宝くじ仮説のwinning Ticket使わずに疎な高精度ネットワークを高速学習するRigging the Lottery

この記事について
この記事では、『一部の素晴らしい初期値をもつ部分(winning ticket)がネットワークを支配している』という宝くじ仮説(Lottery Ticket Hypothesis)[1]を軽く説明したあと、初期値ガチャで”winning ticket”を引かなくても全ての初期値を”winning ticket”に以上にすることができるRigging the Lottery[3] を説明します。
※ 有料設定していますが、投げ銭用の設定なので、無料で全て見えるようになっています。
宝くじ仮説(Lottery Ticket Hypothesis)とは
ニューラルネットは多くのパラメータを持ちますが、実際に精度に効いているのはごく一部のパラメータであり、ニューラルネットは”疎”であることが近年の研究でわかってきています。その効いている一部のパラメータのみを残して、残りのパラメータを排除することで精度を保ったままネットワークを高速化する枝刈(Pruning)という手法があります。
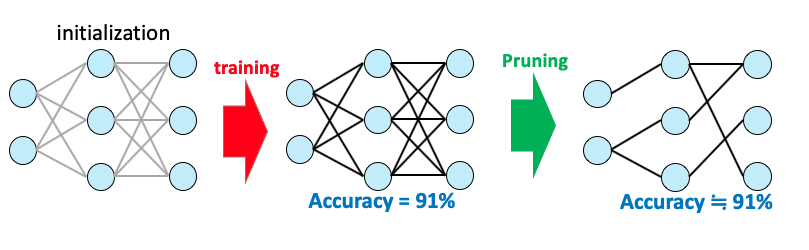
このとき、枝刈されたあとのネットワーク構造とパラメーターどちらが精度に効いているのでしょうか。その疑問に対して、「枝刈後の構造ではなく枝刈後のパラメータの初期値が重要。初期化の時に良い初期値(Winning ticket)があり、それをガチャで引けると精度がいい。それだけで学習しても良い結果が得られる。」と提唱しているのが宝くじ仮説[1]です。
