
Pythonで機械学習「文字列の処理」

文字列の処理、TPSのMAYで必要だったんだけど、他のことにやってて結局やらずじまい。。。なので、今やる。
こちらを参考に。
まずは、文字数の確認。
column.str.len().min ()
column.str.len().max()
で、全て十文字であることを確認。
次は、個数確認。

118万1880種ある。一番多くて15個。なるほど。
次は、難しそう。
位置と文字による確率
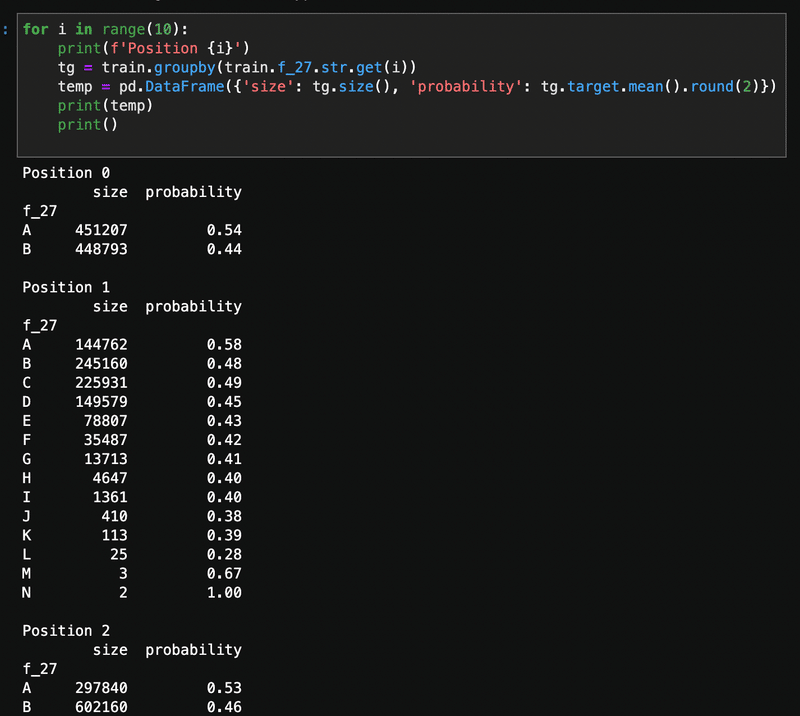
最初の文は、
Position 0〜9
を表示させている。
for文でiをprintしたいからf文字列にしてるのかな。
print(f'Position {i}')
覚えておこう。
3行めは、train.f_27.str.get(i)
で一文字づつ取り出し、
その文字でグループにしている。
.sizeで要素数を取り出している。(.shapeの行x列的な。要素数。)
targetの平均を取ることで、1である確率を出している。
.round(2)で小数点以下2桁以下は四捨五入。
すげーなー、Position1がNなら100%1ですってことね。なるほど。

次は、十文字の中に何種の文字があるか、またその場合の1である確率は何か。出たよ、lambda。
lambdaは
lambda x: x+5
みたいに書く。
左側が引数、右側が関数処理内容。
この場合、xに5が入れば、返り値は10。
add = lambda x : x + 5
add(5)
10
今回の内容で見てみると、まず、
set()で、重複をなくしている。そしてlenで個数を数えている。
.applyで、f_27に適用する。
すげー。
ここではユニーク数が多ければ多いほど、ってか7種以上であれば1である可能性が高いことがわかる。逆に3以下であれば0である可能性が高い。
次はいよいよ特徴量を作る。
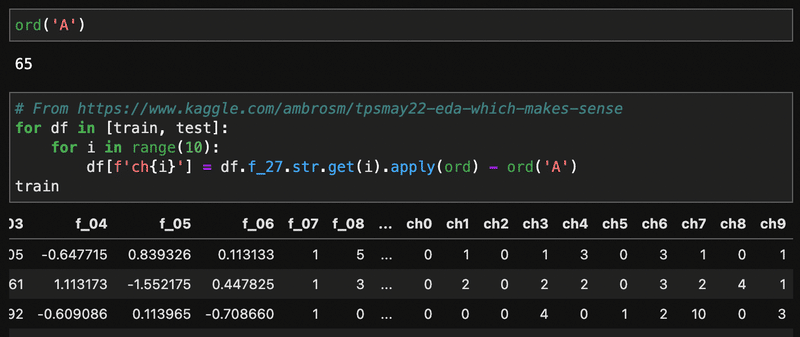
ord関数は初めて見たけど、アルファベットとか文字の番号(決まっているらしい、Unicordポイントというみたい)が取得できる。Aは65。なので、Aを引くことで、Aは0、Bは1、Cは2、に変換できる、なるほどなー。
おしゃれなlabelEncodingって感じですね。
いやー、お見事でした。
新しい関数をいくつか覚えたぞ。
8つ出てきた。
f文字列
.get()
.size()
.round()
.apply
lambda x : x
.set()
.ord()
この記事が気に入ったらサポートをしてみませんか?