
[Unity]音声認識・合成アプリを作ってみた

こんにちは! エンジニアの宮Pです😎
今回は、前回試した音声認識プロジェクトを利用して、音声認識・合成アプリの基本形を作ってみます🙂
前回の記事では、GitHubにアップされているプロジェクトを動かして、OS内蔵の音声認識・合成エンジンの動きを確認しました。
このプロジェクトの中にあるプラグインを利用して、最小単位のアプリを作ってみます。
最小単位だからこそ、どのように機能を定義するのか、どう発展させればよいのかが分かってくると思います😉
新規プロジェクトの用意
まずは新規のUnityプロジェクトを用意します。
前回の記事を参考にして、GitHubにアップされた音声認識プロジェクトを実行できるところまで進めてください。
このプロジェクトを既に試していた方は、Unityプロジェクト全体をコピーしてしまうと簡単です。
その場合はPlayer Settings画面でProduct Nameを変更して、別プロジェクトとして認識されるようにしておきましょう🙂

新しいシーンの背景を用意
このプロジェクトは高機能であるがゆえに多くの処理が実装されています。今回は処理全体をシンプルにしたいので、このメイン画面に代わる新しいシーンを作ります。
Project Settingsを開き、Scenes in Buildに設定されている「SampleSpeechToText」を右クリックして、削除してください。
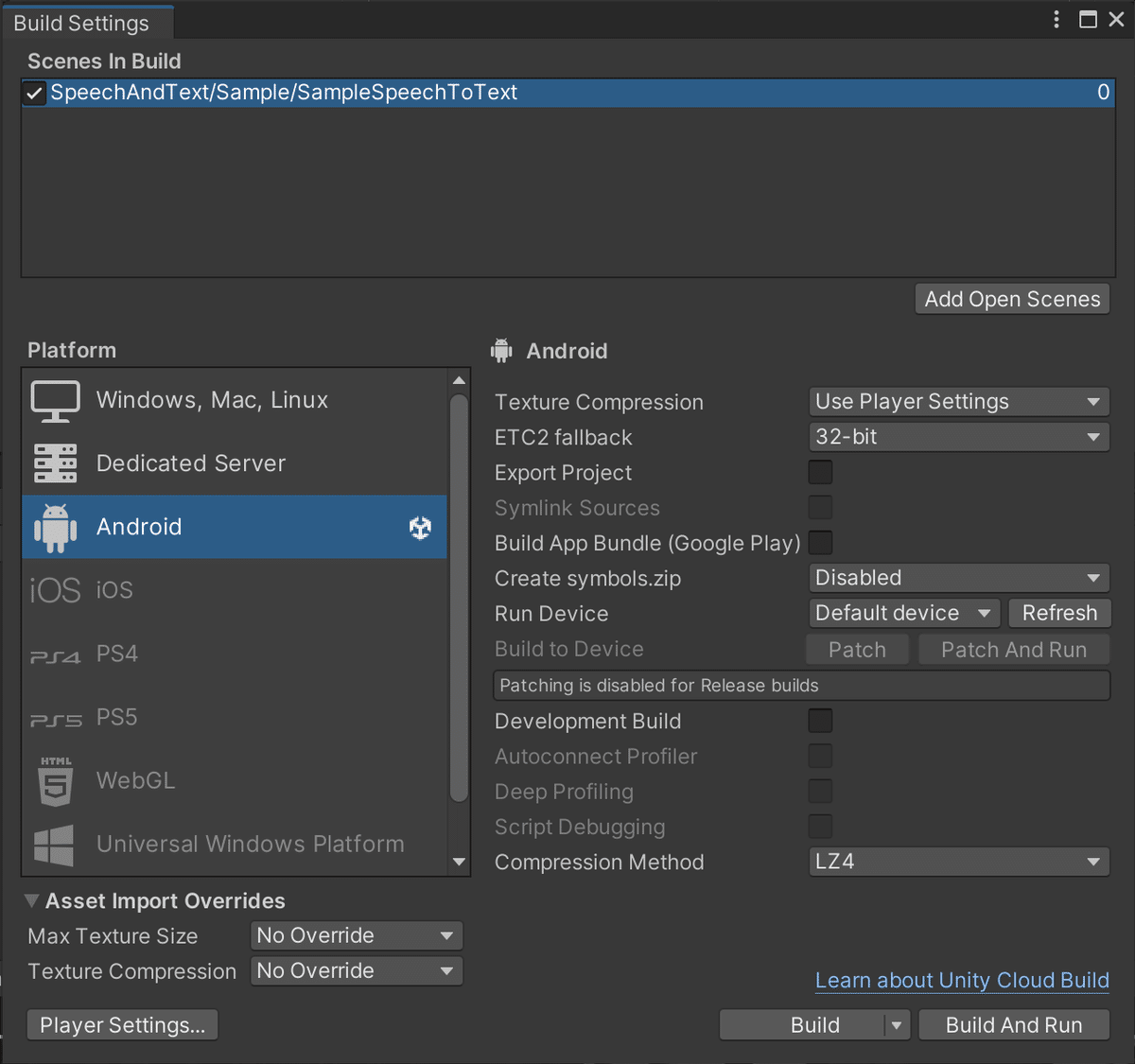
代わりになる新しいシーンを作りましょう。
このシーンの中に「録音ボタン」「再生ボタン」それから「テキスト表示エリア」を用意します。
以下は新しいシーンの一例です。
「Main」という名前のシーンを追加して、Clear FlagsをSkybox、ProjectionをPerspectiveに設定します。
WindowメニューからRendering→Lightingを選びます。
表示されたダイアログのEnviromentタブを選んで、Skybox MaterialをDefailt-Skyboxにします。

