bookfanをクローラー | bookfanから書籍の画像をスクレイピング

bookfanとは?
イーブックイニシアティブジャパンの本・CD・DVD・Blu-ray、及び電子書籍を取り扱うハイブリッド書店です。 オンライン書店「シスコストア」としてサービスを開始し、「boox store」への名称変更を経て、2015年12月にハイブリッド書店「BOOKFAN by ebookjapan」として名称変更しました。 BOOKFANまたはbooxの店名でYahoo!ショッピング、LOHACO、楽天市場、ポンパレモール、Wowma!などのオンラインモールに出店して紙書籍通販を行っています。過去に旧ブークスはパピレスと連携し電子書籍を販売していました。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすく人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
抽出されたデータは下記のようにご覧ください

1.タスクを新規作成する
(1)URLをコピーする
検索条件を入力して、その検索結果ページのURLをコピーしてください。今回はビッグデータに関する書籍の情報を例として、スクレイピング方法を紹介します。

(2)タスクを新規作成する
ソフトウェアのホムページ画面に新規作成できます。
新しいタスクを作成しますか、タスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
URLを正しく入力する方法


2.タスクを構成する
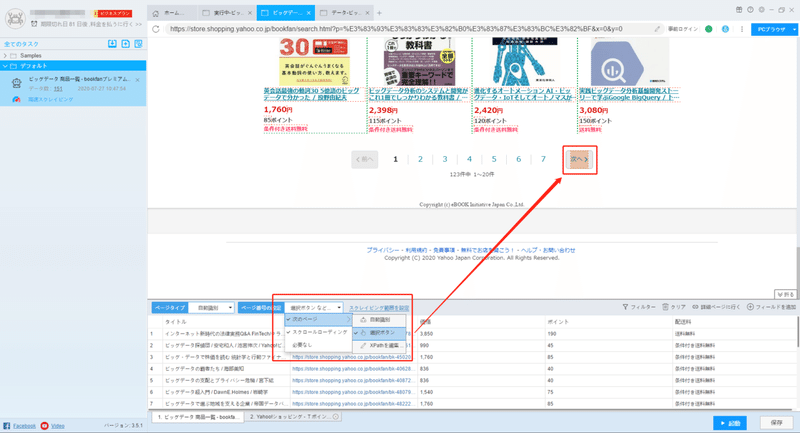
(1)ページボタン
ScrapeStormは自動的にページボタンを識別できます。今回は「スクロールローディング」を認識しますが、手動で「次へ」ボタンを選択してください。ページボタンの設定詳細は下記のチュートリアルをご参照ください。
ページ分けの設定
(2)詳細ページに行く
詳細ページに商品情報、配送情報があります。より多くの情報を取得するために、詳細ページに行く機能を利用してください。

(3)事前操作
書籍の画像を抽出するには右上の緑色ボタンをクリックして、事前操作機能を利用してください。「大きな画像を見る」をクリックして、操作ヒントに「要素をクリック」を選んでください。ソフトウェアは自動的にコンポーネントを生成します。

(4)フィールドの追加と編集
フィールドの追加には、「フィールドを追加」ボタンをクリックして、画面に抽出する要素を選択、データが自動的に抽出されます。今回は画像を選んでください。また、必要に応じてフィールド名の変更、削除、結合などの編集もできます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法

3.タスクの設定と起動
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、画像のダウンロード、スピードブーストを設定できます。今回は画像のダウンロードをチェックしてください。
スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法

(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする

(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。ライトプラン以上のユーザーは、WordPressに直接投稿することもできます。
抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法
