
Akira's ML news summary #October 2020

2020年10月に投稿された論文や記事で特に面白かったものを紹介します。
また、厳密には9月末の公開ですが今月はICLR2020の論文を紹介しています。
今月の注目記事/論文
- PCAをゲーム理論で解釈し、分散化で効率化
- EfficientNetより高速/高精度なLAMBDANETWORKS
- Paddingによる精度の位置依存性
- 少数データ、小計算時間で高解像度画像を生成するGAN
- なぜ宝くじ初期値を使わないと疎なネットワークの学習は失敗するのか
- TransformerでCNNベースのモデルを超える
- 教師あり学習の観点から強化学習を見てみる
- データサイエンティスト面接の120以上の想定質問とその回答
- 2020年の人工知能発展のレポート
- 画像データセットに潜む偏見を特定
過去の記事
Week 41の記事, Week 42の記事, Week 43の記事, Week 44の記事
2020年9月のまとめ
内容 :
1. 論文, 2.技術的な記事等, 3. 実社会における機械学習適用例, 4. その他話題
---------------------------------------------------------------------
1. 論文
----------
少数データ、小計算時間で高解像度画像を生成するGAN
TOWARDS FASTER AND STABILIZED GAN TRAINING FOR HIGH-FIDELITY FEW-SHOT IMAGE SYNTHESIS
https://openreview.net/forum?id=1Fqg133qRaI
少数データ(100~1000)かつ小計算量(1GPUx十数時間程度)で高解像度(256^2~1024^2)をゼロから学習/生成できるGAN。各解像度の情報を組み合わせるSLEモジュールと、Discriminatorの中間特徴量マップから再構成を行わせる制約で強化することが技術的な肝。

層を入れ替えることでスタイル変換を行う
Resolution Dependent GAN Interpolation for Controllable Image Synthesis Between Domains
https://arxiv.org/abs/2010.05334
学習済みStyleGANを用いたスタイル変換の研究。新たなデータセットで転移学習したStyleGANの浅い部分と通常の学習済みStyleGANの深い部分を入れ替えることで、スタイル変換を行うGAN。写真をディズニー風に変換することが可能。

TransformerでCNNベースのモデルを超える。
N IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
https://openreview.net/forum?id=YicbFdNTTy
Transformerは帰納バイアスがCNNと比較して少ないためImageNetなどの中規模なデータセットで学習すると上手くいかない。そのため、大規模なJET-300Mデータセットで事前学習する戦略をとる。画像をパッチ分割し、それぞれのパッチを文書だと思って処理する。BiT-LやNoisy Studentを超える、または匹敵する結果。youtubeの解説動画が非常にわかりやすい。

PCAをゲーム理論で解釈し、分散化で効率化
EigenGame: PCA as a Nash Equilibrium
https://arxiv.org/abs/2010.00554
PCAを各固有ベクトルが自身の効用関数を最大化するゲームをしていると解釈し、ナッシュ均衡状態でPCAが成立することを示した。これは分散化可能なアルゴとして実装することができるため、大規模なニューラルネットワークの解析を実施することができた。AEでも同じようなことはできるが、主成分を回復することと等価でもないし、disentangleもできないため、重要な結果。

GANを確率微分方程式として解釈し、CIFAR10でFID2.2を達成
SCORE-BASED GENERATIVE MODELING THROUGH STOCHASTIC DIFFERENTIAL EQUATIONS
https://openreview.net/pdf?id=PxTIG12RRHS
ノイズを摂動させて画像を生成する通常の生成モデルと異なり、確率微分方程式を用いてノイズが時間的に発展する連続体を考える。それの過程を逆にすることでノイズから画像を生成する。CIFAR10においてIS 9.9, FID 2.2を達成し、さらに1024x1024サイズの画像も生成可能。

深いVAEで自己回帰モデルを超える
VERY DEEP VAES GENERALIZE AUTOREGRESSIVE MODELS AND CAN OUTPERFORM THEM ON IMAGES
https://openreview.net/forum?id=RLRXCV6DbEJ
78層など非常に深いVAEでPixelCNNなどの自己回帰モデルやFlow系モデルに匹敵する結果を出した研究。自己回帰系がVAEより良い理由はネットワークの深さにあることを示し、大きな勾配は無視/事後分布学習は後半から開始するなど深化に伴う学習難度の向上を克服した。潜在変数次元数によって髪質など画像の情報量を操作することができる。

