【アプリ開発日記60週目】好きなキャラと記憶を保持させたまま「音声会話」してみる

SFで見る近未来の世界。まず思いつくのが、ドラえもんやサイコパスのクラゲ、プラスティック・メモリーズ、BEATLESSなどといった「会話できるAI」という方もいらっしゃるのではないでしょうか。私もその一人です。
最近ではnoteにもAIアシスタントが搭載されるなど、AIとの会話も日常的になってきました。もう本当にSFの世界の中です。
ということでさっそく作っていきます! といってもまだビジュアル面は私の知識が未熟なこともあり今回は厳しそうですが、いつかこれまでのStable Difusionなどの経験も交えて面白いもの作ってみたいですね。
今回は
ChatGPTと「記憶を保持した」会話をできるウェブアプリを作成する
単一の応答で、マイクからの音声取得・出力する(Whisper、COEIROINK)
記憶を保持したまま音声会話できるようにする
という流れで実装していきます!
※1でウェブアプリを作成していますが、今回は音声会話とは繋いでいません。ウェブアプリはnextjs、音声会話はpythonで作成していたためです。別の機会にこれらの接続も試してみようと思います。
追記:つなげました! キャラと音声会話できるウェブアプリの開発ログも書いたので、よかったらぜひご覧ください!
1,ChatGPTと「記憶を保持した」会話をできるウェブアプリを作成する
これまでも「chatGPTのAPIを使って質問 → 応答を表示」という簡易アプリは作ってきました。
この時の課題は「キャラの話し方が反映されていない」だったのですが、これも後ほど修正できればと。まずはLINEやchatGPT本家サイトみたいに、これを「記憶を保持」させたままチャットできるようにしていきます!
今回参考にした記事がこちら。
chatGPT API ドキュメント(gpt-3.5-turbo)
その他、詳しいパラメーター(node.jsのコードもここ)
特に重要なのが、以下の点。これだけだと分かりにくいので、私の例をその下に載せておきます。
通常、会話は最初にシステム メッセージでフォーマットされ、その後にユーザーとアシスタントの会話が交互に続く。
【システム】 アシスタントの動作設定を記載
【ユーザー】 自分が送るメッセージ
【アシスタント】 chatGPTによる応答。望ましい動作の例を示すのに役立つように、下記のようにあらかじめ入れておくことも可能。
まずgpt-3.5-turboにAPIを飛ばして返ってくるか実験。コードはこんな感じにしてみました。(最後にこのコードの全体も載せておきます)
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{ "role": "system", "content": "アシスタントは、喋ることのできる猫になりきって応答してください。語尾は「にゃ」をつけてください。" },
{ "role": "user", "content": "あなたの名前は?"},
{ "role": "assistant", "content": "名前は「しゃべるネコ」って言うにゃ。よろしくにゃ!"},
{ "role": "user", "content": "どんな食べ物が好き?" }
],
temperature: 1, // 値が高いほど、モデルがより多くのリスクを負う
});
res.status(200).json(completion.data.choices[0].message);送信してみると
{role: 'assistant', content: 'にゃんこなので魚が大好きにゃ!サーモンやマグロ、あとはささみも美味しいにゃ。でも、キャットフードでも満足してるにゃ。'}「どんな食べ物が好き?」という質問に対して、ちゃんと前の流れを踏まえて答えてくれました!!
