
演奏者が持っている楽器を画像分類してみた 1.実装編

分析屋の藤島です。
私は普段の業務ではAI開発には携わっていないのですが、機械学習には興味があります。
また中学生の頃からトランペットを吹いており、現在でも社会人バンドにてトランペットを吹いています。
初対面の方に楽器をやっている話をすると、管楽器のことについて知らない人が意外といると感じることがあります。プレイヤーとしては街中やテレビ等で好きなバンドやアーティストの演奏シーンで管楽器を見かけたときに、管楽器の形状と名前だけでも覚えてほしいなと思っています。今後、リアルタイムで管楽器を検知できるようなアプリを開発したいと思っていますが、今回は実現可能かどうかを細かいところ気にせずやってみました。
画像収集について
今回はBingでicrawlerを使って人がトランペット、トロンボーンを演奏しているような画像をそれぞれ収集しました。icrawlerはBingやGoogleなどの画像検索機能を用いて自動で画像収集できるライブラリで、簡単に扱うことができます。実際に実行したプログラムは下記の通りです。
※今回のブログで紹介するプログラムは全てGoogle Colabで作成しています。
#icrawlerをインストール
!pip install icrawler
#必要なモジュールをインストール
from icrawler.builtin import BingImageCrawler
#Bingから取得する画像ファイルの格納先
crawler = BingImageCrawler(storage = {'root_dir' : './機械学習_実装/image/trb_player_Bing'})
#Bingの画像検索から「トロンボーン 演者」の画像を100件取得
crawler.crawl(keyword = 'トロンボーン 演者', max_num = 100)
#Bingから取得する画像ファイルの格納先
crawler = BingImageCrawler(storage = {'root_dir' : './機械学習_実装/image/trp_player_Bing'})
#Bingの画像検索から「トランペット 演者」の画像を100件取得
crawler.crawl(keyword = 'トランペット 演者', max_num = 100)Bingを対象にした理由はGoogleだと設定した検索キーワードとかけ離れた画像がわりと収集されてしまったからです。
これで画像収集は以上になります。
次のステップとしては画像処理です。
画像処理について
画像収集で無事に画像を集めることはできましたが、収集した画像だとファイル名がただの数値になっていました。まずはファイル名をつけ直しました。また、画像のサイズがバラバラだったため、リサイズも行いました。
実際に実行したプログラムは下記の通りです。
# 必要なライブラリをインポート
import os
from PIL import Image
# 画像のリサイズと名前変更を行う関数を定義
def resize_and_rename_images(directory, new_prefix, new_size):
# ディレクトリ内のファイルリストを取得してソート
file_list = os.listdir(directory)
file_list.sort()
# ディレクトリ内の各ファイルに対して処理を実行
for i, filename in enumerate(file_list):
# 元の画像ファイルのパスを作成
old_path = os.path.join(directory, filename)
# 新しいファイル名を生成(例:'new_prefix_01.jpg')
new_filename = f'{new_prefix}_{i+1:02d}.jpg'
# 新しい画像ファイルのパスを作成
new_path = os.path.join(directory, new_filename)
# 画像を開いてリサイズ
img = Image.open(old_path)
resized_img = img.resize(new_size)
# リサイズされた画像を新しいファイル名で保存
resized_img.save(new_path)
# 元の画像ファイルを削除
os.remove(old_path)
# 指定したディレクトリ内の画像をリサイズして名前を変更
resize_and_rename_images('./機械学習_実装/image/trb_player_Bing', 'trb_Bing', (300, 300))
resize_and_rename_images('./機械学習_実装/image/trp_player_Bing', 'trp_Bing', (300, 300))その後、機械学習させる上で必要な画像処理を行いました。
実際に実行したプログラムは下記の通りです。
# 必要なライブラリとモジュールをインポート
from PIL import Image
import os, glob
import numpy as np
from PIL import ImageFile
# IOError: 画像ファイルが切り捨てられています(0 バイトが処理されていません)を回避するための設定
ImageFile.LOAD_TRUNCATED_IMAGES = True