宝くじ仮説 in GAN
GANS CAN PLAY LOTTERY TICKETS TOO
https://openreview.net/forum?id=1AoMhc_9jER
GANにおいて宝くじ仮説が適用できるかを調べた研究。GANにも宝くじサブネットワークが存在し、精度を保ったまま圧縮できた。また、Generatorと同時にDiscriminatorを圧縮する要否はあまりなかった一方、Discriminatorの初期値は重要であることがわかった。応用上の観点からGeneratorの圧縮は試みられてきたが、Discriminatornの圧縮は試みられてなかったで、それを試したのが貢献。

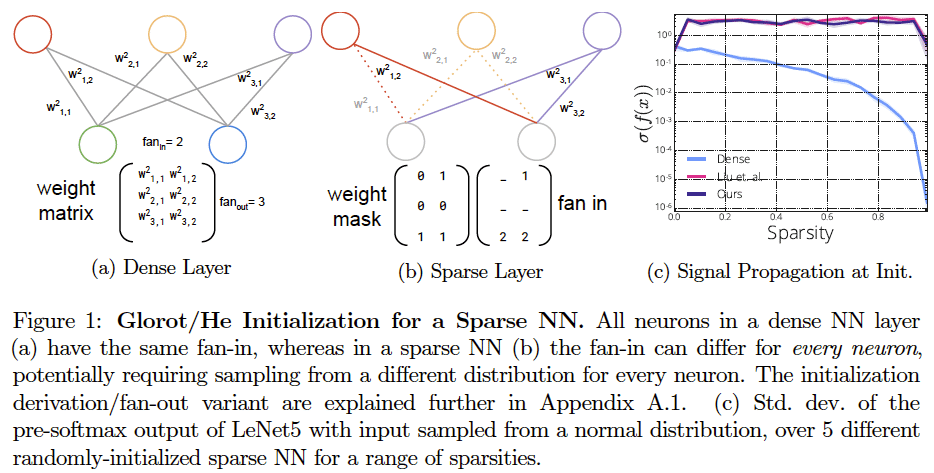
なぜ宝くじ初期値を使わないと疎なネットワークの学習は失敗するのか
Gradient Flow in Sparse Neural Networks and How Lottery Tickets WinGradient Flow in Sparse Neural Networks and How Lottery Tickets Win
https://arxiv.org/abs/2010.03533
疎なNNにおいて、宝くじ初期値とランダム初期値の精度の差分がどこから来るかを検証した研究。ランダムに初期化された疎なネットワークは勾配流の悪化(勾配の値が小さく消失しやすい)ため密なネットワークより精度が悪い。宝くじ初期値は勾配流を改善しないが、枝刈ネットワークのバイアスがかかっているため上手く学習できる。動的に疎なネットワークを学習できるRigL等は勾配流を改善できるため、ランダム初期値から良い精度を出すことができる。
sharp minimaに陥いることを防ぐ最適化手法
Sharpness-Aware Minimization for Eciently Improving Generalization
https://arxiv.org/abs/2010.01412
損失関数が sharp minimaに陥いることを防ぐように、モデルのパラメータに損失が最も上昇するような摂動を加えた上で最適化を行うSAMを提案。汎化性能が向上し、ラベルノイズにも頑健であることを確認した。

積分カーネルの計算をニューラルネットで実施
Fourier Neural Operator for Parametric Partial Differential Equations
https://arxiv.org/pdf/2010.08895v1.pdf
フーリエ空間における積分カーネルの計算をニューラルネットワークで代替させる研究。Navier-Stokes方程式等の流体シミュレーションに適用した結果、数値シミュレーション(FEM)に比較して最大1000倍以上の高速化を実現した。

EfficientNetより高速/高精度なLAMBDANETWORKS
LAMBDANETWORKS: MODELING LONG-RANGE INTERACTIONS WITHOUT ATTENTION
https://openreview.net/forum?id=xTJEN-ggl1b
画像に自己注意を適用する場合は画素毎AttentionとQueryの行列積で潜在表現を得るが、場所によらず固定されたkeyとvalueでの行列積で抽象化されたマップとQueryを掛け合わせることによって潜在表現を得るLambda Layerを提案。EfficientNetより高速/高精度な結果。