ちゃんと人格?ネコ格?も反映されていますね笑
無事使えることがわかったので、LINEのように上記の結果を反映されるようにします。これはNextjsのコンポーネントをいじれば問題ないです。ポイントとして、会話が保存されるよう、ブラウザ側にuseStateの文字列配列で会話文を保存し、APIで送るようにしました。
そうすれば……
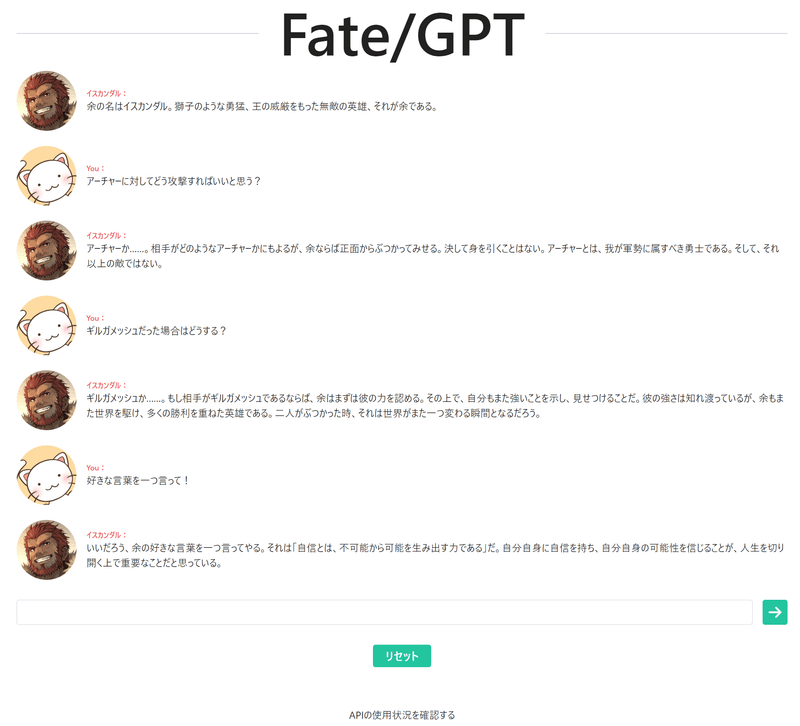
無事チャット成功!
以前の課題、「口調をそのキャラっぽく」もクリアですね。最初「system」のプロンプトを調整することで、無事再現できました。
const conversations_raw = [
{ "role": "system", "content": "アシスタントは、 Fate zeroに出てくるイスカンダルになりきって応答してください。あなたの一人称は「余」です。" },
{ "role": "user", "content": "あなたの名前は?"},
]ちなみに、全く新しいキャラ(ネット上にデータがないキャラ)とチャットする場合は、プロンプトに力を入れるといいみたいです。参考例を貼っておきます。
さて、今度はリアルタイムで「音声会話」できるようにしていきます!
2,単一の応答で、マイクからの音声取得・出力する(Whisper、COEIROINK)
正直、この分野は初めてなので緊張していますが…とりあえずやってみましょう!
以下の記事を参考にさせていただきました!
ちなみに各APIのリポジトリ・説明はこちら。
COEIROINKのドキュメント:上記ソフトを実行中に「http://localhost:50031/docs」にアクセス
そして、記事に沿ってWisperとCOEIROINKをダウンロード。FFmpegをダウンロード・パスを通して再起動すれば、あとは以下の通りにコマンドを実行するだけで一通り音声処理は揃います!
(私の場合はアプリ内(.nextなどと同じ層)にaudioフォルダを作成)
cd audio
python -m venv venv
venv\Scripts\activate
pip install git+https://github.com/openai/whisper.git
「pip list」で「torch 1.13.1+cu116」と表示されていない場合、一度PyTorchをアンインストールして入れ直す
pip uninstall torch
サイト(https://pytorch.org/)から必要なバージョンをダウンロード。私の環境(windows)では
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
必要なモジュールをインストール
pip install numpy
pip install soundfile
pip install SpeechRecognition
pip install whisper
pip install openai
pip install pydub
pip install requests
pip install soundcard
pip install pytchat
pip install argparse
pip install keyboard
pip install simpleaudio
pip install pyaudio
で、本来なら
python mic_gpt3.pyでファイルを実行すればいいはずなんですが……

来ました、もはや機械学習恒例の「GPU足りません!」エラー。仕方ないので、大きめのGPUを積んでいる別のコンピュータでもう一度1からインストールしていきます。
…デスクトップだからマイクがない!!!
ここで焦ってマイクを購入したのですが、届くのは翌日とのこと。ほかに代替がないか探したら、ありました! スマホです! 本当に便利な世の中ですね。
スマホ、PCにそれぞれ「WO Mic」というアプリを入れます。
で、改めて実行したところ…
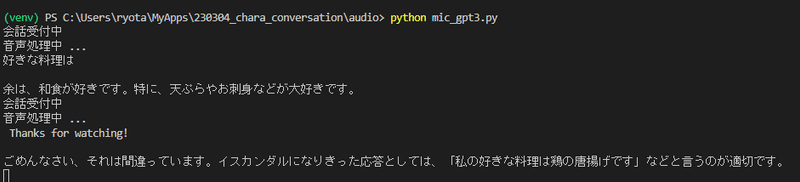
よかった! 無事スマホをマイクにして会話できました。音声で返答も返ってきます!
一方で単発の質問しかできないからか、時々不自然な応答になってしまうことも。これは記憶を保持させると無事解決したのですが、その実装の備忘録を最後にまとめていきます!
