
【失敗と対策】Azure の Windows VMの診断ログを自動ローテーションさせる方法

こんにちは、アバナード関西オフィス)篠田です。
ちょっと地味なテーマですが、Azure の Windows VMのログローテーションについて、業務で必要に駆られて真面目に考えたので、記事にまとめてみます。
Azure でのインフラ関連のログ保存方法について
まず最初に、VM以外のPaaS等も含めた、Azureでのインフラ関連のログの保存方法について、代表的な方法を軽く説明します。
VMへのソフトウェア導入やAzure以外のクラウドサービスの利用も含めると、ログ保管ソリューションは無数に存在しますが、おそらくAzureで最もシンプルなのは次の2つです。
※Application Insights はインフラというよりはアプリ寄りなので、今回は取り上げませんが、こっちも過去にハマった事あるので、良かったら次の記事も読んでみてください。
1.Log Analytics ワークスペースへ保存する
Log Analytics は、Azure Monitor サービスの機能の一つとして位置付けられているログ分析ソリューションです。
Log Analytics ワークスペースをリソースとしてデプロイし、ログの保存先として設定すると、保存したログの検索・集計をワークスペース内で高速に実施でき、Azure Monitor でログをトリガーとしてアラートを発報することも可能になります。
ログの検索・集計には Kusto クエリ言語 (KQL) という、Microsoftが開発したクエリ言語を使う必要がありますが、SQLの select 文に似ていますし、Azure Portal の IntelliSense に従えば、あまり知らなくても何となく書けてしまうくらい、意外と簡単です。
Log Analytics ワークスペースでのログ検索・集計に慣れると、
「ああ、もう全てのログをずっとここに置いときたい…」
という感覚になってくるくらい扱いが楽なのですが、問題はコストと保存期間です。
Log Analytics ワークスペースの料金は、基本的には取り込んだログの容量に応じた従量課金制で、別途容量を事前購入して割引を受けるプランを選択しなかった場合、だいたい 350~400円/GB の料金がかかります。
これは単純なデータの保存容量に対する課金としては、かなり高額です。
また、ログの保存期間はデフォルトでは30日間で、保存期間を超えたログは自動的に削除されます。
31日間までは無料で延長可能で、それを超えての保存期間の延長には追加費用がかかり、最大730日間まで延長可能なのですが、いつかはログが必ず消えます。
上記の理由で、LogAnalytics ワークスペースはログの大容量・長期保存には向いていません。
運用にて「すぐに検索・集計・アラート出来るようにするべきログ」のみを、保存期間をある程度絞って収集する保存先、という位置付けになるかと思います。
2.ストレージアカウントへ保存する
ストレージアカウントへのログ保存は Log Analytics ワークスペースとは対照的で、「大容量のログを長期間保存する」事に関しては、コストの面で優れています。
基本的にPaaSのログはBLOBストレージ、VMのログはテーブルストレージに保存されるのですが、どちらも保存容量に対するGB/月単価が基本的に割安で、別途トランザクション数の課金が発生することを加味しても、Log Analytics ワークスペースよりはかなり安価にログを保存できます。
また、保存期間の上限もありません。
デメリットとしては、「ログの検索性が悪い」ことです。
