
【Python学習日記2】 手書き数字の識別

こんにちは。プログラミングスクールでPythonを使ったデータ分析を学習中の ひよっこ分析者B(Book358)です。今回は「0~9の手書き数字(画像)」を用いて数字の識別モデルを構築するkaggleの入門コンペにトライしてみました。データセットは、70,000枚の数字画像を集めた「MNIST(エムニスト)」です。
※ 開発環境
Python3,Windows11 ,Chrome,Google Colaboratory
1. 概要
1.1 題目
Digit Recognizer
(数字認識装置)
1.2 目的
手書き画像のデータセットを用いて、数字を識別する機械学習モデルを構築すること
1.3 データセット
・データファイル(train.csv, test.csv)は、0から9までの数字を手書きしたグレ
ースケール画像
・各画像は縦28×横28ピクセル (合計784ピクセル)
・手書き数字データ(train.csv)は785列
最初の列は 「label (正解ラベル)」、残りの列は「該当する画像のピ
クセル値 (特徴量)」
2. ライブラリのインポート
使用するライブラリをインポート。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import StratifiedKFold
from sklearn.ensemble import RandomForestClassifier ・pandas
Pythonのデータ解析ライブラリ
・numpy
Pythonで数値計算を効率的に行うためのライブラリ
・matplotlib.pyplot
Pythonのグラフ描画のためのライブラリ
・StratifiedKFold
Pythonの機械学習ライブラリ(sklearn)の中にある
層化K分割交差検証(Stratified K-fold)を行うためのモジュール
・RandomForestClassifier
決定木のモデルを複数作り、分類の結果をモデルの多数決で決める手法
(個々に学習した複数の学習器を組み合わせて汎化性能を向上させるア
ンサンブル学習の一種)
3. データの確認
以下の手順で、データセットを確認します。
3.1 データセットの読込
pd.read_csv()でkaggleのinputからデータセットを読込みます。今回は42,000行, 785列の「手書き数字データ (train_df)」と、28,000行, 784列の「テスト画像 (test_df)」があります。train_dfにだけある一番左の「label (0~9の数字)」が機械学習モデルで予測(識別)できる様にしたい項目です。
train_df = pd.read_csv('../input/digit-recognizer/train.csv')
test_df = pd.read_csv('../input/digit-recognizer/test.csv')
train_df
test_df

3.2 正解ラベル(0~9)の数を確認
.value_counts()でlabel列の各数字(0~9)の数を集計します。各数字の数は概ね3,800~4,700の範囲内であり、大きな偏りはない様です。
train_df['label'].value_counts()
3.3 画像の確認
以下の手順で、手書き数字データ(train_df)内の「特徴量(pixel)」を元に、1行目(インデックス番号 i=0)のlabelである「1」の画像を表示してみます。

