
【Python】16 lines: csv module, tuple unpacking, cmp() built-in

プログラム
16行プログラムです。
もはや、どこがどう16行なのか、よくわからない(笑)。
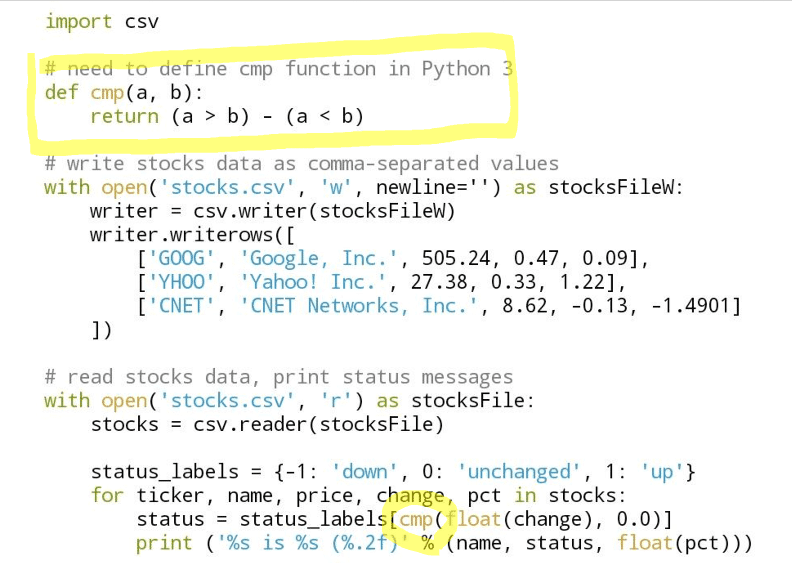
import csv
# need to define cmp function in Python 3
def cmp(a, b):
return (a > b) - (a < b)
# write stocks data as comma-separated values
with open('stocks.csv', 'w', newline='') as stocksFileW:
writer = csv.writer(stocksFileW)
writer.writerows([
['GOOG', 'Google, Inc.', 505.24, 0.47, 0.09],
['YHOO', 'Yahoo! Inc.', 27.38, 0.33, 1.22],
['CNET', 'CNET Networks, Inc.', 8.62, -0.13, -1.4901]
])
# read stocks data, print status messages
with open('stocks.csv', 'r') as stocksFile:
stocks = csv.reader(stocksFile)
status_labels = {-1: 'down', 0: 'unchanged', 1: 'up'}
for ticker, name, price, change, pct in stocks:
status = status_labels[cmp(float(change), 0.0)]
print ('%s is %s (%.2f)' % (name, status, float(pct)))実行結果
Google, Inc. is up (0.09)
Yahoo! Inc. is up (1.22)
CNET Networks, Inc. is down (-1.49)解説
タイトルは「16 lines: csv module, tuple unpacking, cmp() built-in」となっていて、「csv module」はわかるんだけど、「tuple unpacking」「cmp() built-in」が何を意味するのか、よくわからない。
cmp() built-in
Pythonドキュメントで「cmp」を検索してみたらPython3で廃止されたとあって、従って、『「cmp」を提議しなければなりませんよ』ということを言いたいのではないかと思われる。「cmp」を使いたいのなら作れ、と。
こんな風に。
「cmp」を使用しないという考え方はないのかしらん。
「cmp」関数についてはこちらにも追記。
【参考】Python3.0 での cmp
tuple unpacking
「tuple unpacking」に関するPythonの記述はこちら。
抜粋すると次のようになります。
>>> t = 12345, 54321, 'hello!'
>>> x, y, z = t
これは次のように、塊になっていたtupleをバラバラに分解します。
t = (12345, 54321, 'hello!')
x = 12345
y = 54321
z = hello!
「x, y, z = t」
のように書いてtupleを分解することを
「unpuck」
というようです。
それはわかったのだけど。
今回の16 lines プログラム上記のどこがそれにあたるのか。
tuple以外のシーケンス(lust、dictionary など)を加味しても該当箇所がわからない。
まぁ、いいか。
csv module
そして、おそらくはメインのCSV。
csv をインポート
まずはcsv をインポートします。
csvファイルをオープン
csvファイルをオープンします。

