ChatGPTがarXivの新着論文を翻訳・要約し毎朝メールしてくれる。;ChatGPT translates and summarizes new arXiv articles and emails them to you every morning.

1.はじめに
今回は、以下の記事を参考にして作りました。
参考の記事ではPubMedを使っていますが、私はarXiv(アーカイブ)を使いました。arXivとは、物理学、数学、コンピュータサイエンスなどの分野の学術論文を無料で配布し、オープンアクセスで公開するサービスです。arXivには、最新の研究成果や未査読のプレプリントが多数掲載されており、研究者や学生にとって貴重な情報源となっています。
この記事では、arXivから特定のキーワードに関する新着論文を検索し、その内容を要約してメールで送信するという仕組みの作り方を紹介します。この仕組みを利用すれば、自分の興味や関心に合った最新の研究動向を簡単にキャッチアップすることができます。また、この仕組みは、前述のスライドで紹介されたGoogle Apps Script(GAS)という自動化サービスを使って作成することができます。
2.実際のコード(GAS)※4/17修正
以下は、そのコードです。コピーして使ってください。
// OpenAI の API keys (https://platform.openai.com/account/api-keys)
// スクリプトプロパティにAPIキーを保存するには、スクリプトエディタで「ファイル」>「プロジェクトのプロパティ」>「スクリプトプロパティ」を選択し、OPENAI_API_KEYとしてAPIキーを追加してください。
// スクリプトプロパティに保存された OpenAI の API keys を取得
const OPENAI_API_KEY = PropertiesService.getScriptProperties().getProperty("OPENAI_API_KEY");
// 結果メールの送信先
// 送信先のメールアドレスを指定してください。
const EMAIL_RECIPIENT = "example@gmail.com";
// 結果メールのタイトル
const EMAIL_SUBJECT = "arXivの新着論文の要約";
// 結果メールの送信者の名前
const EMAIL_SENDER = "arXiv論文要約bot";
// 検索クエリ
const QUERY = "ChatGPT";
// 検索対象日数
const TERM = 1;
// 検索時のヒット論文で要約する論文の本数の上限
const MAX_PAPER_COUNT = 2;
// ChatGPT に渡す命令
const PROMPT_PREFIX = "あなたは情報教育、テクノロジーに詳しい教師です。以下の論文を、タイトルと要約の2点をそれぞれ改行で分けて、専門用語を使わず、簡素で平易な日本語で説明してください。要点は箇条書きでお願いします。";
function main() {
if (!OPENAI_API_KEY) {
console.log("ERROR: OPEN_API_KEY を指定してください");
return;
}
const fromDate = getDateBeforeDays(TERM);
const toDate = getDateBeforeDays(0);
console.log(`検索範囲の開始日: ${fromDate}`);
console.log(`検索範囲の終了日: ${toDate}`);
const arxivPapers = getArxivPapers(QUERY, fromDate, toDate);
console.log(`取得された論文数: ${arxivPapers.length}`);
const papers = arxivPapers;
let output = "新着論文のお知らせ\n\n";
let paperCount = 0;
if (papers.length === 0) {
output += "指定された期間内に、検索クエリに一致する新しい論文は見つかりませんでした。\n\n";
} else {
for (let paper of papers) {
if (++paperCount > MAX_PAPER_COUNT) break;
console.log(`論文${paperCount}: ${paper.title}`);
const title = paper.title;
const abstract = paper.abstract;
const url = paper.url;
const input = "\n" + "title: " + title + "\n" + "abstract: " + abstract;
const res = callChatGPT(input);
console.log(`ChatGPTからのレスポンス: ${JSON.stringify(res, null, 2)}`);
const paragraphs = res.choices.map((c) => c.message.content.trim());
output += `${paragraphs.join("\n")}\n\n${url}\n\n\n`;
}
}
output = output.trim();
console.log(`最終結果: ${output}`);
sendEmail(output);
}
function getDateBeforeDays(days) {
const date = new Date();
date.setMinutes(date.getMinutes() - date.getTimezoneOffset());
date.setDate(date.getDate() - days);
return date.toISOString().split("T")[0];
}
function getArxivPapers(query, fromDate, toDate) {
const url = `http://export.arxiv.org/api/query?search_query=${query}&start=0&max_results=20&sortBy=submittedDate&sortOrder=descending`;
const options = {
muteHttpExceptions: true,
};
const xmlText = UrlFetchApp.fetch(url, options).getContentText();
const document = XmlService.parse(xmlText);
const root = document.getRootElement();
const entries = root.getChildren("entry", XmlService.getNamespace("http://www.w3.org/2005/Atom"));
const papers = entries
.map((entry) => {
const title = entry.getChild("title", XmlService.getNamespace("http://www.w3.org/2005/Atom")).getText();
const abstract = entry.getChild("summary", XmlService.getNamespace("http://www.w3.org/2005/Atom")).getText();
const id = entry.getChild("id", XmlService.getNamespace("http://www.w3.org/2005/Atom")).getText();
const published = entry.getChild("published", XmlService.getNamespace("http://www.w3.org/2005/Atom")).getText();
return {
title: title,
abstract: abstract,
url: id,
published: published,
};
})
.filter((paper) => {
const publishedDate = new Date(paper.published);
const from = new Date(fromDate);
const to = new Date(toDate);
to.setDate(to.getDate() + 1);
return publishedDate >= from && publishedDate < to;
});
console.log(`フィルタリング後の論文数: ${papers.length}`);
return papers;
}
function callChatGPT(input) {
const messages = [
{
role: "user",
content: PROMPT_PREFIX + "\n" + input,
},
];
const url = "https://api.openai.com/v1/chat/completions";
const options = {
"method": "post",
"headers": {
"Authorization": `Bearer ${OPENAI_API_KEY}`,
"Content-Type": "application/json",
},
"payload": JSON.stringify({
model: "gpt-3.5-turbo",
messages,
}),
};
return JSON.parse(UrlFetchApp.fetch(url, options).getContentText());
}
function sendEmail(body) {
const options = { name: EMAIL_SENDER };
GmailApp.sendEmail(EMAIL_RECIPIENT, EMAIL_SUBJECT, body, options);
}
必要な設定は、APIキーとメールアドレスだけです。