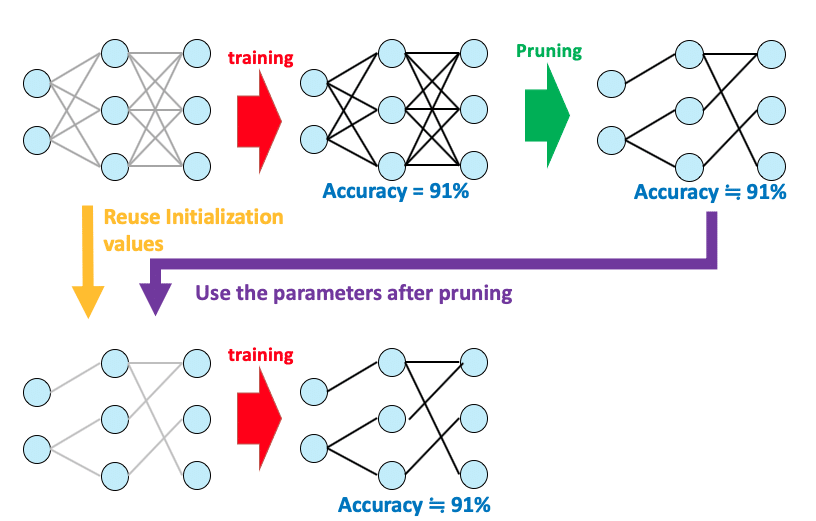
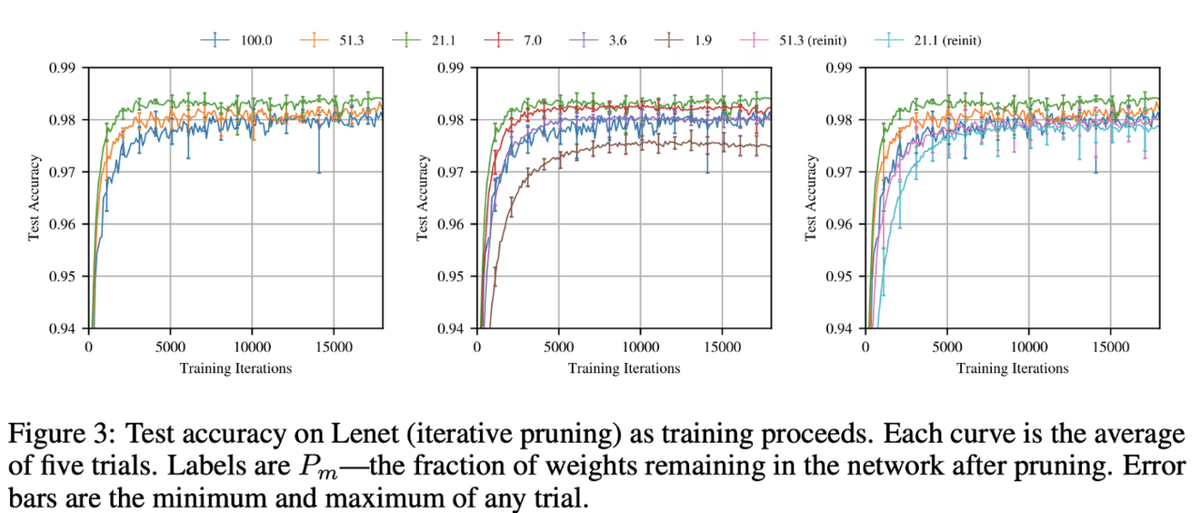
下図が宝くじ仮説をMNISTで検証した実験です。数字は残しているパラメータ(重み)の割合で、学習が終わった後に枝刈して、再度同じ初期値を配置して再学習させた時の結果です。良い初期値のみで、元々の密なネットワーク(100.0)と同等の精度が出ており、条件によっては精度が向上さえしていることがわかります。しかし、同じ初期値を使わずに再度初期化すると精度が下がっています(reinit)。つまり枝刈後の構造ではなくその初期値が精度に寄与していることがわかります。
そして、その初期値(Winning ticket)は汎用的に使えることがわかっています[2]。下の図はいろいろなタスクで得たWinning ticketでCIFAR10を学習させたものです。どのタスクで得たWinning ticketでも、ランダムに再初期化した水準よりも良く、それなりに良い働きをしていることがわかります。
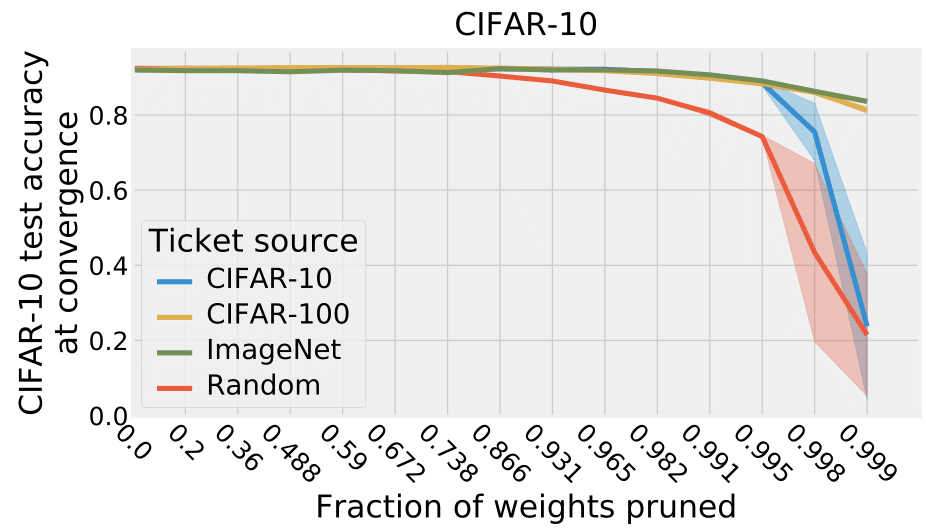
上記の設定で色々なタスクで得たWinning ticketを様々なタスクで使ってみた結果が下の図です。Winning ticketを得たタスクは違っても、様々なタスクで有効であることがわかります。ImageNetのような大きなデータセットで学習させたwinning ticketが高性能そうです。
