
【Python】20 lines: Prime numbers sieve w/fancy generators ~ジェネレータ関数~

プログラム
20行プログラムです。
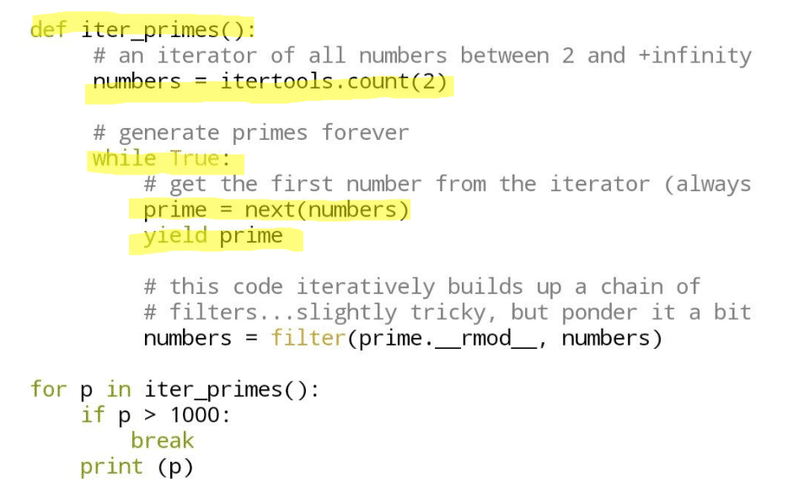
import itertools
def iter_primes():
# an iterator of all numbers between 2 and +infinity
numbers = itertools.count(2)
# generate primes forever
while True:
# get the first number from the iterator (always a prime)
prime = next(numbers)
yield prime
# this code iteratively builds up a chain of
# filters...slightly tricky, but ponder it a bit
numbers = filter(prime.__rmod__, numbers)
for p in iter_primes():
if p > 1000:
break
print (p)実行結果
2
3
5
7
11
13
17
19
23
29
31
37
41
43
47
53
59
61
67
71
73
79
83
89
97
101
103
107
109
113
127
131
137
139
149
151
157
163
167
173
179
181
191
193
197
199
211
223
227
229
233
239
241
251
257
263
269
271
277
281
283
293
307
311
313
317
331
337
347
349
353
359
367
373
379
383
389
397
401
409
419
421
431
433
439
443
449
457
461
463
467
479
487
491
499
503
509
521
523
541
547
557
563
569
571
577
587
593
599
601
607
613
617
619
631
641
643
647
653
659
661
673
677
683
691
701
709
719
727
733
739
743
751
757
761
769
773
787
797
809
811
821
823
827
829
839
853
857
859
863
877
881
883
887
907
911
919
929
937
941
947
953
967
971
977
983
991
997解説
連続して素数を発生するイテレータ。
なんだけど。
どうなってんの? これ
えーと、なになに?
このコードはフィルターのチェーンを繰り返し構築します...少しトリッキーですが、少し考えてみてください
と、書いてある、ようだ(多分)。
先が思いやられる。
まずは「yield」からかな。
馴染みのないキーワードやし。
また、時間かかりそうや。
yield
Python ドキュメントから yield 式に関する説明の抜粋です。
ジェネレータのメソッドが呼び出されると実行が開始されます。開始されると、最初の yield 式まで処理して一時停止し、呼び出し元へ expression_list の値を返します。ここで言う一時停止とは、ローカル変数の束縛、命令ポインタや内部の評価スタック、そして例外処理のを含むすべてのローカル状態が保持されることを意味します。
なるほど。
なんとなく・・・すごいな。
まずはこのマーカー部分からスタート。

ここで、 iter_prime を呼出していますので、 iter_prime に入ります。
iter_prime を先頭から順に実行して、 yield にぶつかったら呼出し元に戻ります。
呼出し元に戻って続きを実行します。
p はまだ 1000 に達していないので、for文 に戻ります。

