
【就活余裕】 玉手箱の空欄予測問題を回帰分析で解く

※本投稿は就職試験で使われる玉手箱の空欄予測問題を通して、文字認識や回帰分析について学ぶことを目的としており、選考における「不正」を助長するものではございません。タイトルは釣りです。
こんばんは、二階からラグランジュです。
就活で使われるwebテスト、難しいの多いですよね。
その中でも、玉手箱の空欄予測問題、苦手な方多いんじゃないでしょうか?
こんな問題ですね。

一般的には、与えられた数字から法則性を見つけ出して、空欄に入るものを予測するという流れで解きます。
しかし、思いませんか?
「与えられた数字から法則性を見出して予測」って、まさに統計解析だとか機械学習が得意としていることですよね。
今回は、最もシンプルな手法である単回帰分析を用いて、この問題を解いてみたいと思います!
データセットを準備する
Pythonを使って解いていきたいと思います。
ということで、データを用意したいのですが、少し困ったことがあります。
本番の玉手箱って、コピペが出来なくなっているんですよね(本番で使うことを想定しているわけではありませんよ)。
そこで、方法としては二つあります!
①力づくで手入力する
②OCR(光学文字認識)を使う
分量にもよりますが、正直どちらでやっても大体同じスピードになります。
一応、②のやり方を中心にご紹介することにします!
OCRを用いて、画像としての表をテキストデータに変換して、Pythonのデータフレームに読み込めるようにします。
光学文字認識(こうがくもじにんしき、英: Optical character recognition)は、活字、手書きテキストの画像を文字コードの列に変換するソフトウェアである。画像はイメージスキャナーや写真で取り込まれた文書、風景写真(風景内の看板の文字など)、画像内の字幕(テレビ放送画像内など)が使われる[1]。一般にOCRと略記される。
OCRを利用するためには色々なアプリケーションが考えられますが、今回はMicrosoft One Driveのものを利用します。
まずは、問題のスクショを撮ってPDFファイルに変換し、One Drive上にアップロードします。
こちらを開くとこんな感じですが、この時点ではまだ画像データですのでPythonで読み込むことはできません。
左上の「開く」をクリックして、
「デスクトップアプリで開く」をクリックします。