3.3.1 特徴量(pixel)の抽出
.ilocでtrain_dfから1行目(i=0) の特徴量(pixel)を抽出します。
i = 0
tmp_img = train_df.iloc[i, 1:]
tmp_img.head()
3.3.2 配列(numpy array)に変換
.valuesで抽出した特徴量(tmp_img)を配列(numpy array)に変換します。
tmp_img = tmp_img.values
tmp_img
3.3.3 2次元画像(28x28)に変換
.reshapeで、配列の形(shape)を784(列数)から「2次元画像(28x28)」に
変換します。
tmp_img = tmp_img.reshape(28,28)
tmp_img
tmp_img.shape
3.3.4 画像を表示
plt.imshowで、配列(tmp_img)を画像として表示します。
plt.imshow(tmp_img, cmap='gray')
plt.show()
4. 正規化 (前処理)
以下の手順で、画像データのピクセル値(0~255)を0~1の範囲に揃える正規化(前処理)を行います。これにより、モデル性能の向上や、学習の高速化などが期待できます。
4.1 特徴量と正解ラベルの列を指定
特徴量(pixel)の列をcol_X,正解ラベル(label)の列をcol_Yに指定します。
col_X = train_df.columns.values[1:].tolist()
col_X[:5]
col_X[-5:]
col_Y = 'label'
col_Y
4.2 trainとtestを一旦結合
train_dfとtest_dfをまとめて前処理 (正規化)する為、一旦、pd.concatを用いて2つのデータを結合します。
traintest_df = pd.concat([train_df, test_df])
traintest_df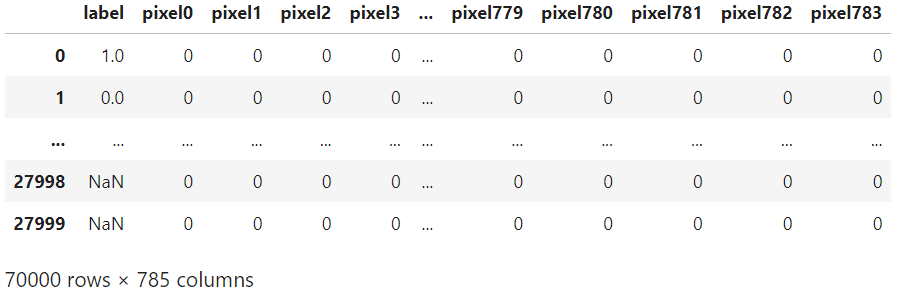
4.3 indexを割り当て直す
.reset_indexで結合後のデータのインデックスを「0~69,999」に割り当て直します。
traintest_df = traintest_df.reset_index(drop=True)
traintest_df
4.4 idの列を追加 (データの取違防止)
np.arange(len(データ名))で行番号をidとして割り当て、追加します。
traintest_df['id'] = np.arange(len(traintest_df))
traintest_df
4.5 列の並び替え
traintest_dfの列順を「id」,「col_Y (正解ラベル)」,「 col_X (特徴量)」に変更し、「id」を先頭(一番左)に移動します。
traintest_df = traintest_df[['id', col_Y] + col_X]
traintest_df
4.6 正規化
機械学習に用いる「 col_X (特徴量)」の部分(列)に対し、.values/255で値の範囲を0-255から0-1に変換(スケーリング)します。(正規化)
traintest_df.loc[:,col_X] = traintest_df.loc[:,col_X].values/2554.7 trainとtestを再分割
前処理 (正規化)が完了した為、結合していたtrainとtestのデータを再分割します。
train_df = traintest_df.iloc[:len(train_df)]
train_df.loc[:,col_Y] = train_df[col_Y].values.astype(int)
train_df ・.iloc [ : len(train_df) ]
train_dfの長さ(インデックス数)分の行まで取得
(結合データの先頭行~train_df終了行までを抽出できる)
・[col_Y].values.astype(int)
正解ラベル(col_Y)の列の値を、整数型に変換

test_df = traintest_df.iloc[len(train_df):].reset_index(drop=True)
test_df ・.iloc [ len(train_df) : ]
train_dfの終了行より後ろ(test_dfの行)を取得
・.reset_index(drop=True)
インデックス番号を0から再取得