Direction Lightも追加して、シーンを明るくします。

テキスト表示エリアを追加
音声認識されたテキストを表示するエリアを用意します。
HierarychyビューにCanvasを作り、UI Scale ModeをScale with Scene Sizeにします。
ここにImageを追加します。
Anchor Presetsを開いてbottom、strechを選択してください。
座標のパラメーターはスクリーンショットを参考ににししつ、画面の下にセンタリングされるように配置してください。
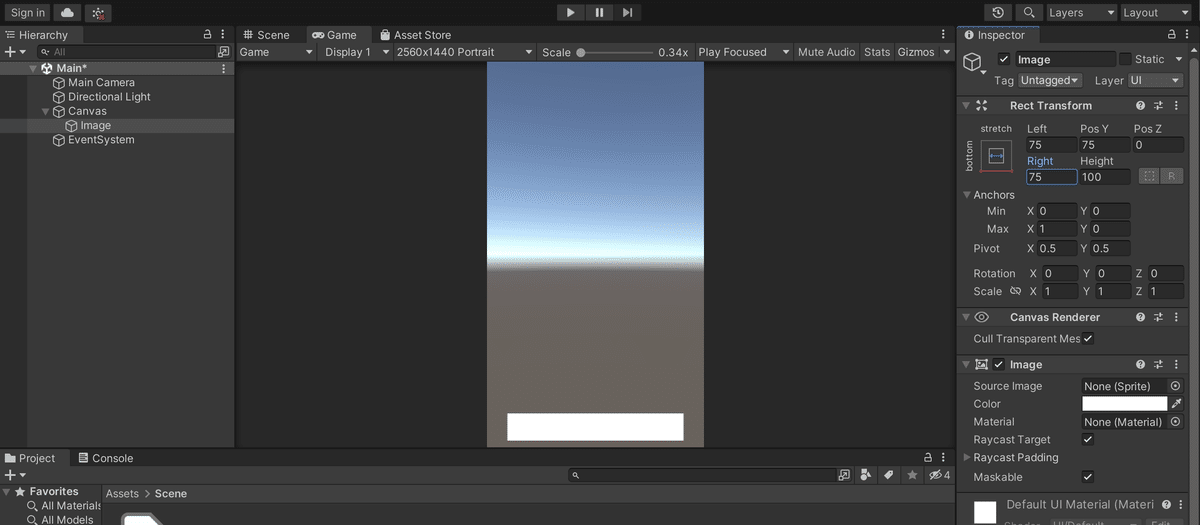
このImageに、TextMesh Proを追加します。
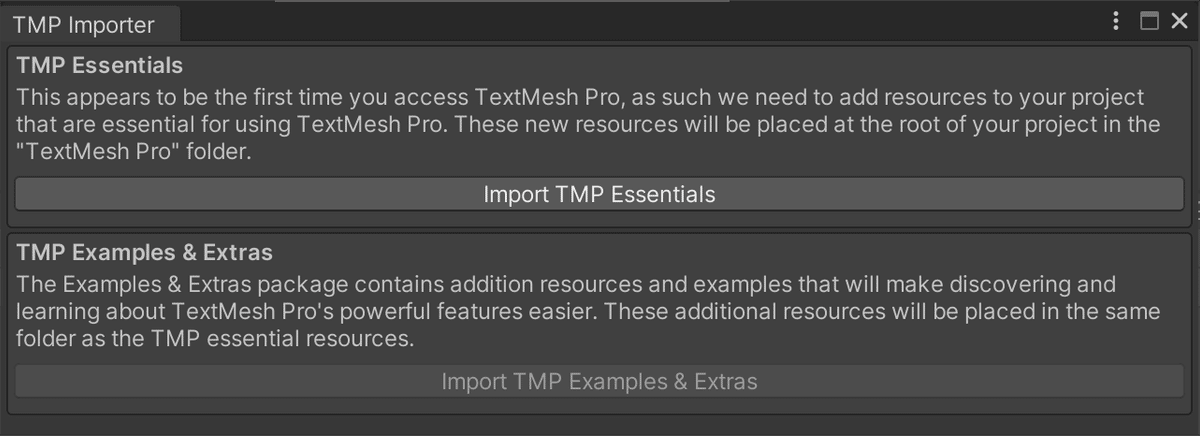
初めてTextMesh Proを使うと、リソースのインポートを促すダイアログが表示されます😮
[Import TMP Essentials]ボタンをクリックして、リソースをインストールしましょう。
インストールが終わると、下の段の[Import TMP Examples & Extras]ボタンがアクティブになるので、こちらもボタンをクリックしてインポートしておきます。
Vertex Colorを背景の白色とは異なる色(黒など)にして、テキストが見えるようにしてください。
Font SizeとAlignment、各座標のパラメータを調整して、枠の中にテキストがセンタリングされるようにします。
テキストの内容を「何かを話してください」と変更すると……文字化けして四角形になってしまいました😨