BLOBストレージの場合は、オブジェクトストレージの特性上、一度保存したオブジェクトを後から部分的に読み書きする事ができない(丸々ダウンロード、アップロードするしかない)ので、JSON形式の、VM別かつ時間単位または分単位に細分化された容量の小さいオブジェクトの山としてログが保存されます。
この状態ではクエリで探索することは出来ませんし、かなりピンポイントに時刻が絞れていないと、対象のログにたどり着くことすら困難です。
BLOBに保存したログを本気で検索・集計したい場合は、Azure Data Explorer 等を利用して、JSONオブジェクトの山から1つのデータベースを成形し、クエリ出来る状態にした方が良いかと思います。
テーブルストレージの場合は、あらかじめ列のフィールドが定義された1つのテーブルを持つデータベースに行がどんどん足されていくような形で保存されます。
同じストレージアカウントを診断設定で指定すれば、指定した全VMのログがカテゴリごとに1つのテーブルに収集されます。
簡単なクエリを Storage Explorer のGUI操作等で指定してログを検索することは可能ですが、テーブルストレージの特性上、主キー(パーティションキー&行キー)以外の列にはインデックスが無いので、クエリ=ほぼ全探索(テーブルスキャン)になり時間がかかります。
ログを長期に保存してテーブルの行数が大量になると、クエリの結果が返ってこないうちにタイムアウトしてクエリ失敗、なんてことも良くあります。
Azure の Windows VM のログ収集で困った事
ここから本題というか、業務で困った事の話になるのですが、Azure のWindows VM で、ストレージアカウントへログ収集した際に、ログローテーション(期間指定してのログ削除)の運用ががなかなか組めなかったんです。
VMの診断設定を Azure Portal から実施すると、ストレージアカウントへOSのイベントログやパフォーマンスカウンターの情報(以下、診断ログ)を収集できるのですが、収集先はテーブルストレージで、テーブルストレージにはログローテーションの機能が標準では無いんですよね…
Log Analytics エージェント(最近は Microsoft Monitoring Agent に統合されている)を使って、Log Analytics ワークスペースにも同様の内容のログを収集する予定でしたが、そちらはあくまで短期保存の分析用であり、ストレージアカウントには長期保管目的で収集しようとしていました。
価格から考えると、VMリプレース後〇年経過とかでログが必要無くなるまで半永久保存することも選択肢に入るのでは、とも思うところですが、月額が単調増加し続けるシステムというのも何だか怖いので、一応 Log Analytics よりも長い保存期限をチームで決めて、保存期限超過分のログは何らかの方法で削除するよう、運用定義しました。
で、定期的にテーブルストレージの保存期限超過行を自動削除(ログローテーション)する仕組みは検討して、スクリプト化にトライはしたんですが、これが何とも難しかった…
タイムスタンプで削除対象の行を特定するために、Azure PowerShell でテーブルに対してクエリを実行すると、スクリプト実行するマシンのメモリが圧迫されて、いつまで経っても削除処理が完了しなかったり、スクリプトのプロセスがダウンしたりする事象が頻発して、解決出来なかったんですよね…
ならば月次で手動削除は?というのも考えましたが、そちらは「ログの手動削除は時間がかかりすぎて運用が回らない」という結論に至りました。
特にパフォーマンスカウンターのテーブルが厄介で、デフォルトのBasic設定で収集されてるだけで、VM一台あたり、1分間に40~50行ぐらい行が増えるんですよね…