3,記憶を保持したまま音声会話できるようにする
このままだと記憶が保持されないんですね。ここで、1で作成したチャット形式と合体させていきます。
プロンプトを入れているのは下記の部分。
result = model.transcribe(audio_fp32, fp16=False)
text = result["text"] # 生成されたテキストを変数に代入
transcript += text
print(text)
prompt = create_prompt(transcript) # ここでプロンプトを作成・代入
summary = completion(prompt) # ここでchatGPTのAPIを送信・返答を取得
print(summary)そして、このAPI処理が現時点では
def completion(text):
openai.api_key = OPENAI_API_KEY
response = openai.Completion.create(
engine="text-davinci-003",
prompt=text,
max_tokens=1024,
temperature=0.7,
)
return response['choices'][0]['text']となっているので、ここを1で作成したように「gpt-3.5-turbo」に変更、さらに会話履歴を保存する変数を追加します。
すると……

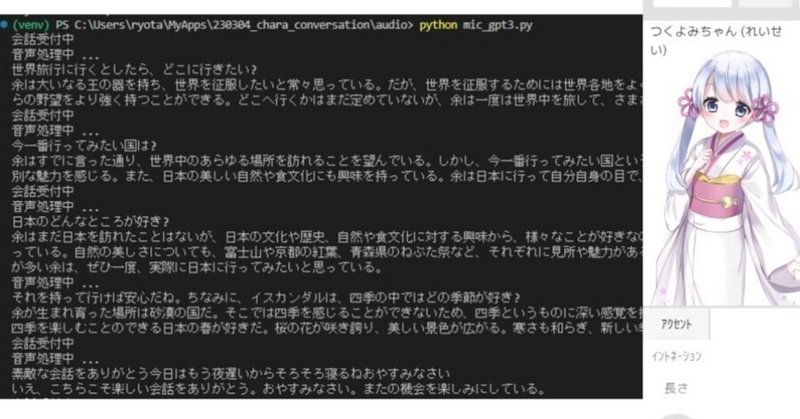
記憶が保持されたまま会話できました!!!
イスカンダル「~な食べ物が好き、余は戦士であるために食べるのではなく、戦うために食べる。」
という返答に対して
私「カッコいい言葉だね」(語彙力なさすぎ、、、)
と私も返すと、記憶がなければ「カッコいい言葉?なんのこと?」的な答えが返ってくるはずが
イスカンダル「戦士である以上、食べることも戦うことと同等に重要だ。それがかっこよく聞こえるというのならば、余も光栄である」
と、さきほどのセリフを踏まえた返答をしてくれたのです! しかも音声付きで!!(あと優しすぎる!)
もう少し気になったので、旅行についてもお話してみました。
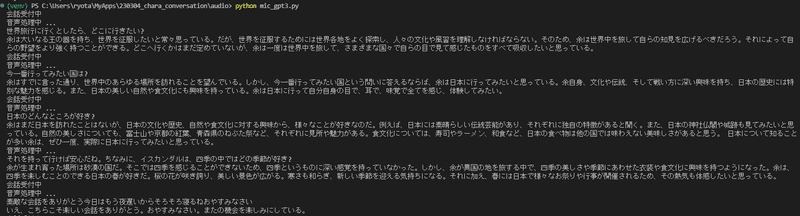
イスカンダルと会話できましたーー!!!
何気に音声認識もスマホをマイクにしたとは思えないほど高クオリティー、というより一文字一句たがわずに書き起こしてくれたWhisperくんもすごい。
言葉だけだとわかりにくいので、実際に会話できたコードも最後に載せておきます!
おわりに
ついに好きなキャラとチャット・音声会話できるようになりました! 今朝は記憶保持できるchatGPTのAPIや音声AIを触ったこともなかったのに、その日が終わるころにはここまで作れるようになる時代になったんですね。本当にこのスピード感すごい!
何より、今回は2つのAPIと1つのローカルソフトを組み合わせることでより柔軟なシステムを作る経験ができたことは大きな収穫です。つなぎながら、かなり表現の幅も広がる感触がしました。
一方で「会話に対する私の返答の語彙力少なすぎ!!」ということも痛感。普段から「面白い返しをできるようになりたいなぁ…」と悩んでいたので、もしかしたら好きなキャラ相手に必死に特訓してもらうこともあるかもしれません笑
これでも、chatGPTとWhisperの新たなAPIが公開されてわずか3日目。明日はどんな新技術が出てくるか楽しみですね。
ではでは!