実はText Mesh Proでは日本語が使えません。
この問題を解決するために、日本語のフォントアセットを作成します。
フォントアセットの作成
今回は種類も豊富で、基本的に無料かつ商用OKのGoogleフォントを利用することにしました。
これらのフォントの中から好きなものを選んでダウンロードしてください。
今回は「Noto Sans Japanese」を選んで[Download family]ボタンでダウンロードし、展開したファイルの中から「NotoSansJP-Medium.ttf」を使うことにしました。
ProjectビューのAssetsにFontsフォルダを作り、このNotoSansJP-Medium.ttfをドロップします🙂
WindowメニューからTextMesh Pro > Font Asset Creatorを選択します。
表示されたダイアログの項目を設定していきます。
Source Font Fileには、先ほどのNotoSansJP-Medium.ttfをドロップします。
Atlas Resolutionの2つの数値は、それぞれ「8192」にします。
Character Setは、Custom Charactersにしてください。
Custom Character Listの中にはアセット用のテキストを入力する必要があります。
GitHub Gistで公開してくださっている方がいますので、これを使わせて頂きます😄
日本語文字コード範囲指定
[Download Zip]ボタンでダウンロードし、ファイルを展開するとこんなテキストが入っています。
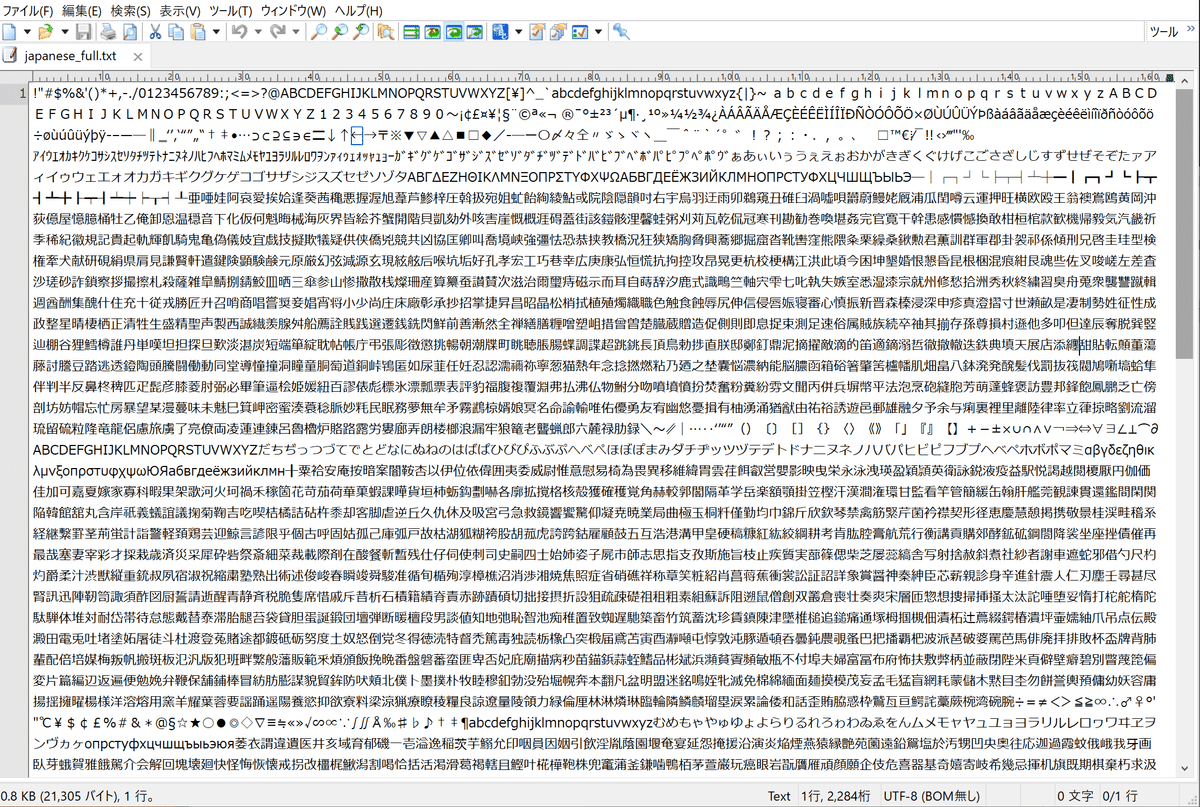
このテキストをすべて選択して、Custom Character Listに貼りつけてください。