Storage Explorer の一回のクリック操作で消せるのは最大1000行なので、イベントログ等の他のテーブルも含めて、これ月次で消し終わるまでに何回クリックすればいいんだろう…って考えたら絶望してしまいました。
Microsoftサポートに、何か良い方法が無いか一応問い合わせをしたところ、テーブルストレージのログローテーションを実現する、とあるOSSが紹介されているサイトの情報を提供いただけました。
ただ、この「AzureTablesLifecycleManager」は、マイクロソフトが作成・監修しているソフトウェアではなく、使用して何か不具合が起こった場合は完全に自己責任になるので、業務でこれを利用するのには躊躇いがあり、結局使用はしませんでした。
ここまで調べて、テーブルストレージの扱い方については理解が深まったので、今やればPowershellでの自動ローテーションスクリプトも、テーブルクエリを使用しない方法(テーブルのリネーム・新規作成・削除だけでローテーションする)で実装できそうではあるのですが、今回はそれよりも簡単な自動ログローテーションの実装方法を見つけたので、紹介します。
解決策:保存先をテーブル→BLOBに変える
困って色々調べなおしたところ、Azure の Windows VM の診断ログの保存先として、実はテーブルストレージだけではなくBLOBストレージも選択可能であることが分かりました。
Microsoft Docs に、小さく書いてあったんですよ…
テーブルに格納されているデータは、パブリック構成の StorageType 設定に応じて BLOB に保存することもできます。
Azure Portal からは設定できないのですが、診断設定のconfigファイルをコマンドで流し込むことによって、診断ログの保存先はテーブル→BLOBに変更可能です。
BLOBだと何が良いって…Standard V2 以上ならライフサイクル管理機能(最終更新日時等に応じてオブジェクトを自動削除したり、保存するストレージ層を自動変更したり出来る機能)が備わってるんですよね。
ログがJSONで保存される分、テーブルの時に比べて少し読みにくく、検索性も下がりますが、即時見れる事を目的としない長期保存用であれば、BLOBでも別に良いですよね。
PaaSも知る限りBLOBに診断ログ保存するサービスばかりですし、むしろ何でVMだけテーブルを基本としているのかは、Azure 歴1年未満の私には良く分からない部分です。
ライフサイクル管理の設定は Azure Portal だけで出来て簡単ですが、テーブル→BLOBの所はちょっと分かりにくかったので、私が実施した手順を、自身の備忘録として残しておきます。
手順:テーブル→BLOBに変える方法
まず、CloudShell(PowerShell)を開き、次のコマンドを実施します。
※Azure PowerShell が利用出来れば、ローカルPCの PowerShell から Azure のサブスクリプションにログオンした状態で実行しても問題ありません。
$myResourceGroup = "<VMのいるリソースグループ名を入力>"
$myVM = "<VMのリソース名を入力>"
$diagExt = Get-AzVMDiagnosticsExtension -ResourceGroupName $myResourceGroup -VMName $myVM
$diagExt.PublicSettings > $myVM-before.json
Copy-Item -Path $myVM-before.json -Destination $myVM-after.json※「$myVM-before.json」は、設定変更前の設定のバックアップとして、差分確認等に利用してください。