5. バリデーションの作成
交差検証を行う為、前処理済のデータを訓練データ(x_train, y_train)と検証データ(x_valid, y_valid)に分割します。
(今回はhold-out法を複数回繰り返す「k-fold Cross Validation」を用います)
5.1 k-foldの分割条件を設定
StratifiedKFoldでfoldの分割数(n_splits)を「5」に設定し、データをシャッフル(shuffle=True)し、listでリスト化します。
(加えて、.splitでXに「 col_X (特徴量)」,Yに「col_Y (正解ラベル)」を代入)
※ リスト
データを一直線にまとめたもの (例:X= [ 3, 5, 8 ])
データをまとめることで、複数のデータにXという変数名でアクセス可能
folds = list(StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
.split(X=train_df[col_X], y=train_df[col_Y]))5.2 各foldのインデックスを確認
k-foldで分割したデータのインデックス(中身)を表示します。
(各fold毎にデータ(インデックス=行)が、学習用データ(train)と検証用データ(valid)に4:1の比率で5分割されているのが確認できます)
folds[0][0]
folds[0][0].shape
folds[0][1]
folds[0][1].shape
folds[1][0]
folds[1][0].shape
folds[1][1]
folds[1][1].shape
・folds[0][0]
5分割した1つ目(fold 0)の学習用データ(train)のインデックス (33,600行)
・folds[0][1]
5分割した1つ目(fold 0)の検証用データ(valid)のインデックス (8,400行)
・folds[1][0]
5分割した2つ目(fold 1)の学習用データ(train)のインデックス (33,600行)
・folds[0][1]
5分割した2つ目(fold 1)の検証用データ(valid)のインデックス (8,400行)
6. モデル構築
for文を用いて、各fold毎に以下の処理(モデル学習&予測)を繰り返し、予測結果を「Y_pred」に代入します。
・特徴量(X_train, X_valid)と正解ラベル(Y_train, Y_valid)を指定
・分類のアルゴリズムを定義 (今回はランダムフォレスト)
・モデルの学習 「.fit(X_train, Y_train)」
・検証データでの予測値「.predict(X_valid)」を算出し、Y_predに代入
※ for文でループさせる前に、np.zerosで予測結果を入れる「train_dfの長さ
(データ数)分の0行列の箱 (Y_pred)」を作成しておきます。
Y_pred = np.zeros([len(train_df)])
for (train_index, valid_index) in folds:
X_train = train_df[col_X].values[train_index]
X_valid = train_df[col_X].values[valid_index]
Y_train = train_df[col_Y].values[train_index]
Y_valid = train_df[col_Y].values[valid_index]
model = RandomForestClassifier(n_estimators=500)
model.fit(X_train, Y_train)
Y_pred[valid_index] = model.predict(X_valid)
Y_pred
7. モデルの評価
「正解ラベル (train_df [col_Y] )」と「予測値 (Y_pred)」の数字が一致したかどうかの真偽値(True(1) or False(0))を集計し、その平均値を求め、正解率(acc)とします。
acc = (train_df[col_Y]==Y_pred).mean()
acc
8. 予測
交差検証(k-fold)での正解率(識別成功率)は 約97% (acc≒0.97)、3%外れていますがまずまずの予測精度です。次は、このモデルを使ってテストデータの「label (識別したい数字)」を予測します。
8.1 テストデータの特徴量を抽出
テストデータ(test_df)の特徴量を抽出します。
test_X = test_df.iloc[:,2:]
test_X
8.2 識別したい数字(label)を予測
.predictにテストデータの特徴量(test_X)を入れて、「識別したい数字(label)」を予測します。
test_pred = model.predict(test_X)
test_pred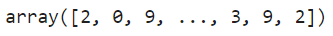
9. 提出ファイルの作成
以下の手順で、予測結果(test_pred)を提出ファイルに入れて、submit(提出)します。
9.1 提出用のテーブルを読込
pd.read_csvで提出用のテーブル(sample_submission.csv)を読込みます。
sub = pd.read_csv('/kaggle/input/digit-recognizer/sample_submission.csv')
sub
9.2 予測結果(test_pred)を挿入
提出用のテーブル(sub)のLabel列に「予測結果(test_pred)」を挿入します。
sub["Label"] = test_pred
sub
9.3 csv形式で保存
.to_csvで作成した提出ファイル(sub)を保存します。
※ kaggleのNotebookで提出ファイル(一連のコード)をSaveし、Submit(提
出)すると、スコア(正解率)が表示されます。
sub.to_csv("submission.csv", index=False)
10. まとめ
今回は、70,000枚の数字画像データ(MNIST)を用いて、正則化の前処理を行い、ランダムフォレストの学習モデル(手書き数字の識別装置)を構築しました。kaggleでのSubmit後のスコアは、交差検証(k-fold)時と同じく 約97% (acc≒0.97)、3%外れていますがまずまずの予測精度でした。
引き続き、色々な入門コンペにトライして、別の分析手法なども試してみようと思います。