自己教師あり学習手法SimCLRやBYOLを理論的解析
Understanding Self-supervised Learning with Dual Deep Networks
https://arxiv.org/abs/2010.00578
対のネットワークをもつ自己教師あり学習手法SimCLRやBYOLを理論的に解析した研究。これらは強力なデータ拡張をしても残る特徴を共分散演算子によって増幅することで学習していると提唱。またBYOLは予測器を数エポック毎に初期化しても精度が落ちないことを発見。

自由エネルギーの計算を深層学習で実施
Targeted free energy estimation via learned mappings
https://aip.scitation.org/doi/10.1063/5.0018903
溶媒効果や酵素反応をシミュレーションする自由エネルギー摂動法(FEP)を深層学習を用いて行う研究。周期対称性などの物理的な制約を課したモデルを提案し、自由エネルギー推定値の分散を大幅に下げることに成功した。

巨大なtext2text多言語モデル
mT5: A massively multilingual pre-trained text-to-text transformer
https://arxiv.org/abs/2010.11934
あらゆるタスクをtext2textの形式に統一し、事前学習→Fine-tuneの戦略をとるT5を多言語で実施したmT5と大規模で101言語を含む多言語データセットmC4を提案。最大で130億のパラメータを持ち、色々なタスクで最高性能。

因果グラフを利用した自己教師あり学習
REPRESENTATION LEARNING VIA INVARIANT CAUSAL MECHANISMS
https://arxiv.org/abs/2010.07922
画像がコンテンツ(動物種)とスタイル(背景など)の因果グラフで画像が構築されると考え、スタイルに対して不変にするように学習させる自己教師あり学習RELICを提案。具体的にはデータ拡張によるスタイル変換に不変になるように、個々の画像の分類と分布の一致を行わせる。先行研究を匹敵するだけでなく強化学習でも効果があった。

Paddingによる精度の位置依存性
MIND THE PAD – CNNS CAN DEVELOP BLIND SPOTS
https://arxiv.org/abs/2010.02178
paddingの適用の不均一性が位置依存性を生み、精度の低下を招いているという研究。ResNetのようにstride=2でダウンサンプルするネットワークは画像サイズによってはpadding画素が均等に使用されず、特徴量マップに不均一性を産む。(下左図の左端のpaddingは畳み込まれるが右端のpaddingは畳み込まれない)。これを均等になるように画像サイズを変えるだけで、精度が向上した。

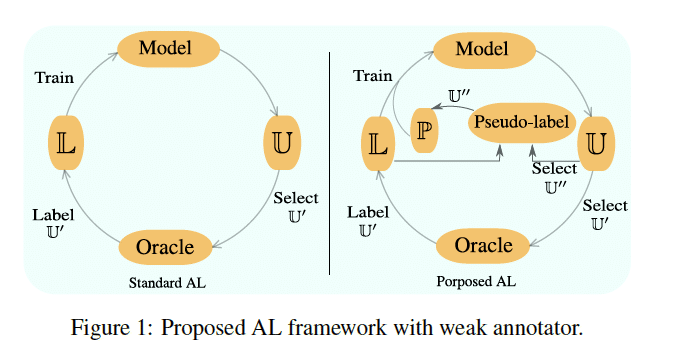
アクティブラーニングでセグメンテーション学習して可視化
Deep Active Learning for Joint Classification & Segmentation with Weak Annotator
https://arxiv.org/abs/2010.04889
一部しかマスクが存在しないラベル有りデータにおいて、分類とセグメンテーションを同時に行いながらActive Learningでマスクありデータを徐々に増やしていく手法を提案。CAMより可視化性能が良くなる
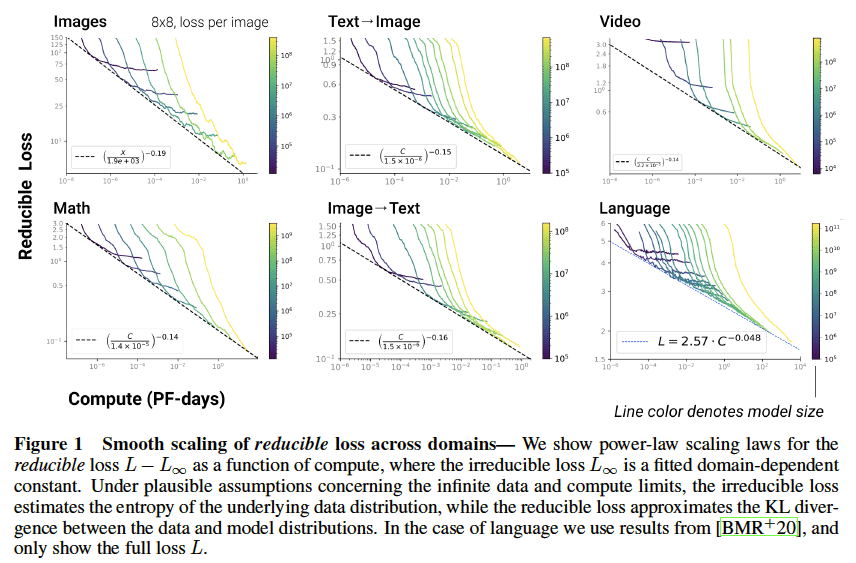
様々なデータドメインにおけるスケール則
Scaling Laws for Autoregressive Generative Modeling
https://arxiv.org/abs/2010.14701
様々なドメインにおいて計算資源、データ量、モデルサイズのスケール則を調査した研究。調査したドメイン全てで3つの量に対するべき乗の関係が存在し、ドメインに最適なモデルサイズはドメインによらず普遍的な傾向を示した。
大規模なネットワークには冗長な構造があることを発見
DO WIDE AND DEEP NETWORKS LEARN THE SAME THINGS? UNCOVERING HOW NEURAL NETWORKREPRESENTATIONS VARY WITH WIDTH AND DEPTH
https://arxiv.org/abs/2010.15327
深いまたは幅広いネットワークは、複数の層において似た表現を学習している(block構造と呼ぶ)ことを発見。これは層表現の主成分に対応しており、ネットワーク固有の表現となっている。これらを使って精度への影響を極力抑えた枝刈りが可能である。また、幅広いモデルはシーン判別に強く、深いモデルは消費財判別に強いという傾向があった。