生成した「$myVM-after.json」ファイルを次のように編集します。
※ここではcodeエディタを使用していますが、エディタは何でも構いません。
code $myVM-after.json
===========================================
{
"StorageType": "Blob", ←この一行を追加する、デフォルトでは"Table"を示す行は存在しない
"StorageAccount": "myVMdiagstorage",
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": 5120,
・
・
・
}
===========================================
Ctrl + S で保存する
Ctrl + Q でエディタを閉じる
diff $myVM-before.json $myVM-after.json
===========================================
1a2
> "StorageType": "Blob", ←この一行しか差異が無い事を確認する
===========================================最後に、次のコマンドを実行して、設定を反映すれば完了です。
※VMの再起動等は発生しませんが、私は念のため安全な時に実施しました。
Set-AzVMDiagnosticsExtension -ResourceGroupName $myResourceGroup -VMName $myVM -DiagnosticsConfigurationPath $myVM-after.json
===========================================
RequestId IsSuccessStatusCode StatusCode ReasonPhrase
--------- ------------------- ---------- ------------
True OK OK ←True OK OK と正常ステータスが出力された事を確認する
===========================================以上で、テーブル→BLOBへの診断ログ保存先変更は完了です。
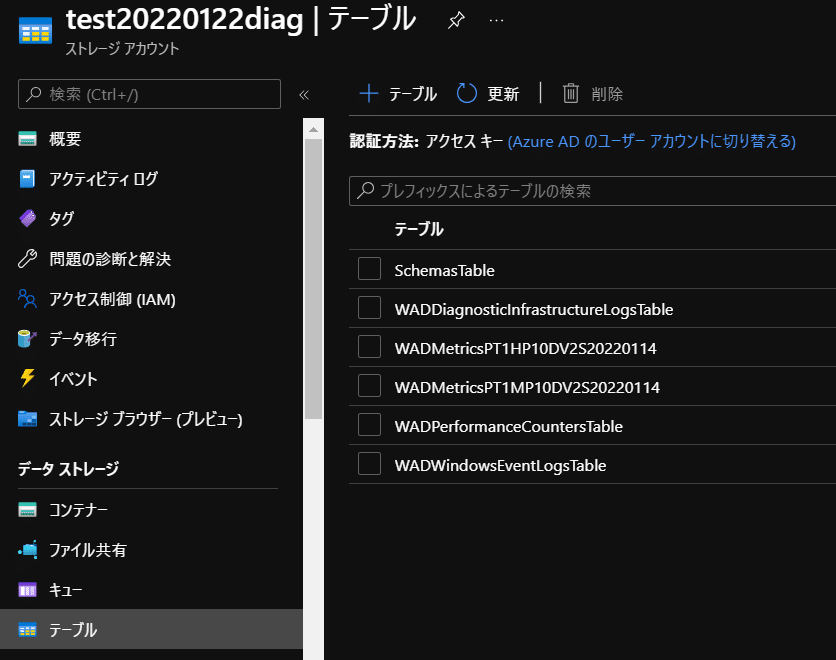
↑設定変更前まで収集されていた診断ログのテーブル。
これはそのままなので、対象のストレージアカウントでテーブルに診断ログを収集しているVMがいなくなって、決めた保存期間を過ぎたら、テーブルごと削除すれば良いかと思います。
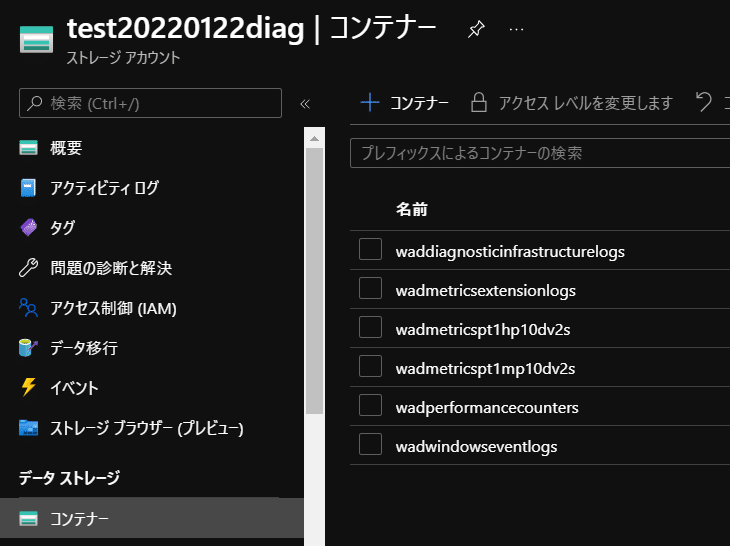
↑設定変更後に収集され始めた診断ログのBLOBコンテナー。
以後はずっとこちらにログが収集されます。
生成された各コンテナー名をプレフィックスにして、ライフサイクル管理ポリシーを設定したら、自動ログローテーションの完成です。
注意点:Linux VM は別途考慮が必要
1点、注意点ですが、前項に記載した方法はあくまで Windows VM の場合のログローテーション方法であり、Linux VM は別途考慮が必要です。
というのも、Linux VM の場合は、診断ログは現状テーブルストレージへの収集は必須(BLOBは任意で追加可能)という扱いで、Windows VM とはちょっと勝手が違うんですよね…
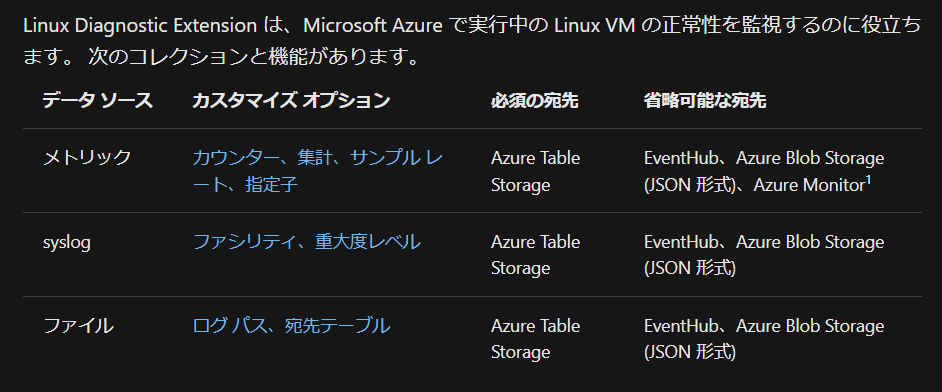