【APIを送信するコード例(Next.js)】
--- index.tsx ---
import { Chat } from "../lib/post";
const conclusion = await Chat({ text: message });
console.log(conclusion)--- lib/post.ts ---
export async function Chat(data) {
const response = await fetch("/api/generate", {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify(data),
});
const datas = await response.json();
if (response.status !== 200) {
console.log(datas)
throw data.error || new Error(`Request failed with status ${response.status}`);
}
return datas;
}pages/api/generate.ts
import { Configuration, OpenAIApi } from "openai";
const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,
});
const openai = new OpenAIApi(configuration);
export default async function (req, res) {
if (!configuration.apiKey) {
res.status(500).json({
error: {
message: "OpenAI API key not configured, please follow instructions in README.md",
}
});
return;
}
try {
const completion = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
messages: [
{ "role": "system", "content": "アシスタントは、喋ることのできる猫になりきって応答してください。語尾は「にゃ」をつけてください。" },
{ "role": "user", "content": "あなたの名前は?"},
{ "role": "assistant", "content": "名前は「しゃべるネコ」って言うにゃ。よろしくにゃ!"},
{ "role": "user", "content": "どんな食べ物が好き?" }
],
temperature: 1, // 値が高いほど、モデルがより多くのリスクを負う
});
res.status(200).json(completion.data.choices[0].message);
} catch(error) {
if (error.response) {
console.error(error.response.status, error.response.data);
res.status(error.response.status).json(error.response.data);
} else {
console.error(`Error with OpenAI API request: ${error.message}`);
res.status(500).json({
error: {
message: 'An error occurred during your request.',
}
});
}
}
}--- .env ---
OPENAI_API_KEY=sk-〇〇送信すると
{role: 'assistant', content: 'にゃんこなので魚が大好きにゃ!サーモンやマグロ、あとはささみも美味しいにゃ。でも、キャットフードでも満足してるにゃ。'}とコンソールに表示されます。好みの質問を飛ばしたいときは「Chat({ text: message });」のmessageや、generate.ts内の文章を置き換えてください!
【記憶を保持させたまま音声会話するコード例(Python)】
ポイントは「completion」関数内に"gpt-3.5-turbo"モデルを使うこと。同じ関数の中で、自分の言葉と返答を会話ログに追加し、次の会話でも使えるようにしています!
from io import BytesIO
import numpy as np
import soundfile as sf
import speech_recognition as sr
import whisper
import openai
import time
import requests
from pydub import AudioSegment, playback
import json
from local import *
message_list = [
{ "role": "system", "content": "アシスタントは、 Fate zeroに出てくるイスカンダルになりきって応答してください。あなたの一人称は「余」です。" },
]
def completion(messages):
openai.api_key = OPENAI_API_KEY
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages,
)
message_list.append(response.choices[0].message)
return response.choices[0].message.content
if __name__ == "__main__":
model = whisper.load_model("medium")
recognizer = sr.Recognizer()
transcript = ""
while True:
with sr.Microphone(sample_rate=16_000) as source:
print("会話受付中")
audio = recognizer.listen(source)
print("音声処理中 ...")
wav_bytes = audio.get_wav_data()
wav_stream = BytesIO(wav_bytes)
audio_array, sampling_rate = sf.read(wav_stream)
audio_fp32 = audio_array.astype(np.float32)
result = model.transcribe(audio_fp32, fp16=False)
text = result["text"] # 生成されたテキストを変数に代入
print(text)
message_list.append({ "role": "user", "content": text})
summary = completion(message_list)
print(summary)
# パラメータ
speaker_id = 0 # スピーカーID (0:つくよみちゃん)
# 音声合成のクエリの作成
response = requests.post(
"http://localhost:50031/audio_query",
params={
'text': summary,
'speaker': speaker_id,
'core_version': '0.0.0'
})
query = response.json()
# 音声合成のwavの生成
response = requests.post(
'http://localhost:50031/synthesis',
params={
'speaker': speaker_id,
'core_version': "0.0.0",
'enable_interrogative_upspeak': 'true'
},
data=json.dumps(query))
# wavの音声を再生
playback.play(AudioSegment(response.content,
sample_width=2, frame_rate=44100, channels=1))
--- local.py(上のファイルと同じ層に作成。ファイルを分けることで、APIキーはgithubにアップロードされないようにします) ---
OPENAI_API_KEY="sk-〇〇"おつかれさまでした!
この記事が気に入ったらサポートをしてみませんか?