ハミルトニアンを簡単にすることで複雑な系の予測精度を高める
Improving the accuracy of predicting complex systems by simplifying the Hamiltonian Simplifying Hamiltonian and Lagrangian Neural Networks via Explicit Constraints
https://arxiv.org/abs/2010.13581
一般化座標を用いると制約条件が含まれる代わりにハミルトニアンが複雑になってしまうが、デカルト座標に埋め込んだ制約付きハミルトニアンを使うことで数式を単純化でき学習を容易にする。複雑な系であるN重振り子、ジャイロスコープで精度/データ効率が劇的に向上した。

---------------------------------------------------------------------
2.技術的な記事等
----------
なぜ決定木系の手法がニューラルネットワークを上回ることが多いのか?
ニューラルネットワークは確率的にモデルのフィッティングを行うが、決定木系の手法は決定論的にフィッティングを行う。画像のように0 or 1で表現できないものや、自然言語のように曖昧で例外が多いものはニューラルネットワークが強いが、多くの事象はYes/Noで処理できるため決定木系の手法が強い、と主張がなされている。
教師あり学習の観点から強化学習を見てみる
強化学習を教師あり学習の観点で解釈した記事。RLは、ポリシーとデータの両方に対する共同最適化問題と解釈でき、この教師あり学習から見た観点から見ると、多くのRLアルゴリズムは、適切なデータを見つけることと、そのデータに対して教師あり学習を行うことを交互に行うものと見なすことができる、と述べている。
ViTの解説動画
TransformerでCNN系を打ち破ったViTの解説動画。TransformerがCNNと同様に、層が深くなるにつれて局所的な特徴量から大域的なな特徴量を取得していること、TransformerはCNNやLSTMより帰納バイアスは小さいため、大規模データセットがあればCNN等を超えられること、などを説明している。
データサイエンティスト面接の120以上の想定質問とその回答
データサイエンティスト面接の120以上の想定質問とその回答。統計/機械学習の基礎知識や実務での活用を問う内容になっている。統計/機械学習の基礎が習得できているかをテストする意味でもおすすめ。
正規化層の解説
図解とともに正規化の解説・主な用途を解説した記事。BatchNorm, LayerNormはもちろんSPADEまで解説されている。
Yann LeCun先生の講義資料が公開
チューリング賞受賞者のYann LeCun先生のDeep Learning講座が無料で見れるようになった。講義資料だけでなく、Jupyter notebookによるコードも公開されている。
物体検知の推論高速化
物体検知の推論速度を9FPS→650FPSまで高速化させた記事。CPU/GPUの転送を避けること、重い計算をGPUにさせること、バッチ処理すること、半精度の使用、などが挙げられている。Nsight SystemsでCPU/GPUの使用状況がどうなっているかを逐一見ながら適応手法の根拠を示してくれるので非常に納得感がある
テストスコアより訓練スコアの方が高いのはなぜ?
Test データのスコアがtrainデータのそれより高くなった場合、その原因は何か、を議論したRedditのスレッド。適切なtrain/testの分割、kerasの仕様上trainのスコアは1epochのスコア平均であるためtest評価時のモデルとは異なること、などが挙げられている。
---------------------------------------------------------------------
3. 実社会における機械学習適用例
----------
火星クレーターを見つけるしんどい仕事は機械学習で
機械学習を用いて、火星のクレーターの発見をさせたという記事。自動化された機械学習ツールで、隕石の衝突跡を発見することができた。小さなクレーターを探す作業は、非常に大変で40分もかかることがある。そのような仕事を機械学習に任せることで、人間をより思考力を使う仕事に集中させることができる。
