
Akira's ML news #January, 2021

2021年1月に発表された論文/記事のうち、私が特に面白いと思ったものをまとめています。
今月の注目記事/論文
- 1つのGPUで130億パラメータの学習をする
- 知識蒸留とアンサンブルの関係性をニューロンが取得する「視点」から解釈する
- 重要な部分はノイズに敏感に反応することを利用した可視化
- OpenAIによるText-to-imageの大幅な改善
- token毎に層の切替をすることで、高速に大規模モデルを学習する
- 自然言語と画像を合わせて学習することでゼロショット推論を可能する
---------------------------------------------------------------------
1.論文
----------
自然言語と画像を合わせて学習することでゼロショット推論を可能する
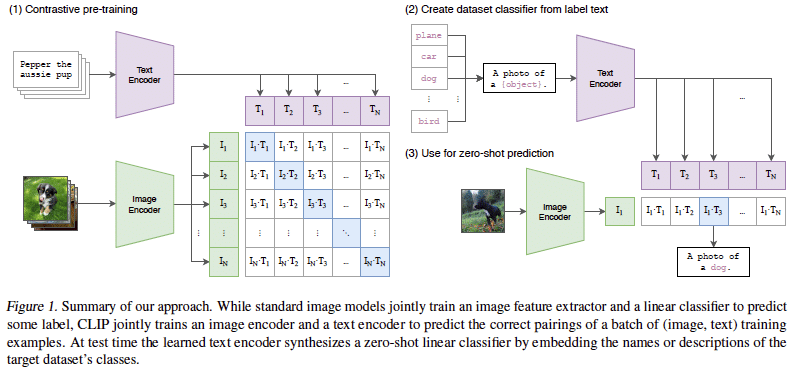
Learning Transferable Visual Models From Natural Language Supervision
https://cdn.openai.com/papers/Learning_Transferable_Visual_Models_From_Natural_Language_Supervision.pdf
画像とテキストそれぞれを符号化するネットワークを使い、画像分類などのタスクをGPT-3のようなzero-shotでこなすCLIPを提案。画像側はViT、テキスト側はTransformerを用いて、画像とテキストペアを正しく当てる事前学習を400万の画像とテキストのペアデータセットを使って学習する。CLIPは自然言語を用いているため、ImageNet等で事前学習したモデルより様々なタスクより柔軟に対応可能でき、例えばイラストでカテゴリを当てられる。画像分類のほかに、行動検知、OCR, オブジェクト詳細分類などもタスクもこなせる。しかし、物体を数えたり、距離を表現するなどのタスクは苦手としている(GPT-3でもチーズが溶けるなど物理的関係が理解できないという同様の問題があった)
Softmaxを使ったプーリングで情報を柔軟に圧縮する
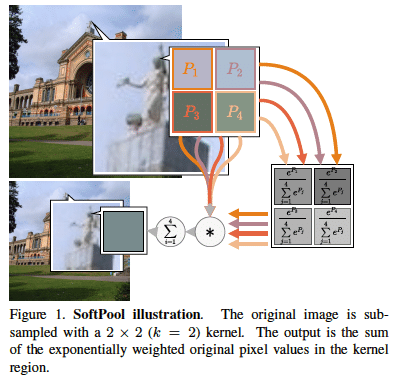
Refining activation downsampling with SoftPool
https://arxiv.org/abs/2101.00440
領域内でsoftmax関数でPoolingを行うSoftPoolを提案。既存手法と比較して多くの情報を残しながら特徴量マップを圧縮できる。画像分類と行動検知で精度向上を確認。
重要な部分はノイズに敏感に反応することを利用した可視化

U-NOISE: LEARNABLE NOISE MASKS FOR INTERPRETABLE IMAGE SEGMENTATION
https://arxiv.org/abs/2101.05791
意味的領域分割における学習済みモデルの解釈性を向上させる研究。ノイズを載せると重要な箇所はノイズの大きさに敏感に反応する(予測が変化する)はずだという考えから、学習済みモデルと画像からノイズの載せ方を学習する小さなモデルを学習することで、その学習済みモデルが敏感に反応する箇所を探し、それを重要な箇所だと認識する。
1クラス分類のサーベイ