そうすると、こんなバナーが出てきて、「変換」をクリックすると、

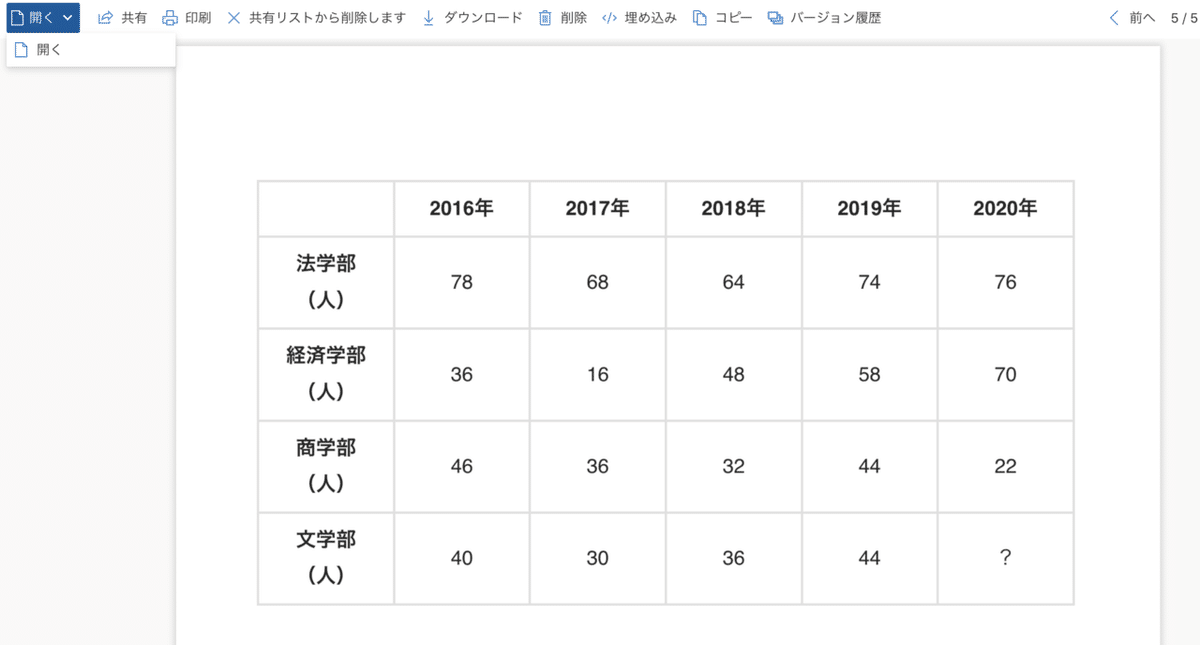
こんな感じで、編集可能なテキストの表に変換されました。

ただし、何箇所か読み取りに失敗しているものがありますね。
ここは手動で埋めてやりましょう。行名・列名は面倒なので削除します。

この表をPDF形式で再度保存し、Pythonで読み込んでやります。
Camerotというライブラリを利用します。PDFからテキストベースのテーブルデータを抜き出し、pandasのDataFrame形式で読み取ることができます。
import pandas as pd
from camelot import read_pdf
dfs = read_pdf("tamatebako.pdf", pages='1-end', split_text=True, strip_text='\n')
df_ex = dfs[0].df成功です。
※①のやり方では、このDataFrameを手打ちして作る形になります。
ここから先の流れは共通です。
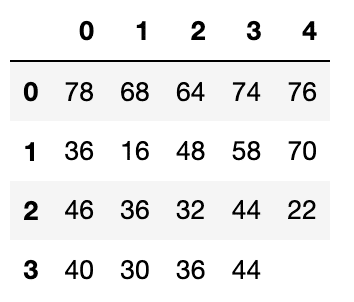
回帰分析で解く
このDataFrameの空白箇所、つまり2020年の文学部入学者数を、残りの情報から予測します。
ここで回帰分析の登場です!
以下の式をイメージしてみてください。
$$
学生数_{文学部}=\alpha_1\times学生数_{法学部}+\alpha_2\times学生数_{経済学部}+\alpha_3\times学生数_{商学部}+\beta
$$
こんな関係式を作ることができれば、2020年の法学部・経済学部・商学部の人数から2020年文学部の学生数を算出することができますね!
$${\alpha_1,\alpha_2,\alpha_3,\beta}$$を求めるために、2016年~2019年のデータを用います。
図解すると以下のようになります。

重要なのは、行と列のどちらを変数、サンプルにするかということです。ここを間違えると正しい答えが出なくなるので注意してください。
sklearnを用いて回帰分析を実装してみます。
from sklearn.linear_model import LinearRegression
def pred(df):
x_train = df.iloc[0:df.shape[0]-1,0:df.shape[1]-1]
y_train = df.iloc[0:df.shape[0]-1,df.shape[1]-1]
x_test = [df.iloc[df.shape[0]-1,0:df.shape[1]-1]]
model_lr = LinearRegression().fit(x_train, y_train)
y_test = model_lr.predict(x_test)
return y_test
#行を変数、列をサンプルと考えるので転置します。行がサンプル、列が変数になっている場合は転置不要
pred(df_ex.T)
#42さて、42と答えが出てきました。
正解を解説付きで見てみましょう。
見事、当たってますね。
求める答えは2020年の文学部の学生であることから、文学部の項目を見ていきます。
2016年から2019年において、毎年○人ずつ増加しているといった変化はなく、また文学部と他の学部の学生数に相関があるとも考えにくいので、「文学部の学生数は全体の学生数に関係しているのではないか」と考えられます。
そこで、2016年を見ていきます。
2016年の全体の学生数は、(78+36+46+40=)200人
これに対して文学部の学生数40人が占める割合は 40/200=1/5=20% となることがわかります。
また、2017年も同様に見ていくと、2017年の全体の学生数は、(68+16+36+30=)150人
これに対して文学部の学生数30人が占める割合は 30/150=1/5=20% となります。
よって、文学部の学生数は全体の学生数の20%にあたると推測されます。これを2020年に当てはめます。
2020年の文学部の学生数をxとおくと、全体の学生数は(76+70+22+x)と表せます。また、文学部の学生数は全体の学生数の20%にあたる(=文学部の学生数の5倍が全体の学生数)と推測されるので、以下の式が成り立ちます。
5x=(76+70+22+x) これを解くと x=42 よって答えは 42人 であると推測されます。
本来、人力で傾向や関係性を導き出し計算していくところを、統計パッケージの力を借りると、ほぼ脳死で解けることがわかりました。
おわりに
関数はあらかじめ作っておくとして、ここまでのフローは慣れれば1分ほどで完了します。空欄予測は1問1分ペースで時間ぴったりぐらいだと記憶しているので、そこもバッチリですね(もちろん本番でやるのはダメですが、、!)。
今回は回帰分析を使って解いてみましたが、もっと精度が上がる方法があるかもしれませんね。
LGBM、RandomForest、ニューラルネットワーク、SVMなど、他の手法で試してみて比較実験する記事をゆくゆくあげようと思います!
この記事が気に入ったらサポートをしてみませんか?