for文 に戻ると再び iter_prime を呼出します。

今度は iter_prime の先頭からではなく、 yield の続きから実行します。

こちらもまた、 while に戻ります。
そしてまた yield にぶつかったら呼出し元に戻ります。

以下、繰り返しとなります。
filter
yield はわかった。
次は、 filter です。
「filter」という表現からなんとなくは想像するけど。
filter(function, iterable)
iterable の要素のうち function が真を返すものでイテレータを構築します。
今回の場合、次のようになっているから
numbers = filter(prime.__rmod__, numbers)「numbers」の要素のうち「prime._rmod_」が真を返すもので構築する(ダブルアンダースコアが違う表記になってしまうので、全角文字のアンダースコア1つに変えてます(以下同))
ということになります。
「prime._rmod_」って、なに?
「mod」は剰余。
「rmod」は逆剰余。
逆剰余!?
「r」は「reverse」の意味か。
えーと、
x._mod_(y) は x を y で割った余り。
x._rmod_(y) は y を x で割った余り。
なのだそうだ。
prime は直前に得た素数。
filter(prime._rmod_, numbers)
は
『numbers を prime で割った余りが真のもののみを抽出』
ということになります。
『余りが真』って?
余りは、 1 とか 2 とか 3 とかの数値で、真や偽とは違うよね。
でも、真と偽というのは、結局のところ次のように表現できます。
真:0でない
偽:0
『numbers を prime で割った余りが 0 でないもののみを抽出』
ということになるわけです。
itertools.count
「numbers」というのは、次のイテレータからスタートします。
numbers = itertools.count(2)「itertools.count」というのは、イテレータ生成関数で、次のようにあります。
itertools.count(start=0, step=1)
数 start で始まる等間隔の値を返すイテレータを作成します。
「itertools.count(2)」は、2 で始まり 1 ずつカウントした値を返すイテレータを作成します。
numbers = 2,3,4,5,6,7,・・・
次の文で、まず、 numbers から先頭を1つ取り出して prime = 2 となります。
prime = next(numbers)2 は素数ですので、次の文で 2 を呼出し元に返します。
yield prime再び戻ってきたときは、次の文が実行されます。
numbers = filter(prime.__rmod__, numbers)『numbers を prime で割った余りが 0 でないもののみを抽出』します。
『余りが 0 でないものを抽出』
とは、逆に言うと
『余りが 0 のものを取り除く』
ということです。
prime は 2 なので
『2 で割った余りが 0 のものを取り除く』
すなわち
『2 で割りきれるものを取り除く』
ということになります。
するとどうなるでしょう。
numbers = 2,3,4,5,6,7,・・・
から
『2 で割りきれるものを取り除く』
のですから
numbers = 3,5,7,・・・
となるのです。
試しにもう1回ループしてみましょう。
次の文で、今度は prime = 3 となります。
prime = next(numbers)3 は素数ですので、 3 を呼出し元に返します。
yield prime再び戻ってきたとき、次の文が実行されます。
numbers = filter(prime.__rmod__, numbers)今度は
『3 で割りきれるものを取り除く』
ということになります。
numbers = 3,5,7,9,11,13,15,・・・
から
『3 で割りきれるものを取り除く』
のですから
numbers = 5,7,11,13,・・・
となるのです。
上手くできてるなぁ。
filter 補足
例えば、こんなコードを書いてみた。
import itertools
# 2以上の自然数
numbers11 = itertools.count(2)
# 2の倍数を除去
numbers21 = itertools.count(2)
number = 2
numbers22 = filter(number.__rmod__, numbers21)
# 2の倍数と3の倍数を除去
numbers31 = itertools.count(2)
number = 2
numbers32 = filter(number.__rmod__, numbers31)
number = 3
numbers33 = filter(number.__rmod__, numbers32)
print('numbers11')
for p in numbers11:
if p > 20:
break
print ('%d,' % p, end='')
print()
print()
print('numbers22')
for p in numbers22:
if p > 20:
break
print ('%d,' % p, end='')
print()
print()
print('numbers33')
for p in numbers33:
if p > 20:
break
print ('%d,' % p, end='')実行結果はこうなる。
numbers11
2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,
numbers22
3,5,7,9,11,13,15,17,19,
numbers33
5,7,11,13,17,19,諸々考えてみた
「numbers」はイテレータなんだけど、どうなってんのか。
「itertools.count(2)」は、2 で始まり 1 ずつカウントした値を返すイテレータを作成します。この時に作成されるのはイテレータオブジェクトであって、数値列ではありません。そもそも、数値に上限の規定がないので、無限の数値列を作り出すことはできません。メモリ上に 2、3、4、・・・と値が記憶されているわけではない。
C言語で言うと
「2 で始まり 1 ずつカウントした値を返す関数のポインタが返る」
という感じでしょうか。「itertools.count(2)」で得られるのはオブジェクトです。
とすると、
filter(prime.__rmod__, numbers)は何をするんだろう。
既に数値を持ってるなら、その数値列から「prime._rmod_」の結果が0になる数値を除去すればいいのだけど、数値列を持ってるわけではない。すると、この filter を条件として持ってなきゃならない。
このサンプルコードは 1000 以下の素数を抽出するプログラムだけど、 1000 以下となると filter もそれなりの数になる。 168 個の素数が抽出されているから、 filter も 168 個ということになる。昨今の CPU で 168 個なんてのは小さいものではあるかもしれないけど。
filter 関数を全部記憶してるということかなぁ。
補足1
C言語で書くとどうなるかしら、と思ったりする。
「for ~ each」文もないし、「yield」もないから、全く同じものは作れないけど。
補足2
このジェネレータ関数というのは、おそらく「関数型」に近付こうとするものではないか。
と思われるのだか、違うか。
この記事が気に入ったらサポートをしてみませんか?