
【Python学習日記4】 LSTMによる株価予測

こんにちは。プログラミングスクールでPythonを使ったデータ分析を学習中の ひよっこ分析者B(Book358)です。今回は「日経225の終値をLSTMモデルで予測する」スクールでの課題についてまとめました。
※ 開発環境
Python3,Windows11 ,Chrome,Google Colaboratory
1. 概要
1.1 題目
LSTMによる株価予測
1.2 目的
「日経225の終値データセット」を用いて、終値(株価)の推移を予測するLSTMの機械学習モデルを構築すること
1.3 データセット
日経225の終値(株価)の時系列データ
2. LSTM (長・短期記憶)
LSTM (Long Short-Term Memory)は、ニューラルネットワークの一種で、主に時系列データやシーケンスデータの処理に使用されるモデル。RNN (Recurrent Neural Network)の一種であり、通常のRNNに比べて長期的な依存関係を学習することができる。

・セル状態 (cell state)
過去の情報を保持するためのメモリセル
・入力ゲート (input gate)
新しい情報を受け入れるかどうかを決定
・忘却ゲート (forget gate)
記憶セルがどれだけの情報を忘れるかを制御
・出力ゲート (output gate)
記憶セルの内容を次のステップでどれだけ出力するかを制御
3. ライブラリのインポート
使用するライブラリをインポート。
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow import keras
import math
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
from IPython.core.interactiveshell import InteractiveShell
pd.options.display.max_rows = 5
InteractiveShell.ast_node_interactivity = "all"4. データセット
データセットを読込み、NumPyの配列で値を取得した後、データ型を「float32」に変換します。
data = pd.read_csv('nikkei225.csv', usecols=[1], engine='python', skipfooter=3)
data
data = data.values
data
data = data.astype('float32')
data.dtype
5. 前処理
以下の手順で、データの前処理を行います。
5.1 データ分割
交差検証の為、データを「訓練データ(train)」と「検証データ(test)」に
分割します。(分割比 2:1)
train_size = int(len(data) * 0.67)
train = data[0:train_size, :]
test = data[train_size:len(data), :]
train.shape
test.shape
5.2 スケーリング (正規化)
正規化により、データを0~1の範囲にスケーリングします。
scaler = MinMaxScaler(feature_range=(0, 1))
scaler_train = scaler.fit(train)
scaler_train
train = scaler_train.transform(train)
test = scaler_train.transform(test)
train
6. 入力データと正解ラベル
6.1 関数を定義
入力データ・正解ラベルを作成する関数(create_data)を定義します。
def create_data(data, look_back):
data_X, data_Y = [], []
for i in range(look_back, len(data)):
data_X.append(data[i-look_back:i, 0])
data_Y.append(data[i, 0])
return np.array(data_X), np.array(data_Y)6.2 入力データと正解ラベル
入力データと正解ラベルを作成します。
look_back = 3
train_X, train_Y = create_data(train, look_back)
test_X, test_Y = create_data(test, look_back)
train_X
train_Y
6.3 データ整形
データを整形します。
train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], 1)
test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)