One-Class Classification: A Survey
https://arxiv.org/abs/2101.03064
異常検知などで使われる画像系タスクの1クラス分類に関するサーベイ。わりとGANベースのアルゴリズムが多く紹介されている。また、使用されるアルゴリズムだけでなく、異常検知のデータセットや評価指標に関しても言及している。
BatchNormの挙動をまねることでBatchnormを除いたネットワークを学習する
CHARACTERIZING SIGNAL PROPAGATION TO CLOSE THE PERFORMANCE GAP IN UNNORMALIZED RESNETS
https://arxiv.org/abs/2101.08692
BatchNormを含んだResNetの特徴量マップの挙動を解析し、BatchNorm無しでもその挙動を再現できるような係数をかけることによって正規化層なしでも深いネットワークで学習できるNF(Normalization Free)-ResNetを提案。不安定な部分があるのでCutMix等と併用が必要だが、AutoAugmentを使ったEfficientNet程度の性能が出せる。
1つのGPUで130億パラメータの学習をする

ZeRO-Offload: Democratizing Billion-Scale Model Training
https://arxiv.org/abs/2101.06840
1つのGPUで最大130億パラメータの学習が可能なZeRO-Offloadを提案。順方向と逆方向の計算とパラメータはGPUで維持しつつオプティマイザーの計算をCPUに任せる。高速に処理が可能、かつ、複数GPUにも拡張可能。さらにDeepSpeedライブラリを使って簡単に使える。
OpenAIによるText-to-imageの大幅な改善

DALL·E: Creating Images from Text
https://openai.com/blog/dall-e/#fn1
OpenAIが開発したTransformerベースのtext-to-image(文書から画像を生成)モデル。論文は未発表だが120億のパラメータ(GPT-3の1/10程度)をもつ。単一の物体だけでなく複数の物体も描写可能で、存在しない概念(アボカド椅子)も上手く描写できる。画像を途中から生成させることでIQテストっぽいのも解ける。
token毎に層の切替をすることで、高速に大規模モデルを学習する

SWITCH TRANSFORMERS: SCALING TO TRILLION PARAMETER MODELS WITH SIMPLE AND EFFICIENTSPARSITY
https://arxiv.org/abs/2101.03961
Self-Attention後にtoken毎の処理を最適な専門層に切り替えて(swtich)行う、大規模なパラメータを使いながら効率的に学習できるSwicth-Transformerを提案。T5と比較するとと65倍のパラメータ数を使いながらも7倍の速さで同じ精度に到達できる。最大モデルのパラメータ数は1.5兆。
実質的に疎なモデルになっている。それぞれのtoken毎に最適なものを選んでいるので大規模モデル大パラメータの利点を活かしつつも、切替により実質的に1token毎に使っているパラメータ数は少ない。デバイス毎にパラメータを展開するなど考えることはまだ多そうだが、モデル大規模化と合わせて1つの潮流になるかもしれない
仮想的な試着をStyleGAN2で行う

VOGUE: Try-On by StyleGAN Interpolation Optimization
https://arxiv.org/abs/2101.02285
仮想的な試着を行う研究。まずをStyleGAN2をkey point 条件付きで事前学習した後、衣類と体の画像がミックスされるように衣類参照画像と人画像の2つの混合率のようなものを各層で調整させる後学習を行う。
数学的に等価な変換でSelf-Attentionの計算量を削減