[Generate Font Atlas]ボタンをクリックすると、フォントアセットの作成が始まります。
この処理には結構な時間が掛かります。私の環境では30分近く掛かったので、何かで時間をつぶしましょう😋

完成するとこんな内容が表示されますので、[Save]ボタンでこのアセットを保存します。
ファイル名はデフォルトのまま、NotoSansJP-Medium SDFにしておきます。
作成したフォントアセットを、TextMesh ProのFont Assestへドロップすると、文字化けしていたテキストが正常に表示されました😆

音声認識と音声合成ボタンの作成
2つのSphereを音声認識と音声合成用のトリガーとして用意します。
まずは1つ、Sphereを作りました。

これをDuplicateして、右側にも同様のSphereを用意します。
役割を間違えないように赤と青の色を付けて、RedListenerとBlueSpeakerという名前に変更しました🙂
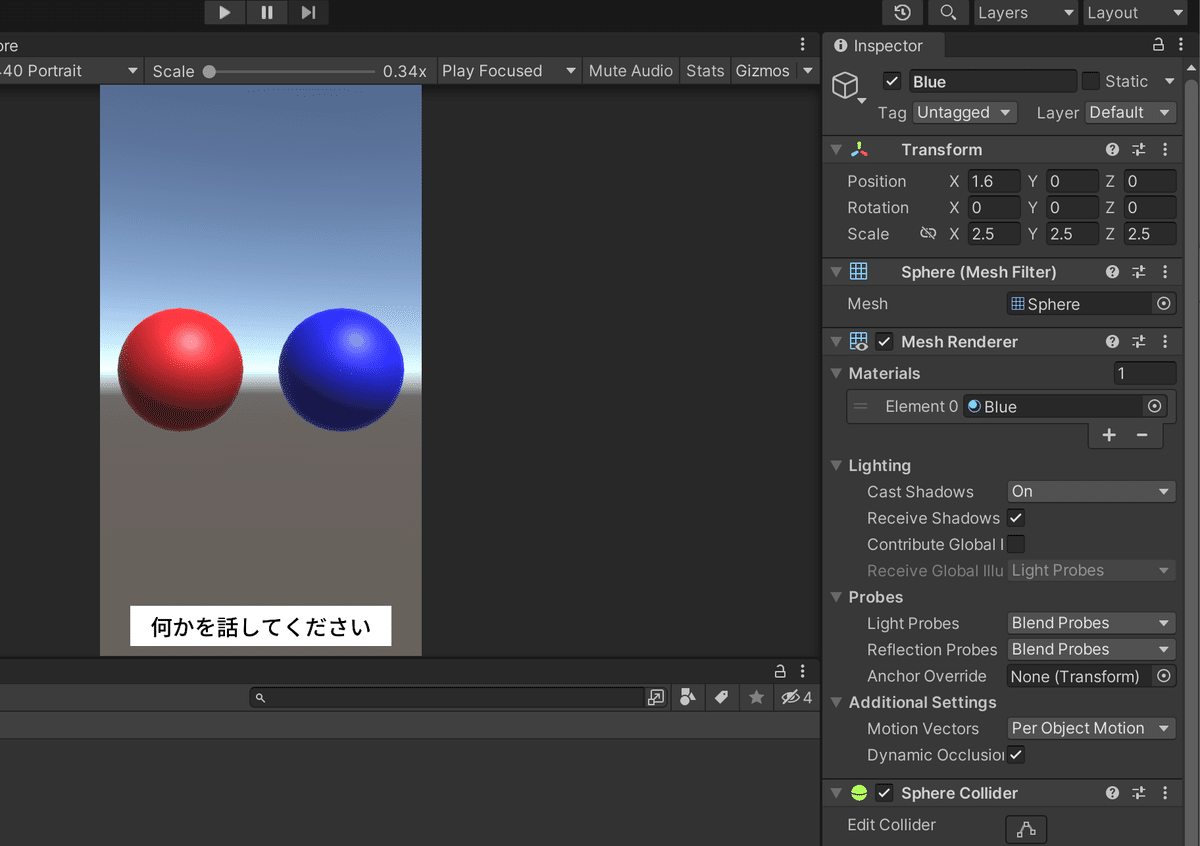
このリスナー、スピーカーを反応させるために、スクリプトを用意します。
ClickHandlerという名前のcsファイルを作りました。
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using UnityEngine.Events;
[RequireComponent(typeof(Collider))]
public class ClickHadler : MonoBehaviour
{
public UnityEvent upEvent;
public UnityEvent downEvent;
void OnMouseDown()
{
Debug.Log("Down");
downEvent?.Invoke();
}
void OnMouseUp()
{
Debug.Log("Up");
upEvent?.Invoke();
}
}マウスダウン、アップのイベントを取得して、それぞれログを出力します。
Inspectorビューで、このスクリプトを赤と青のスフィアに追加してください。
実行して赤と青のスフィアをクリックすると、Donw、Upのログが出力されていることが分かります😉

これで、基本的なUIは完成しました。
ここから音声認識、合成に関するコードを実装していきます。
音声認識・合成のコーディング
空のGameObjectを追加して、SpeechToTextとリネームします。
ここにAssets > SpeechAndText > Scriptcsフォルダの中のSpeechToText.csを追加します。
isShowPopupAndroidのチェックボックスは付けたままにしてください。このチェックを外すと、録音の際に必要なダイアログが表示されず、アプリが強制終了してしまいます😑

今度は音声合成用のオブジェクトを追加します。
先ほどと同じように空のGameObjectを追加して、TextToSpeechとリネームし、ここにTextToSpeech.csを追加します。