# 2つのラベル「trb」と「trp」をクラスとして定義
classes = ["trb", "trp"]
num_classes = len(classes)
# 画像のサイズを指定
image_size = 64
# テストデータの数を指定
num_testdata = 25
# 学習データとテストデータ、それぞれのラベルを保存するリストを用意
X_train = []
X_test = []
y_train = []
y_test = []
# 画像データが格納されているベースディレクトリのパス
base_dir = '/content/drive/MyDrive/Colab Notebooks/機械学習_実装'
# 各クラスのディレクトリにアクセスし、画像を処理するためのループ
for index, classlabel in enumerate(classes):
# クラスのディレクトリパスを取得
photos_dir = os.path.join(base_dir, classlabel)
# ディレクトリ内の画像ファイルのリストを取得
files = glob.glob(os.path.join(photos_dir, "*.jpg"))
# クラス内の各画像に対して処理を実行
for i, file in enumerate(files):
# PIL(Python Imaging Library)を使って画像を開く
image = Image.open(file)
# 画像をRGB形式に変換
image = image.convert("RGB")
# 画像サイズを指定されたサイズにリサイズ
image = image.resize((image_size, image_size))
# 画像データをNumPy配列に変換
data = np.asarray(image)
# テストデータの数よりも少ない場合は、テスト用のリストに追加
if i < num_testdata:
X_test.append(data)
y_test.append(index)
else:
# -20度から20度まで、5度ずつ回転した画像を作成
for angle in range(-20, 20, 5):
# 画像を回転
img_r = image.rotate(angle)
data = np.asarray(img_r)
# 回転した画像とそのラベルを学習用リストに追加
X_train.append(data)
y_train.append(index)
# 左右反転した画像を取得
img_trains = img_r.transpose(Image.FLIP_LEFT_RIGHT)
data = np.asarray(img_trains)
# 左右反転した画像とそのラベルを学習用リストに追加
X_train.append(data)
y_train.append(index)
# リストをNumPy配列に変換
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(y_train)
y_test = np.array(y_test)
# 学習データとテストデータ、それぞれのラベルをNumPyの.npyファイルに保存
xy = (X_train, X_test, y_train, y_test)
np.save("/content/drive/MyDrive/Colab Notebooks/機械学習_実装/trb_trp.npy", xy)これで画像処理は終了です。
次はいよいよ画像を学習させていきます。
学習モデルについて
今回はディープラーニングをやったことある方なら誰もが知っているCNN(畳み込みニューラルネットワーク)で実行してみました。CNNは画像中のピクセルを用いて局所パターンを見つけて学習する方法です。データを学習することで入力画像から特徴量を抽出しそれらを区別することができるようになっています。
実際に実行したプログラムは下記の通りです。
# 必要なライブラリとモジュールをインポート
import numpy as np
from PIL import Image
import os, glob
import keras
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
# 訓練データの読み込み
data = np.load("/content/drive/MyDrive/Colab Notebooks/機械学習_実装/trb_trp.npy", allow_pickle=True)
X_train, X_test, y_train, y_test = data
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X_train, y_train, test_size=0.2)
# データの正規化
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') / 255
#フラグ立て
y_train = keras.utils.to_categorical(y_train, 2)
