
Pythonで機械学習『Iowa 家の販売価格予測 その4 KFold』002/100

前回Iowaの家価格の予測をKaggleに初投稿した。
今回はKFoldやってみる。
公式はこちら。
引数は、3つ。
n_splitsは、フォールド数と言われるもので、デフォルトは5。
1/5を検証用とし、残りを学習用とする。それを5回繰り返す(全データが検証用に使われる)。
2以上の整数を指定する。
あとはshuffleとrandom_state。シャッフルしない場合はrandom_stateも指定する必要なし。
from sklearn.model_selection import KFold
kf = KFold(n_splits=4)↑みたいに書く。ここまでは簡単。次からがちょっとややこしい。
まずモデル・検証結果・予測値を格納するための箱を用意する。うーふ。
models = []
rmses = []
oof = np.zeros(len(train_X)lgbのパラメータを指定したら、次は一気に書く(for文)
for train_index,valid_index in kf.split(train_df):
train_x = train_X.iloc[train_index]
valid_x = train_X.iloc[valid_index]
train_y = train_Y.iloc[train_index]
valid_y = train_Y.iloc[valid_index]lgb_train = lgb.Dataset(train_x,train_y)
lgb_eval = lgb.Dataset(valid_x,valid_y,reference = lgb_train)
model_lgb = lgb.train(lgb_params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=1000,
early_stopping_rounds=10,
verbose_eval=10)
pred_y = model_lgb.predict(valid_x,num_iteration=model_lgb.best_iteration)
rmse = np.sqrt(mean_squared_error(np.log(valid_y),np.log(pred_y)))
print(rmse)
models.append(model_lgb)
rmses.append(rmse)
oof[valid_index] = pred_ykf.splitで取ったindexで、学習データを分割し、モデルを作って予測、それを繰り返すって感じ。なるほどー。慣れるまではややこしく感じるんだろうな。
rmseの結果はこちら。

平均は、
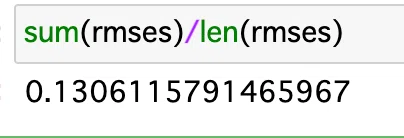
なので、前回のtrain_test_split(1.265〜〜〜)より落ちちゃった。
fold数を5にしてやってみると、

さらに下がった。
一度、Kaggleに投稿してみる。
5フォールド分作ったモデルで、予測し、その平均を取る。
preds = []
for model in models:
pred = model.predict(test_Y)
preds.append(pred)
preds_array = np.array(preds)
preds_mean = np.mean(preds_array,axis=0)kaggleに投稿した結果は、、、

0.13822から0.13256へ、スコアを伸ばした。順位は1610位に上昇。
学習1回するだけより、5回学習してその平均を取った方が予測の誤差が少ない、というのは納得感のある結果です。よかった。
でも検証のときのrmseは下がったのに、テストデータへの予測精度は上がったのはなぜだ?
クロスバリデーションをすると、フォールドの平均RMSEは、全体でやる時よりも低くなるのだ、とはどこかで読んだ。そういうものなのか。
次回はついにチューニング。やるぞー。
この記事が気に入ったらサポートをしてみませんか?