁においてはかなり苦しい手段でした。しかしそれが評価ネットワークに置き換わったことで、算出される評価値の精度が大幅に向上しました。こうしてAlphaGoは、それまでのAIと比べて飛躍的な進歩を遂げることになったのです。
AlphaGoが台頭してから、人間の価値観では思いつかない手が数多く披露され、AI定石と呼ばれるものがいくつも誕生しました。反対に評価値が可視化されたことで、これまで当たり前と思われていた多くの定石が打たれなくなりました。人間がAIから学ぶ時代に入ったことにより、囲碁界全体のレベルは上がったといえます。
一方で、AlphaGoに敗れたイ・セドル九段は、2019年に「たとえ自分がナンバーワンになったとしても勝てない相手がいる」と言い残してプロを引退しました。AIが囲碁界に与えた影響は、その捉え方によってプラスにもマイナスにも非常に大きなものとなったのです。
最後に
その後AlphaGoはAlphaZeroという名前でさらに研究が進み、元々は次の一手予測にプロ棋士の対局データを使っていたところを、最初から自己学習のみで成長していくようになりました。そのため囲碁以外のゲームにも応用でき、将棋やチェスに対しても半日程度で過去のAIを超えることに成功しています。もちろん囲碁での学習性能も健在で、学習13日でその前のバージョンに勝ち越す力を見せました。
現在、AlphaZeroを使った研究はボードゲームという枠すら超え、制御理論や量子アルゴリズムにおける初期状態の最適化などに応用されています。人間が前もって学習データを用意する必要がなくなったことで、活用の幅は大きく広がりました。そして2023年12月6日にGoogleは、大規模言語モデルにAlphaGo, AlphaZeroタイプの深層強化学習システムを組み合わせた新たな生成AI「Gemini」を発表しました。AlphaGo VS イ・セドル九段の対局イベントから7年半の年月が経ちましたが、あの時とは違った形で再び世界中の注目を集めることになるかもしれません。
(書き手:萩原)
少しでもお役に立てましたら、記事の下の♡を押していただく&フォローいただけますと励みになります!
▼採用情報
▼コーポレートサイト