y_test = keras.utils.to_categorical(y_test, 2)
# モデルの定義
model = Sequential()
# 畳み込み層(32フィルター、カーネルサイズは3x3、活性化関数はReLU)
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)))
# プーリング層(プーリングウィンドウサイズは2x2)
model.add(MaxPooling2D(pool_size=(2, 2)))
# ドロップアウト層(ドロップアウト率は0.25)
model.add(Dropout(0.25))
# 畳み込み層を追加(64フィルター、カーネルサイズは3x3、活性化関数はReLU)
model.add(Conv2D(64, (3, 3), activation='relu'))
# プーリング層を追加(プーリングウィンドウサイズは2x2)
model.add(MaxPooling2D(pool_size=(2, 2)))
# ドロップアウト層を追加(ドロップアウト率は0.25)
model.add(Dropout(0.25))
# フラット化層(1次元の配列に変換)
model.add(Flatten())
# 全結合層を追加(ユニット数は128、活性化関数はReLU)
model.add(Dense(128, activation='relu'))
# ドロップアウト層を追加(ドロップアウト率は0.5)
model.add(Dropout(0.5))
# 出力層(ユニット数は2(trbとtrpのクラス数)、活性化関数はSoftmax)
model.add(Dense(2, activation='softmax'))
# モデルのコンパイル(損失は誤差交差エントロピー関数、更新方法はSGD、評価は精度)
model.compile(loss='categorical_crossentropy', optimizer='SGD', metrics=['accuracy'])
# モデルの学習
history = model.fit(X_train, y_train, batch_size=5, epochs=100, validation_data=(X_test, y_test))
# モデルの評価
score = model.evaluate(X_test, y_test, verbose=1)
print('正解率=', score[1], 'loss=', score[0])
# 学習用データを用いて精度を表示
plt.plot(history.history['accuracy'])
# 検証用データを用いて精度を表示
plt.plot(history.history['val_accuracy'])
# 図のタイトル表示(精度)
plt.title('Accuracy')
# train,testの順で縦に並べ、左上に凡例を表示
plt.legend(['train', 'test'], loc='upper left')
# グラフを表示
plt.show()
# 学習用データを用いて誤差を表示
plt.plot(history.history['loss'])
# 検証用データを用いて誤差を表示
plt.plot(history.history['val_loss'])
# 図のタイトル表示(損失)
plt.title('Loss')
# train,testの順で縦に並べ、左上に凡例を表示
plt.legend(['train', 'test'], loc='upper left')
# グラフを表示
plt.show()上記を実行すると正解率と損失を示したグラフが表示されます。
学習結果について
まず正解率を見ていきましょう。

上記の画像は学習回数(横軸)ごとの正解率(縦軸)を示したグラフになります。
正解率は最終的には学習用データも検証用データも約99.5%となっており、結果としてはかなり良いものとなっていますが、過学習が起きている可能性があります。
次に損失を見ていきましょう。
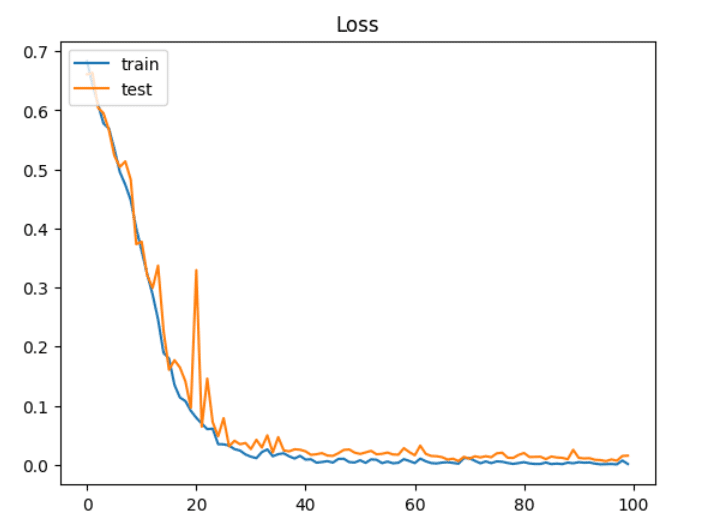
上記の画像は学習回数(横軸)ごとの損失(縦軸)を示したグラフになります。
損失は学習用データも検証用データも約0.015となっており、結果としてはかなり良いものとなっています。
まとめ
今回は細かいところを気にせずやってみました。実際やってみた感想は自分の趣味とITを掛け合わせて実装できたので楽しかったです。ですが、画像データに関してはそもそも楽器のみ写っている写真を学習させて、実際演奏している画像を用いて、判別できるのかどうかをやってみる方が良いと思いました。その理由としては演奏している写真だと人の特徴と楽器の特徴を掛け合わせて、トランペットとトロンボーンを分類している可能性があるからだと考えています。また、過学習が起きている可能性もあるため、本当にこのモデルが使い物になるかどうかも検証する必要があると考えています。そのため、次回は過学習が起きているかどうかの検証をテーマにブログを投稿したいと思います。
ここまでお読みいただき、ありがとうございました!この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。