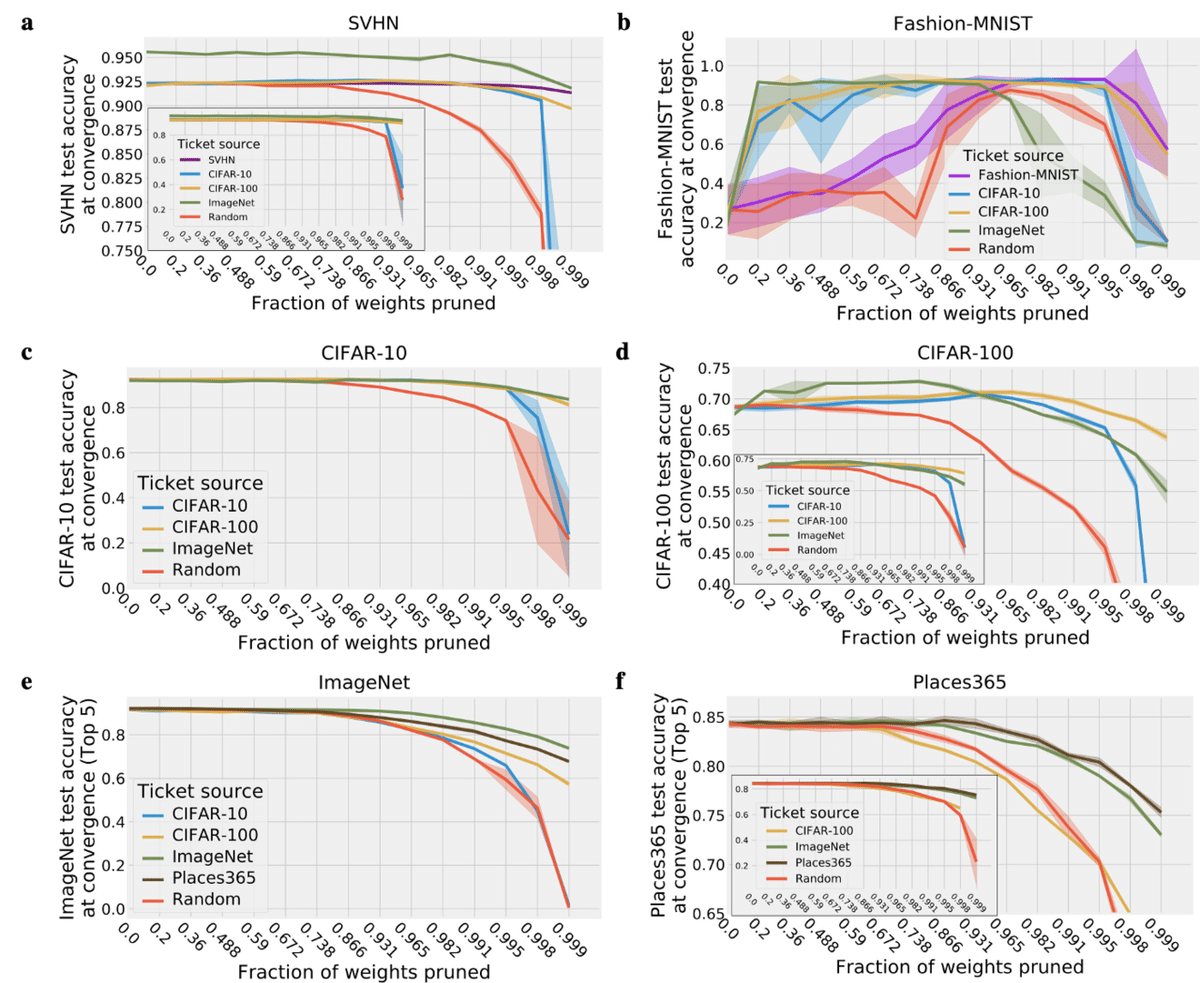
最適化手法にも依存せず、Optimizerを変えても依然有効です。

Rigging Lottery
良い初期値だけを使った疎なネットワークを使えば学習も推論も高速です。しかし、良い初期値を見つけるためには、まず密なネットワークを学習させて、良い初期値を見つけるために枝刈をしないといけません。GoogleとDeepMindの研究チームが最初から疎なネットワークを使って、”winning ticket”を使ったときと同等以上の精度を出す手法を発表しました。上述の宝くじ仮説を念頭いおいて、この手法を”RigL (Rigging Lottery : イカサマ宝くじ)と名付けています。
RigLでは、以下の手順で学習をします。以下でそれぞれ詳細を解説します。
1. 疎なネットワークを作成
2.パラメータの絶対値が小さい順に結合を消す
3.新たな結合を創出
4. (2と3を繰り返す)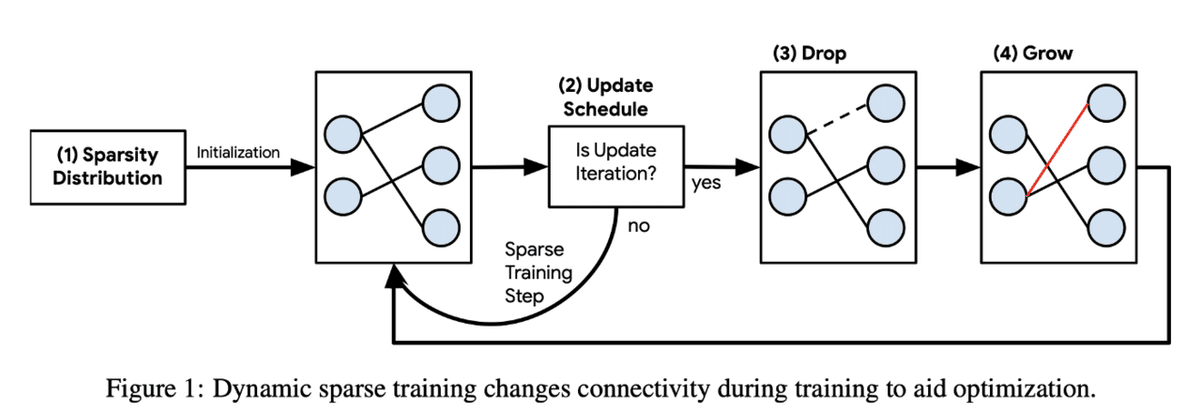
1.疎なネットワーク作成
論文では3つの疎なネットワーク初期化手法を提案しています。一様分布、Erdos-Renyi、Erdos-Renyi-Kernel (ERK) の3つです。後者2つの定義式は下図の通りです。Erdos-Renyiはパラメータが多い層ほど疎にする初期化となっており、ERKはそれをCNNのカーネルのパラメータにも拡張した形になっています。後述しますが、ERKが一番よかったようです。