Efficient Attention: Attention with Linear Complexities
https://openaccess.thecvf.com/content/WACV2021/papers/Shen_Efficient_Attention_Attention_With_Linear_Complexities_WACV_2021_paper.pdf
Self-Attentionの計算を(QK)VではなくQ(KV)に変更することで、数学的な等価な計算で計算量をn^2→d_k*d_vに削減することが可能。大きな解像度で大幅に計算量が削減できる。物体検知において、non-localの代替として入れることで精度向上を確認した。
画像と文書から時間的な関係を自己教師で学ぶ
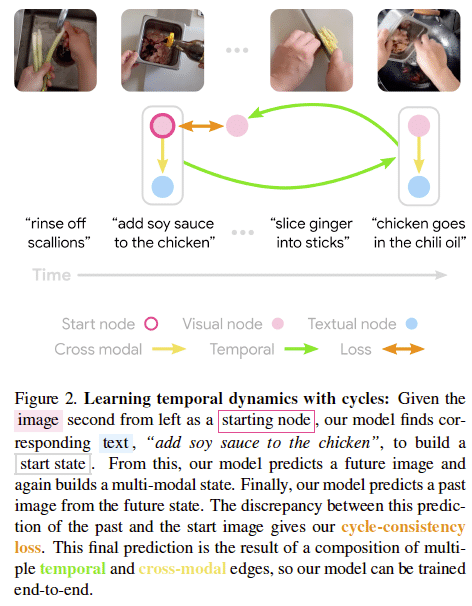
Learning Temporal Dynamics from Cycles in Narrated Video
https://arxiv.org/abs/2101.02337
画像と文書を組みわせて時間的な関係を自己教師あり学習する手法を提案。画像から対応する文書を見つけた上で、将来の情報を予測させ、そこから過去を予測するcycle consistencyで学習させる。大規模な画像データセットから時間的構造や事例の要約を発見するためにも利用できる可能性がある。
徐々にMixupの割合を減らすことで性能向上

Mixup Without Hesitation
https://arxiv.org/abs/2101.04342
Mixupで得られる表現は強化学習でいう探索/利用トレードオフの”探索”に相当と考え、学習の後半は「利用」に注力する(つまりMixupをあまりしない)アルゴリズムMiup Without Hestation(mWh)を提案。学習を3ステージに分割し、徐々にMixupの回数を減らしていく。混合比率αの選択に対して頑健になる。
物体検知モデルを文書で慎重に学習させることで良い画像/言語表現を得る

VinVL: Making Visual Representations Matter in Vision-Language Models
https://arxiv.org/abs/2101.00529
Vision-Language(VL)では事前学習した物体検知モデルの表現を扱うが、それらはあまり注目されていなかった。VinVLでは4つのデータセットで慎重に物体検知モデルが良い画像/言語表現を持つように学習す戦略をとる。学習した物体検知モデルは意味的領域をほぼ検知できるモデルになっており、それを使ったVLモデルは7つのタスクで最高精度を更新した。
---------------------------------------------------------------------
2.技術的な記事
----------
知識蒸留とアンサンブルの関係性をニューロンが取得する「視点」から解釈する
Kaggle等でよく使われるアンサンブルはモデルの分散を小さくするから性能が良くなると考えられてきたが、各ニューロンが取得する「視点」がより多くなるので性能が向上するのではないかと提唱。この観点で考えると知識蒸留は、「視点」情報を移行する枠組みと解釈でき、自己蒸留は知識蒸留による暗黙的なアンサンブルであるとしている。
機械学習の監視
ソフトウェアを使ったサービスでは監視が必要なように、機械学習を使ったサービスでも監視が必要。この記事では、機械学習を使ったサービスでは何を監視するか(モデルが古くなってないかを監視するため精度を見る等)、ケーススタディや監視ツールの紹介を解説している。
BERTを使ったトピックモデル
BERTを使ったトピックモデルとその使い方の解説。Github上にモデルが公開させれており、可視化もできる。
医療x機械学習の問題点
医療x機械学習の問題点を指摘した記事。医療x機械学習がメディアを騒がしているが、機械学習はデータに依存しており、医療データは簡単に欠落したり偏ったり、理解不足からデータが不適切に収集されている場合もある。さらにアルゴリズムの実装ミスにより、援助が滞ったケースも紹介している
機械学習のライフサイクル
「データ収集→モデル開発→評価」という本番環境におけるモデル開発のライフサイクルを解説した記事。データのアノテーションをする際の注意事項や方針をキチンときめておかないとモデルの精度が上がらないこと、予測がうまくいってないサンプルを見ることで更なる精度向上が期待できること、などが述べられている。
---------------------------------------------------------------------
3.実社会における機械学習適用例
----------
ニュースから中立的な要約を生成する
テレビニュースや新聞はそれぞれの団体の政治的偏見を含んでおり、同じ事例であっても異なる書き方をされている。このプロジェクトでは、同じ事例を扱った2つの記事から類似する文を見つけ、それらで共通して述べられている出来事のみを要約することで政治的に中立的なニュース文を生成する取り組みをしている。まだ発展途上のようだが、githubレポジトリも公開されている。
鉛中毒にAIで対抗する
ミシガン州フリント市では老朽化する水道管による鉛中毒が発生していたが、機械学習を使い、高リスクのエリアを特定するモデルを作る取り組みとそれに伴う裁判の経緯が述べられた記事。住民から情報を取得しないといけないため、情報を収集する期間(この場合は政府機関)とアルゴリズムへの信頼が不可欠であると語っている。
火星のクレーターを機械学習で探す
火星研究において、新しいクレーターの特性を調査することで古いクレーターの年齢を推定することができる。NASAでは深層学習を使って火星のクレーターを探す取り組みを行なっており、45分かかっていた作業が5分に短縮することができた。
商用の顔認証システムからプライバシーを守る