優秀な弁護士がAIに敗北
秘密保持契約の欠陥を見つけるタスクでトップの弁護士を上回り、通常の弁護士が92分かかる秘密保持契約の審査をAIは26秒で審査できる。弁護士からの反応は肯定的で、より複雑なプロジェクトに弁護士が集中できるなどのメリットを上げている。
建築現場の細かな進捗をAIで管理する
英国-イスラエルのスタートアップ企業であるBuildots(https://buildots.com/)は、頭に取り付けた360°カメラから約150,000個の部品がどの状態にあるのか(取付済みなど3〜4段階)を監視できる。すでに小規模な建築現場で導入されており、人間の管理者が確認作業など単調な仕事ではなく、より重要な仕事に注力できるようになると期待されてる
電池の性能をAIで予測
MITとトヨタの研究者が電池の性能を計測している。通常、電池を劣化させるまで試験するためには数年単位で充電/放電を繰り返さなければならないが、数時間分のデータを使って機械学習で予測することで、電池の性能を予測している。電気自動車には急速充電の電池が必要だが、それの選別に役立つとのこと。
AI 目視検査プラットフォーム
LandingAIが目視検査のプラットフォームLandingLensをリリース。AIの専門家ではなくても数クリックでモデルを展開できる。多くの製造業は小規模な実証プロジェクト(いわゆるPoC)の後で多くの企業が行き詰まっているため、全体的な採用は遅れているが、LandingLensは多くの目視検査プロジェクトの構築と出荷に関するノウハウと専門知識を基に開発されているため利活用を促進できるとのこと。
AIを使って情報戦を解析する
大量のニュースや発信される情報を自然言語処理で解析することで、情報戦に対応したという記事。最近のアルメニアとアゼルバイジャンの紛争の数ヶ月前から、ある一方の国を侵略者と描くような意図を持って情報が発信されていると解析するなどしている。
---------------------------------------------------------------------
4. その他話題
----------
2020年の人工知能発展のレポート
177ページにわたる大規模な報告資料。研究の動向や人材の所在、倫理への問題、軍事利用への拡大、来年の動向予測など幅広いテーマでまとめられている。研究に関しては巨大データセット/巨大モデルが精度を牽引、生物学でAIを用いた論文が増加、PytorchがTensorflowに追いつきつつある、など
GPT-3が掲示板に1週間潜伏しても誰も気づかなかった
OpenAIが開発した巨大高性能言語モデルGPT-3が掲示板Redditに1週間潜伏し、人間とやりとりしたが、誰も気づかなかった。時たまGPT-3は陰謀論を流布していたり、「運動の目的は、金を得るという目的のために人生を消費している事実を考えないようにすること」という名言(?)を残している。
画像データセットに潜む偏見を特定
画像データセットに潜む偏見を特定するツールが公開。既存の画像注釈と、オブジェクト数、オブジェクトと人の共起、画像の原産国などの測定値を使用して、測定する。人とオルガンに関しては、男性は演奏している、女性は演奏していないけど同じ空間にいる、などの違いがあった。
---------------------------------------------------------
TwitterでMLの論文や記事の紹介しております。
https://twitter.com/AkiraTOSEI
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。調査や論文読みには労力がかかっていますので、この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
過去の記事
Week 41の記事, Week 42の記事, Week 43の記事, Week 44の記事
2020年9月のまとめ
ここから先は

Akira's ML news & 論文解説
※有料設定してますが投げ銭用です。無料で全て読めます。 機械学習系の情報を週刊で投稿するAkira's ML newsの他に、その中で特に…
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。