2.パラメータの絶対値が小さい順に結合を消す
通常の枝刈のように、パラメータが小さい順にK個だけ結合を削除します。TopK(v, k)はベクトルvのtop-k要素を抽出する関数です。削除する数はアニーリングのように学習が進むにつれて徐々に減らしていっています。

3.新たな結合の創出
使ってない結合のうち、Gradientが大きいものを結合します。結合していないので、それぞれパラメータ0の結合を割り当てることで勾配を計算可能にします。パラメータが0なので目的関数の値に影響は全く与えませんが(Forwardの再計算が不要)、値はゼロでも結合しているので勾配を計算することが可能になります。これを全ての非結合部分で計算し、勾配が大きい、つまり精度に貢献する部分を結合させます。
![]()
Results
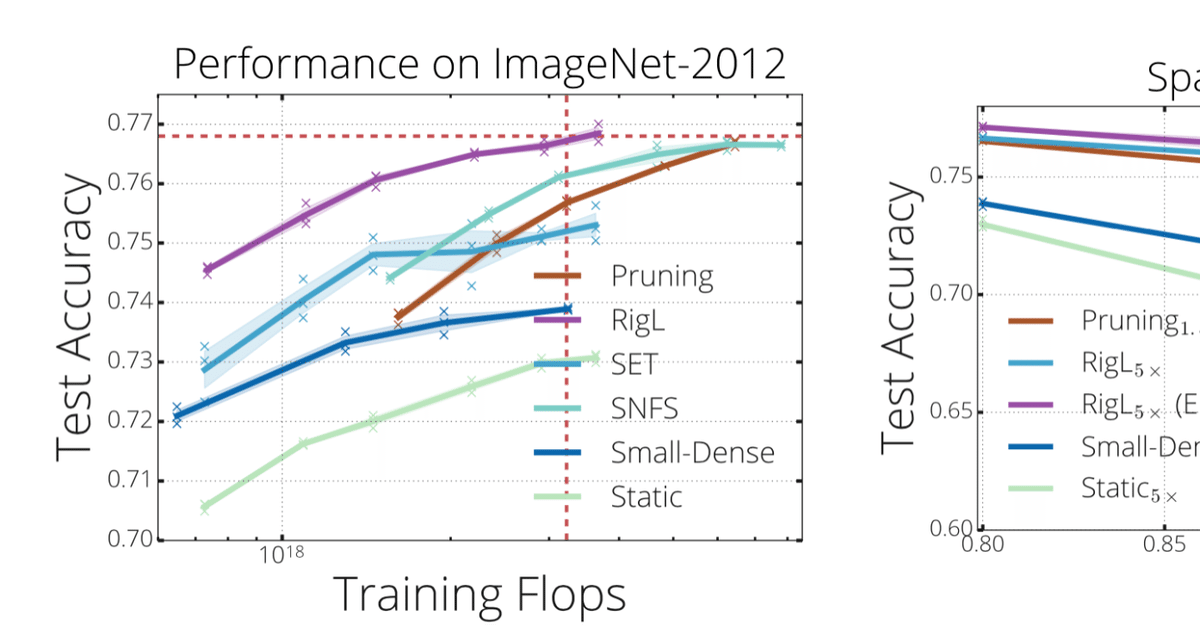
RigLの結果を見てみましょう。まずは他の手法との比較です。下図の左を見ると通常の(Denseな)ResNet50の学習と同じ学習コストで、同等の精度に到達できていることがわかります。下図の右では、それよりもさらに学習を進めて検証した結果で、下添え字のx5は左図の5倍のepoch数分だけ学習させたことを示しています。既存手法より良さそうです。
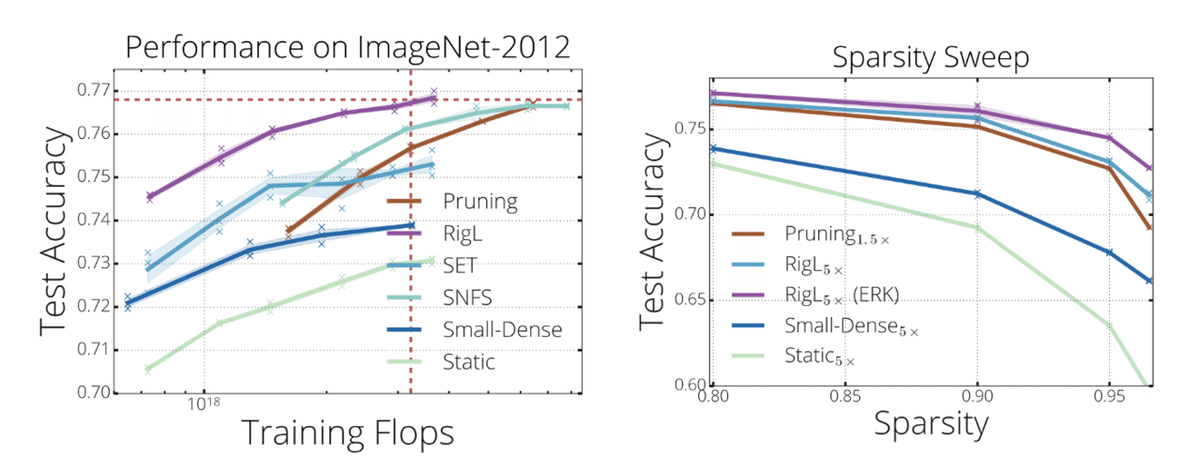