以下の項目は、検索クエリ(論文の検索に使うキーワード)、対象日数、論文数の上限、ChatGPTに渡す命令文の設定です。必要に応じて書き換えてください。

ただ、APIキーは使用料がかかっていますので、お気を付けください。以下に、以前紹介したAPIキーの取得方法についての記事を載せておきます。2.APIの利用料金(無料期間あり)からAPIキーの取得方法について説明しています。
3.作成手順
Googleドライブの任意の場所から、左上の「新規」ボタンをクリックすると、以下のように新しいスクリプトファイルを作成することができます。


Google Apps Script(GAS)でChatGPTのAPIをリクエストするにあたって、事前準備があります。
GASスクリプトプロパティに前述した手順で取得したChatGPTのAPIキーを設定することです。
APIキーはGASスクリプトに直書きすることもできますが、スクリプトをGithubなどで管理する際に流出する恐れがあります。
そのため、GASではスクリプトプロパティにAPIキーを格納して、コードからスクリプトプロパティを読み込むのがオススメです。
スクリプトエディタを開いたら、左メニューにある「プロジェクトの設定」をクリックします。
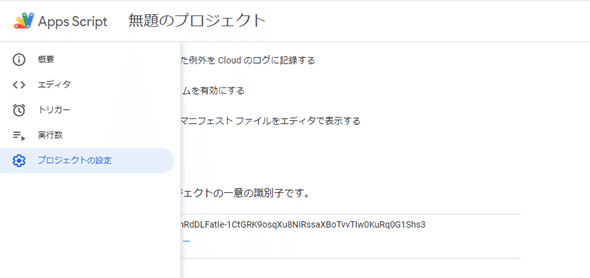
プロジェクトの設定画面をスクロールするとスクリプトプロパティの項目が表示されるので、「スクリプトプロパティを追加」を選択します。プロパティに「OPENAI_API_KEY」と入れて、値に事前に取得したChatGPTのAPIキーをコピペし、「スクリプトプロパティを保存」をクリックします。
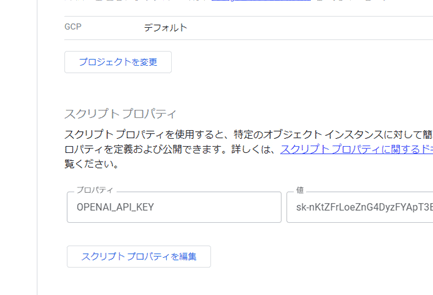
毎日メールが届くように、トリガーを追加します。
Google Apps Script左のリストから「トリガー」をクリックして、画面右下の「トリガーを追加」をクリック