LOWKEY: LEVERAGING ADVERSARIAL ATTACKS TO PROTECT SOCIAL MEDIA USERS FROM FACIALRECOGNITION
https://arxiv.org/abs/2101.07922
商用の顔認証システムで正確な照合を困難にするツールLOWKEYをリリース。写真をアップロードすると敵対的ノイズを乗せた画像を送ってくれる。AWSとAzureの顔認証システムで効果を確認。
---------------------------------------------------------------------
4.その他話題
----------
arxivで論文解説のリンクをみる
Arxiv上で論文のサイトにそれらを説明するビデオに飛べるリンクが貼り付けられるgoogle chromeの拡張機能が登場。1分くらいでインストールできて便利
GPT-3レベルのモデルを無料公開する取り組み
高性能言語モデルであるGPT-3はマイクロソフトが独占契約を結んでいるため自由に使うことができない。 EleutherAI.というグループが主導で、無料で使えるGPT-3相当のモデルGPT-neoの開発を進めているとのこと
トップ会議至上主義が招いた悪習
具体的な大学名は挙げられていないが、トップ会議に通して高給な職を得るために不正な研究が蔓延っているという告発。既存のものを組み合わせただけの名ばかりの研究を実施し、論文の体裁を整えることに大きく時間を費やしている研究(?)がトップ会議の、しかもオーラルに通っていると述べている。具体的な実験はあまりせずにいるため、コードの公開もしていない(もちろん匿名掲示板なので真実とは限らない)
JupyterLab 3.0がリリース
JupyterLab 3.0がリリースされた。ビジュアルデバッカー、中国語等の複数言語への対応、インターフェースのシンプル化などが目玉のようだ。
注目のAIスタートアップ
Crunchbase(民間企業および公開企業に関するビジネス情報を検索するためのプラットフォーム)による注目のAIスタートアップの動向と注目の25社の紹介。2020年は資金調達の中央値は440万ドルで、AIスタートアップ全体だと276億ドルの資金提供をうけたとのこと。アメリカの企業も多いが、イスラエルも多い。
---------------------------------------------------------------------
過去の記事
2021 Week3, 2021 Week4, 2021 Week 5
2020年10月のまとめ
2020年11月のまとめ
2020年12月のまとめ
2020年の総まとめ
---------------------------------------------------------------------
TwitterでMLの論文や記事の紹介しております。
https://t.co/yYMYJdGY9E
— akira (@AkiraTOSEI) January 27, 2021
アンサンブルはモデルの分散を小さくするので性能向上すると考えられてきたが各ニューロンが取得する「視点」がより多くなるので性能が向上すると提唱。この観点で考えると知識蒸留は「視点」情報を移行する枠組みと解釈でき自己蒸留は蒸留による暗黙的なアンサンブルとなる
記事は以上です。ここから下は有料設定になっていますが、特に何もありません。この記事が気に入って投げ銭しても良いという方がいましたら、投げ銭をして頂けると嬉しいです。
ここから先は

Akira's ML news & 論文解説
※有料設定してますが投げ銭用です。無料で全て読めます。 機械学習系の情報を週刊で投稿するAkira's ML newsの他に、その中で特に…
記事を書くために、多くの調査や論文の読み込みを行っております。情報発信を継続していくためにも、サポートをいただけると非常に嬉しいです。