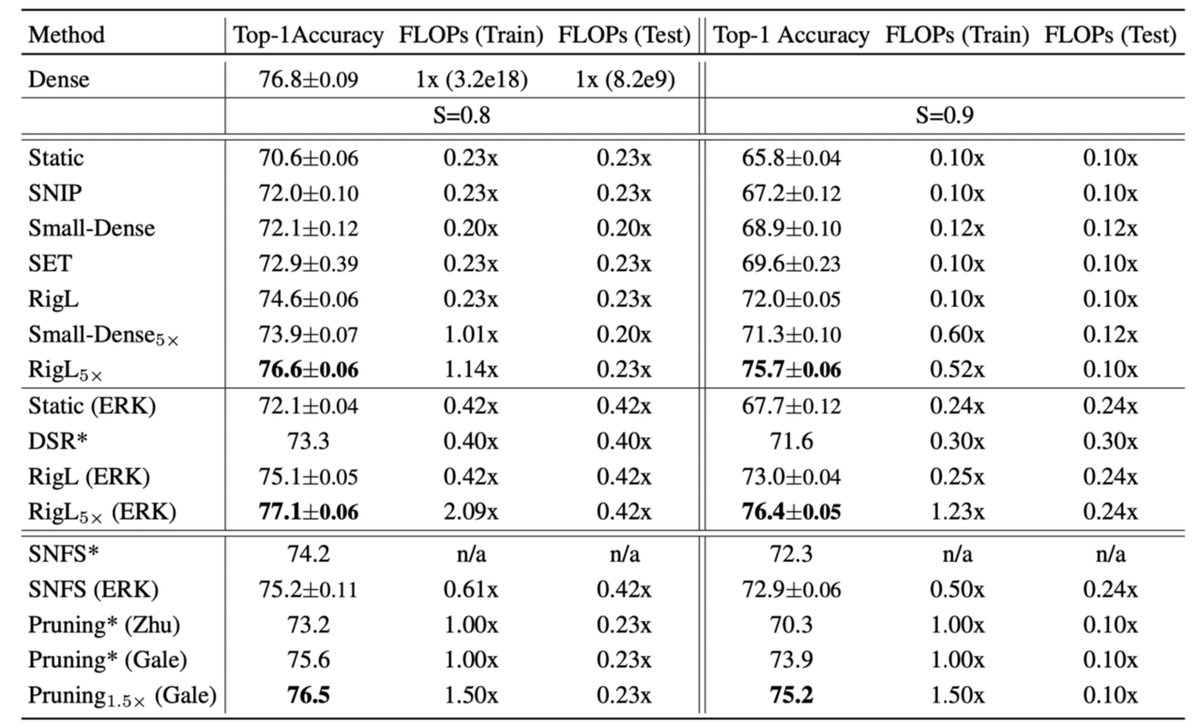
次はもう少し網羅的に比較したのものをみてみます。下の表はCIFAR10をResNetで学習させるタスクで関連手法と比較した結果です。Sはスパース率(パラメータの非使用率、通常のDenseなネットワークだと0)です。S=0.9において、通常(Dense)のResNetより23%多い学習コストで、DenseなResNetとほぼ同等の精度かつ推論速度は4倍高速なネットワークが学習できるのは素晴らしいの一言です。
ResNetの層別のスパース率は下の図の通りです。図中のres2a_branch2b等は、ResNet原論文のResNet50における「Conv2_x(a)の1番目(a)のResidual Bottleneck Block[Conv1x1→Conv3x3→Conv1x1]の2番目(b)のConvolution操作(kernel size 3x3 のConv)」を示しています。


まず、最初の数blockは、Bottleneck部分のConv3x3を除いてスパース性が低い、つまり大半のパラメータは使われていますが、一方で最後の部分はスパース性が高くなっています。論文中で特に言及はありませんでしたが、『抽象化度が低い特徴量を抽出をするネットワークの上部は様々な特徴を抽出するために多くのパラメータを使うが、それらを組み合わせた抽象化された特徴は数としては少ないので必要なパラメータ数は少なくてよい』ということを示していると私は考えています。もしそれが正しいのだとすると、最初の数ブロックのカーネル数を増やすと精度改善に繋がるのかもしれません。
