
Pythonで機械学習『家の販売価格予測』002/100

初心者向けのチュートリアルを一通りやったので、今回は、チュートリアルなしでどこまで行けるかを試す。これで次の学習ステップがもう少しはっきりするといいな。(note記事も丁寧に書いてみる。今まで適当すぎたし)
テーマは、House Prices - Advanced Regression Techniques。回帰分析を使って米国Iowa州の住宅価格を予測するものにした。脱初心者のためのテーマらしいので、利用してみる。
まずは、データをチェックした。

train.csvは、1460行で81列で、test.csvは1459行で80列。
予測したいのはSalePriceであり、予測値の対数と観測された販売価格の対数の間のRMSE(Root-Mean-Squared-Error)で評価される。
RMSEとはなんぞや。
数値予測のモデルの良さを測る指標の一つ。低ければ低いほどよい。最良の場合は 0 。今現在、Kaggleリーダーボードでは、1位2位が0.0。3位が0.00044。予測モデルが安定して小さい誤差で予測をしているかを表す指標。大きいエラーを許容できない場面で使われる。誤差がどれだけあるかを比率ではなく幅で着目しているので、小さなレンジでの誤差に着目したい場合には適していない。(→この場合は、RMSLEを使う)
つまり、目的変数が、True or Falseでなく数値である場面で、派手に予測が間違っている時に戒めてくれる指標なのですね。
下記参考にさせていただきました。
次に、データ説明を確認。

初っ端から意味が理解できないけど、今回は一個づつクリアにしていく!
column01
MSSubClass : 住居のタイプ
データはintで20とか75とかで区切られている。数字の大小に意味がないので、カテゴリ変数ですね。
欠損値はなし。
比率はこんなで、上位4位はこちら。

20 1946年以降の1階建て すべてのスタイル
60 1946年以降の2階建て
50 1-1/2階建て完成品 すべての年齢層
120 1階建てPUD(計画的ユニット開発) - 1946年以降
翻訳は全部DeepL。でも、どれがいいのか悪いのかは感覚的にはまったくわかりません。SalePriceで比較してみます。
60・70・75の二階建て物件は少し価格高めですね。

相関見てみます。
※著者注 ↑これ間違いその1。後で気づきます。
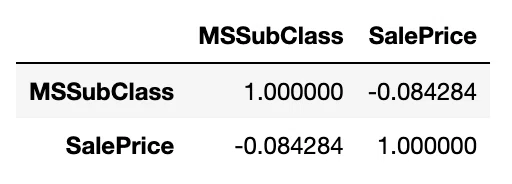
全体としては相関はないですね。築年数で区切ったらあるのだろうか。1946年以上で見てみた。

若干上がったけど、相関があるとは言えなさそうですね。
ところで、カテゴリ変数に相関って使えるんだっけ?
と思って調べてみたら、使えませんでした。そりゃそうか。間違いその1。カテゴリ変数と量的変数の相関を調べるときは「相関比」を使うのだそう。さらに相関比の場合、データが正規分していないといけない。
まずはSalePriceが正規分布かどうか調べる。

正規分布ではなさそうですね。
正規分布かどうかの検定手法があったので一応試してみます。
シャピロ・ウィルク検定。こういう人名ついた専門用語、もう慣れましたよ。もう怖くない怖くない。
※著者注 ↑これ間違いその2。後で気づきます。
コードは少なかった。
from scipy import stats
stats.shapiro(train_df['SalePrice'])結果は、ShapiroResult(statistic=0.869671642780304, pvalue=3.206247534576162e-33) p値が0.05より小さい。あれ、正規分布とみなしてよいのかな。(ウィルクさんは省略されてしまったようですね。)
と思ったら、検定の解釈が間違っていました。このSalePriceの元である「母集団」が正規分布しているかどうかの検定でした orz
なるほど、間違えた。間違いその2。
じゃあやっぱり正規分布していないなら、なに分布かというとポアソン分布というそうです。ポアソンってフランス語で「魚」ですね〜。
正規分布していないときに量的xカテゴリ変数の相関を調べるときは順位相関比というものを使うみたい。ピアソンの積率相関係数とスピアマンの順位相関係数の関係のように、相関比の量的変数部分を順序尺度の変数にしたものが順位相関比、なんだって。
もうぜんぜんよくわかんない。
でも、こんなときに使える作戦をじつは昨日本で読みました。対数変換です。やってみます。コードはめっちゃ簡単。
np.log(train_df['SalePrice'])ヒストグラムは、正規分布っぽい。

count 1460.000000
mean 12.024051
std 0.399452
min 10.460242
25% 11.775097
50% 12.001505
75% 12.273731
max 13.534473
平均値と中央値がほぼ一致してます!
調べている過程で、ポワソン分布は対数変換より平方根変換のほうがいい場合もあるという論文を見つけた。ということでやってみる。
x=√xで変換して、ヒストグラムはこんな感じ。

あれ?左右対称ではない。
count 1460.000000
mean 416.617225
std 85.769006
min 186.815417
25% 360.520452
50% 403.732585
75% 462.601340
max 868.907360
うーん、√xではなく、√x+1/2でやる方法もあるらしいんだけど、理解が進まず断念。ちなみにデータ変換には他にもロジット変換、Box-Cox変換、などがあるみたい。
気を取り直して、対数変換したSalePriceと住宅タイプ(MSSubClass)の相関比をみる。
相関比はこちらが大変参考になりました。
x = np.log(train_df['SalePrice'])
y = train_df['MSSubClass']
xy = pd.concat([x,y],axis=1)¥
var = ((x-x.mean())**2).sum()
inter = sum(((xy.loc[xy['MSSubClass'] == i,['SalePrice']]-(xy.loc[xy['MSSubClass'] == i,['SalePrice']]).mean())**2).sum()
for i in np.unique(xy['MSSubClass']))
0.669ということで、
「住宅タイプと住宅価格はそこそこ強い相関がある」ということがわかりました。なるほど。
※著者注 ↑あれ、1−0.669なので、0.33が正解なのか??わからん、出直します。
MSSubClassはこんなとこで、次に行こうと思います。めっちゃ時間かかってるけど、理解は進んでいると思う。
column02
MSZoning :ゾーニング
これは理解しやすいですね。ほとんどRL(Residential Low Density)で、つまり住宅単位の密度が低いってことですね。アメリカの地方都市っぽい。
RL 1151
RM 218
FV 65
RH 16
C (all) 10
SalePriceとの関係は、

密度があがると価格がさがるのはなんとなくわかる。けど、C・RHは10件程度しかないからな。FVは、引退した人向けの地域らしい。
モデリングするとき、CとかRHは別モデルで予測したほうがいいのだろうか?重み付けができる方法とかあるのかな??
ちょっと密度高くなるRM。RMはwikiによると1870〜1940に多く建てられたものだそう。調べてみよう。

1920年代初めが確かに多いけど、他年代でも多いときあるね。
欠損値もないですね。
今日はここまで、次回は続きをします。
この記事が気に入ったらサポートをしてみませんか?