train_X
test_X = test_X.reshape(test_X.shape[0], test_X.shape[1], 1)
test_X[:3]
7. モデル構築 (LSTM)
kerasでLSTMのアルゴリズムを作成した後、モデルに「入力データ(train_X)」と「正解ラベル(train_Y)」を入れて学習(fit)します。
model = keras.Sequential()
model.add(keras.layers.LSTM(64, input_shape=(look_back, 1), return_sequences=True))
model.add(keras.layers.LSTM(32))
model.add(keras.layers.Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model
model.fit(train_X, train_Y, epochs=15, batch_size=1, verbose=2)
model
8. 予測データの作成
8.1 予測値を算出
.predictで学習済モデルによる予測値を算出します。
train_predict = model.predict(train_X)
test_predict = model.predict(test_X)
train_predict
8.2 スケーリングの解除
.inverse_transformでスケーリングしたデータを元に戻します。
train_predict = scaler_train.inverse_transform(train_predict)
train_Y = scaler_train.inverse_transform([train_Y])
test_predict = scaler_train.inverse_transform(test_predict)
test_Y = scaler_train.inverse_transform([test_Y])
train_predict
train_Y
9. 予測精度の計算
mean_squared_errorでRMSE (二乗平均平方根誤差)を算出します。
train_score = math.sqrt(mean_squared_error(train_Y[0], train_predict[:, 0]))
test_score = math.sqrt(mean_squared_error(test_Y[0], test_predict[:, 0]))
print('Train Score: %.2f RMSE' % (train_score))
print('Test Score: %.2f RMSE' % (test_score))
10. データのプロット
10.1 プロットのためのデータ整形
プロット用に空(NAN)のデータを作成します。
train_predict_plot = np.empty_like(data)
train_predict_plot[:, :] = np.nan
train_predict_plot[look_back:len(train_predict)+look_back, :] = train_predict
train_predict_plot.shape
train_predict_plot
test_predict_plot = np.empty_like(data)
test_predict_plot[:, :] = np.nan
test_predict_plot[len(train_predict)+(look_back*2):len(data), :] = test_predict
10.2 データのプロット
データをプロットします。
plt.title("nikkei225")
plt.xlabel("time (day)")
plt.ylabel("closing price")
plt.plot(data, label='nikkei225 data')
plt.plot(train_predict_plot, label='train_predict')
plt.plot(test_predict_plot, label='test_predict')
plt.legend(loc='upper right')
plt.show()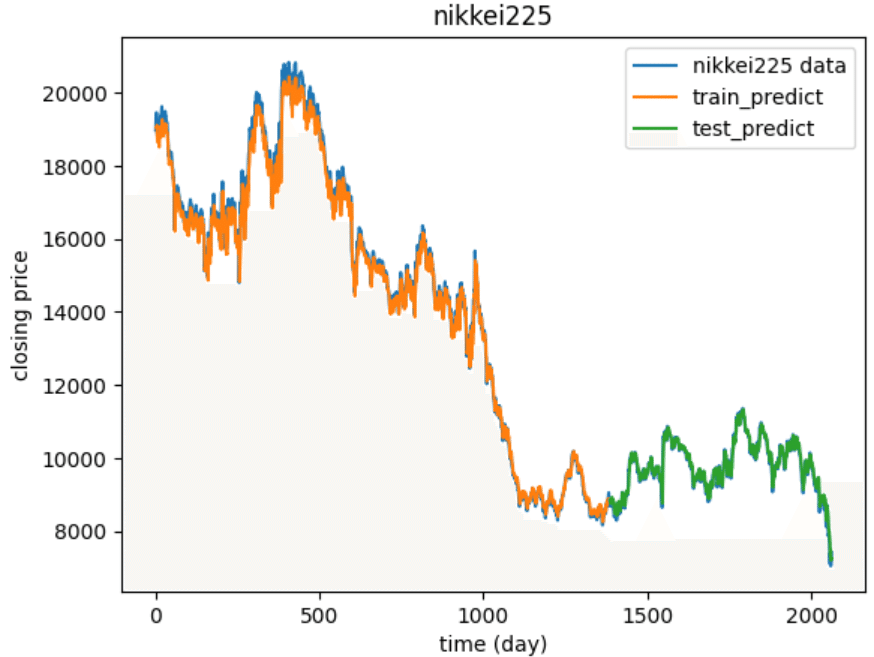
11. 考察
今回の「LSTMによる株価予測」では、「既知の時系列データ」からLSTMモデルを構築し、「予測値の時系列データ」との比較を行いました。Fig.2のグラフから、予測値(オレンジ, 緑)は既知のデータ(青)に比較的近い挙動(線形)を示していました。
次回はSARIMAを用いて、「既知の時系列データ」から「未知(未来)の時系列データ」を予測するモデルを構築してみようと思います。