最後に、全体を制御するためのオブジェクトを追加します。
空のGameObjectを追加して、SpeechControlerとリネームします。
このオブジェクトに追加するSpeechControler.csというスクリプトを新規作成します。
処理は既存のTextToSpeech.csを流用しながら作っていきます。
まずは言語設定です。日本語を扱うために、LANG_CODEに「ja-JP」を代入します。
TextToSpeechの引数の2つの「1」は、それぞれピッチとレートです。
using TextSpeech;
public class SpeechControler : MonoBehaviour {
const string LANG_CODE = "ja-JP";
void Start()
{
SetUp(LANG_CODE);
}
void SetUp(string code)
{
TextToSpeech.Instance.Setting(code, 1, 1);
SpeechToText.Instance.Setting(code);
}
}音声認識されたテキストの表示領域も定義します。
using TMPro;
[SerializeField]
TextMeshProUGUI uiText;音声の内容をテキストに変換する処理を作ります。
#regionは必須ではないですが、ソースの可読性を向上させるために入れています。
最終的な結果をテキスト領域のuiText.textに代入しています。
#region SpeechToText
public void StartListening()
{
SpeechToText.Instance.StartRecording();
}
public void StopListening()
{
SpeechToText.Instance.StopRecording();
}
void OnFinalSpeechResult(string result)
{
uiText.text = result;
}
#endregion次にテキストの内容を読み上げる処理を作ります。
同じように#regionで囲んでおきます。
OnSpeakStart()、OnSpeakStop()には、それぞれ音声の再生の開始、終了時に実行する処理を記述します。今回は何も書いていませんが、通常は開始と終了を示すテキストや画像を表示させたりするでしょう。
#region TextToSpeech
public void StartSpeaking()
{
TextToSpeech.Instance.StartSpeak(uiText.text);
}
public void StopSpeaking()
{
TextToSpeech.Instance.StopSpeak();
}
void OnSpeakStart()
{
;
}
void OnSpeakStop()
{
;
}
#endregionStart()にコールバックを定義します。
void Start()
{
Setup(LANG_CODE);
SpeechToText.Instance.onResultCallback = OnFinalSpeechResult;
TextToSpeech.Instance.onStartCallBack = OnSpeakStart;
TextToSpeech.Instance.onDoneCallback = OnSpeakStop;
}Androidではマイクの使用許可を確認する必要があります。
CheckPermissionという関数を追加して、Start()で呼び出すようにしました。
using UnityEngine.Android;
void Start()
{
Setup(LANG_CODE);
SpeechToText.Instance.onResultCallback = OnFinalSpeechResult;
CheckPermission();
}
void CheckPermission()
{
#if UNITY_ANDROID
if (!Permission.HasUserAuthorizedPermission(Permission.Microphone))
{
Permission.RequestUserPermission(Permission.Microphone);
}
#endif
}
コーディングはこれで完了です。
早速ビルドをして、動作を確認してみましょう。
音声認識と合成の様子
Android端末へインストールして様子を見てみます。
まずは音声認識の様子。
赤いスフィアをタップすると録音が始まり、話した内容がテキストに変換されています😊
あまり長文を話すとテキストが表示しきれなくなるので、ほどほどの量が良いです(認識自体は長くても問題はありません)。
次に、音声合成も試してみます。
青いスフィアをタップすると、変換されたテキストを読み上げます。
どちらも正常に動作しています。
本当に最低限の機能しか実装していないので、出来ることは限られています。
しかしながら、シンプルなだけに「ここに、こんな機能を付けてみよう」というポイントが絞りやすいと思います。
ぜひ、このアプリを拡張して遊んでみてください😘
まとめ
今回は、前回使ったプロジェクトを利用して、シンプルな音声認識・合成のアプリを作ってみました。
ピッチやレートを変えて色んなことを喋らせてみたり、別の言語を試してみたりするのも面白いです😊
私たちは、お客様のご要望にあわせて様々なアプリ、コンテンツを制作しております。
ご質問やご要望は、<お問い合わせページ>よりお送りください。
この記事が気に入ったらサポートをしてみませんか?