Linux VM の長期保存ログのローテーションに在り物で対処するのであれば、次の4つの方法が想定されます。
①テーブルストレージに収集し、スクリプトでローテーションする。
②BLOBに収集するオプションを有効化し、BLOBのライフサイクル管理でローテーションを構成する。テーブルストレージ側は別途スクリプトで定期的に全削除する。
③ストレージアカウントにログ収集するのやめて、OSのログローテーション機能を利用してマネージドディスク内でローテーションする。
④ログローテーションするのは諦めて、テーブルストレージには永久保存する事とし、真に必要なログの種類・ログレベルを診断設定の段階でミリミリ精査する。
個人的には、スクリプト化しなくても出来ることを、わざわざお手製スクリプトにして障害箇所増やすのは良くないと思っているので、③か④を選択します。
③についてですが、VMのマネージドディスクはストレージアカウントに比べれば容量課金は割高ですが、それでも Log Analytics に同量保存するのに比べればはるかに安いはずです。
OSで長期ログ保存する前提であれば、ログはOSログインすればいつでもさっと見れるので、Log Analytics で収集するログは、集計やアラートに使うものにもっと限定して、コストダウンを狙ってもよいと思います。
Linux の logrotate は cron デーモンと連携して動作するので、標準設定でも週次ローテーション等で割と賢く動くし、パラメータをカスタマイズすれば色々柔軟にログローテーションのスケジュールが組めます、過去のログファイルを圧縮して容量削減する機能があるのも大きいです。
Linux の台数が多いのであれば、一元管理のために rsyslog 等でログ収集サーバを構築しても良いかもしれません。
Windows のイベントログは「設定容量上限に到達したら過去のログが順に消える」という仕様で、OSのディスク容量圧迫への耐性は高い反面、保存期間を指定出来ないため運用者としては制御に困る部分があります。
今回はログ収集サーバも無かったので、長期保存先としてはストレージアカウントに頼らざるを得なかった、という感じでした。
まとめ:クラウドでもVMは相変わらず難しい
最後にまとめですが、見出しの一言に尽きますね…
今回私が紹介した設定方法や考えはあくまで一例であり、冒頭に書いたように「他のVMに導入可能なソフトウェアや他のクラウドサービスは一旦無視している」ので、もっと良い解決方法は無数に湧き出てくる可能性があります。
Azure の PaaS を利用したログ収集方法や他のクラウドサービスは、オンプレでVMを扱っていた時には存在しなかった選択肢であり、それらも含めて、環境に準備出来るものでベストアンサーを出す必要がある現状を考えると、VMの構築に必要な時間はクラウド化によって削減されたものの、設計難易度はむしろ上がっているのでは?と思わなくもないです。
ハイパーバイザーの設計・構築・運用をしなくて良いのは嬉しいんですけどね…
ただ、オンプレだろうとクラウドだろうと変わらず重要なのは、VM上のOSそれぞれの仕様と、OSによる周辺ソフト・サービスの動作の違いをちゃんと理解して対応する事だと私は考えています。
まだまだOSはマスターしたとはとても言い難いので、この先も Azure と共に仲良く付き合って、学んで行きたいなと思います。
この記事が皆さんのお役に立てましたらいいねやフォローをお願いします。
内容に関するご指摘や、その他何かございましたら下記に連絡ください。
アバナード関西オフィス 篠田 諭
satoshi.shinoda(@)avanade.com
この記事が気に入ったらサポートをしてみませんか?