日付ベースのタイマーにして時間を指定すると、希望する時間にメールを届けてくれます。
4.実際のメール内容
成功すると以下のようなメールが届きます。
新着論文のお知らせ
タイトル: AGIEval:人間中心の基礎モデル評価指標
要約:
- AGIの追求において、基礎モデルが人間レベルのタスクに対処する能力を評価することは重要です。
- 人工的なデータセットに依存する従来のベンチマークは、人間レベルの能力を正確に表現できない可能性があります。
- 本論文では、大学入試試験、法科大学院入学試験、数学コンペティション、弁護士資格試験などの人間中心の標準化された試験の文脈で、基礎モデルを評価するために特別に設計された新しい基準であるAGIEvalを紹介しています。
- このベンチマークを使用して、GPT-4、ChatGPT、Text-Davinci-003などの最先端の基礎モデルを評価しました。
- GPT-4は、SAT、LSAT、数学コンペティションの平均人間のパフォーマンスを超え、SAT Mathテストで95%の正確率、中国の国家大学入試試験の英語テストで92.5%の正確率を達成する驚異的なパフォーマンスを示しました。
- 一方、複雑な推論または特定の領域知識を必要とするタスクにおいて、GPT-4は低いパフォーマンスを示しました。
- モデルの能力(理解、知識、推論、計算)の包括的な分析により、これらのモデルの強みと限界が明らかになり、将来の方向性を示唆しています。
- 人間の認知と意思決定に関連するタスクに重点を置くことで、私たちのベンチマークは実世界のシナリオでの基礎モデルのパフォーマンスをより意味のある・堅牢な評価を提供します。
- データ、コード、およびすべてのモデル出力は、https://github.com/microsoft/AGIEvalで公開されています。
http://arxiv.org/abs/2304.06364v1
タイトル: 偽の生成された科学論文要約の検出
要約:
- 大規模言語モデルや公開されたChatGPTなどの人工知能の技術革新の普及により、人々の日常生活に人工知能が融合される大きな転換点が訪れた。
- 学術コミュニティはこれらの技術革新に注目し、人工的に生成されたものと現実のものを区別することの困難さについて懸念を表明している。
- そのため、研究者たちはマシン生成テキストを識別する効果的なシステムを開発するために取り組んでいる。
- この研究では、GPT-3モデルを利用して、人工知能によって科学論文の要約を生成し、機械学習モデルと組み合わせたさまざまなテキスト表現方法を探索して、機械によるテキストを識別することを目的としている。
- モデルの性能を分析し、結果の分析中に生じるいくつかの研究課題に取り組んでいる。
- この研究により、人工知能による生成テキストの可能性と限界を明らかにしている。
http://arxiv.org/abs/2304.06148v1
5.おわりに
繰り返しになりますが、arXivは物理学や数学などの分野におけるプレプリント(査読前の論文)を公開するウェブサイトです。arXivには100万件以上の論文が登録されており、最新の研究動向を知ることができます。しかし、arXivを活用する際には、以下のような注意点があります。
arXivに掲載された論文は、査読されていない場合が多いです。そのため、内容の正確さや信頼性については自分で判断する必要があります。論文の内容に疑問や不明点がある場合は、著者に直接連絡するか、他の文献と照らし合わせることが大切です。
arXivから論文を引用する場合は、通常の論文と同様に記載する必要があります。ただし、arXivにはバージョン管理がされており、同じ論文でも更新されることがあります。そのため、引用する際には、arXivの識別番号やアクセス日を明記することが推奨されます。
arXivに掲載された論文は、後に査読付きのジャーナルや会議で発表されることがあります。その場合、内容や形式が変更されることがあります。そのため、arXivで見つけた論文に興味がある場合は、最終的な出版物を確認することも忘れないでください。
以上が、arXivを活用する際の注意点です。arXivは素晴らしいリソースですが、利用者自身が情報を批判的に吟味することも必要です。arXivを上手に使って、研究や学習に役立ててください。
arXiv - Wikipedia. https://ja.wikipedia.org/wiki/ArXiv アクセス日時 2023/4/16.
(2) arXiv利用方法 - 公立はこだて未来大学 - 情報ライブラリー - FUN. https://library.fun.ac.jp/?page_id=3143 アクセス日時 2023/4/16.
(3) arXivに掲載された論文を引用する方法を紹介 | お役立ち .... https://acaric.jp/articles/column/2746 アクセス日時 2023/4/16.