この時点ではcsv特有の処理はありません。
通常のファイルオープンと同じです。
強いて言えば第3引数の「newline=''」でしょうか。
Pythonドキュメントには、csvファイルをオープンするときは「newline=''」を指定しなければならないとあります。関数「open」のデフォルトは「newline=None」ですから、csvファイルをオープンするときには必ず「newline=''」を指定しなければならないということになります。
「newline」は改行コードを指定するもので、「newline=None」は改行コードがシステムのデフォルト os.linesep に変換されます。
一方、「newline=''」は変換されません。
「csvファイルを扱うときに「newline=''」を指定する」ということは、「改行コードはcsvに任せてファイルオブジェクトは何もするな」ということのようです。
newline についてはこちら。
csv writerオブジェクト
さて。
いよいよ csv 固有の処理になります。
csv のライターオブジェクトを取得します。

「csv.writer」の第1引数に指定しているのはファイルオブジェクト。戻り値で「csv writer object」を得ます。以降、この戻り値を利用してファイルをライトすることで、csv フォーマットをサポートできることになります。
面白い仕組みですね。
今回は第1引数にファイルオブジェクトを指定していますが、必ずしもファイルオブジェクトである必要はありません。イテレータプロトコルをサポートしていれば何でもいいようです。イテレータについてはこちらにも記載しました。
構造化設計であれば、ファイルオブジェクトを継承してcsvクラスを設計するでしょうか。でも、それだとファイルとの結び付きが強いですね。
ところが、Pythonのcsvは違います。「csv」と「ファイルオブジェクト」を接続するような感じです。「ファイルオブジェクト」でなくても「iterable」なオブジェクトであればなんでもつなぐことができる。
「csv」がのびのびと活躍する、そんな印象があります。
csvライト
csvファイルにライトします。

「writerオブジェクト」はファイルオブジェクトに接続されているので、接続されたファイルにcsvフォーマットでライトすることになります。
この例では、次のようなファイルが出力されます。
GOOG,"Google, Inc.",505.24,0.47,0.09
YHOO,Yahoo! Inc.,27.38,0.33,1.22
CNET,"CNET Networks, Inc.",8.62,-0.13,-1.4901「Google, Inc.」と「CNET Networks, Inc.」には「コンマ(,)」が含まれていますので、文字列は「""」で括られています。こういうような csv の性質を吸収してくれるのが、「csv module」の役割です。
csv reader オブジェクト
csv writer オブジェクトと同じような手順で、csv readerオブジェクトを取得します。

csv writerと違うところと言えば、'w' が 'r' に変化していること。これはわかります。ファイルを'w' ライトアクセスでなく、'r' リードアクセスしなければなりません。
もう一つは「newline=''」がないこと。
また悩ましいことを。
ですが、Pythonドキュメントのcsvのサンプルでは、reader も writer も 「newline=''」を指定しています。
reader も「newline=''」を指定した方がいいようです。
そして、このcsvのreaderオブジェクトは、for文でイテレータとして使われます。
赤でマーカーした部分ですね。
status_labels - 辞書 -

次の行は「status_labels」は、データ「change」を文字列で表現するための辞書です。
[-1]、[0]、[1]でアクセスすると次のような文字列になります。
status_labels[-1]=down
status_labels[0]=unchanged
status_labels[1]=upこの辞書を次のように使っています。
status = status_labels[cmp(float(change), 0.0)]複合文なのでわかりにくい。
一つずついきましょう。
まずはココ。
status = status_labels[cmp(float(change), 0.0)]
^^^^^^^^^^^^^「float(change)」は「change」を「float型」に変換します。
ん? あれ?
「change」って、「0.47」とか「0.33」とかだよね。
既に「float型」なんではないの?
なので調べてみた。
type(change)=<class 'str'>あ。
文字列か。
ふーん。
csv reader では数値変換まではしない、と。
確かに、必ず数値かというとそうとも限らないか。
数値変換までするのは越権行為かもしれない。
ようするにここでは文字列を浮動小数点に変換しているわけです。
次はココ。
status = status_labels[cmp(float(change), 0.0)]
^^^^^^^^^^^^^^^^^^^^^^^関数「cmp」を呼び出します。
「cmp」は「compare(比較)」する関数で、2つの値を比べて結果を返します。
結論だけ言うと、
change が 0.0 より大きければ 1
change が 0.0 より小さければ -1
change が 0.0 と同じであれば 0
となります。
そして、次のココ。
status = status_labels[cmp(float(change), 0.0)]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^これをさっき説明した「status_labels」と合わせると次のようになります。
change が 0.0 より大きければ 'up'
change が 0.0 より小さければ 'down'
change が 0.0 と同じであれば 'unchanged'
ようやく最終行。

最初の %s に name を
2番目の %s に status を
%.2f に float(pct) を
それぞれ表示します。
長かった・・・。
これだけ長いと読むのも面倒(笑)。
この記事が気に入ったらサポートをしてみませんか?