また、Bottleneck Block[Conv1x1→Conv3x3→Conv1x1]の中央のConv3x3のスパース性が一貫して高いのはなかなか興味深い結果です。これも論文中で特に言及はありませんでしたが、『最初のConv1x1で局所的な特徴を数多く取ってくるが、それらを空間的に組み合わせた高次特徴の中で有用なものは一握りである』ということを示しているのかもしれません。
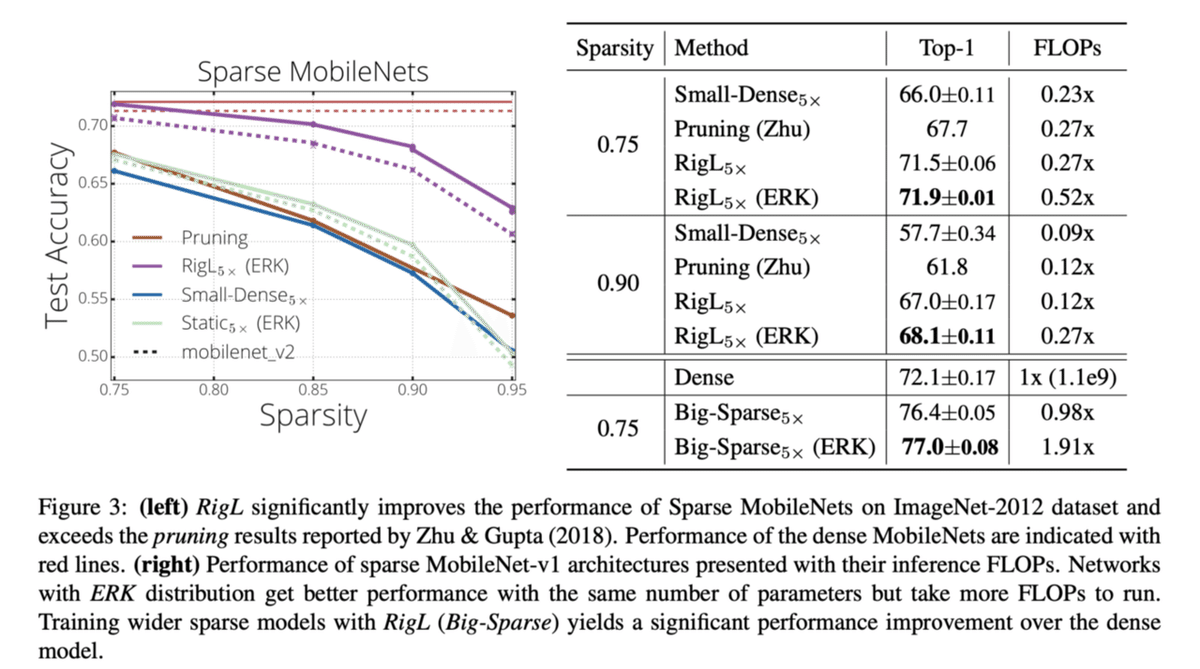
もちろんResNetだけでなくてMobileNetでも適用可能です。Big-Sparseという水準は通常のMobileNetよりチャネル数を増やしたネットワークです。
初期化の比較とネットワークの更新方法の検証です。初期化はCNNのチャネル数だけでなくカーネルのパラメータ数も考慮した初期化であるERKが一番よかったようです。

最後にWinning Ticketを使った時の比較です。それを使わなくても動的に良い学習結合を学ぶRigLは良い成果を出していることがわかります。

まとめ
この手法は、既存のネットワークを高速化するだけではありません。この手法を使えば、計算コストが膨大にいかかる巨大モデルを学習することができるかもしれません。
膨大なパラメーター数をもつ巨大モデルが正義というのが最近の風潮ですが、個人所有のGPUではそのようなモデル学習させることが困難です。0.9のように高いスパース率であっても密な結合をもつ大きいモデルと近しい精度が出ているので、スパース性を0.9等に設定することで学習コストも大幅にダウンしながら、巨大かつ高精度なモデルを学習することができる可能性があると著者たちは述べています。
Reference
1.Jonathan Frankle, Michael Carbing. mixup:The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks, ICLR2019
2. Ari S. Morcos, Haonan Yu, Michela Paganini, Yuandong Tian. One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers. NeurIPS2019
3. Utku Evci, Erich Elsen, Pablo Castro, Trevor Gale. Rigging the Lottery: Making All Tickets Winners. ICML2020
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。調査や論文読みには労力がかかっていますので、この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
ここから先は
¥ 200
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。