
ISBN番号によって旭屋書店から書籍の情報をスクレイピングする

旭屋書店とは?
株式会社旭屋書店は、 大阪府大阪市北区に本社を置く日本の書店。「旭屋書店」の名称で、近畿地方を中心に日本国内13店舗、香港に1店舗を展開する。みどり会の会員企業です。専門書や希少本、雑誌、文具まで、業界トップグループとしての72周年を迎えました。旭屋書店は、これからもお客様の声を一番に、身近な書店として発展し続けます。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすく人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
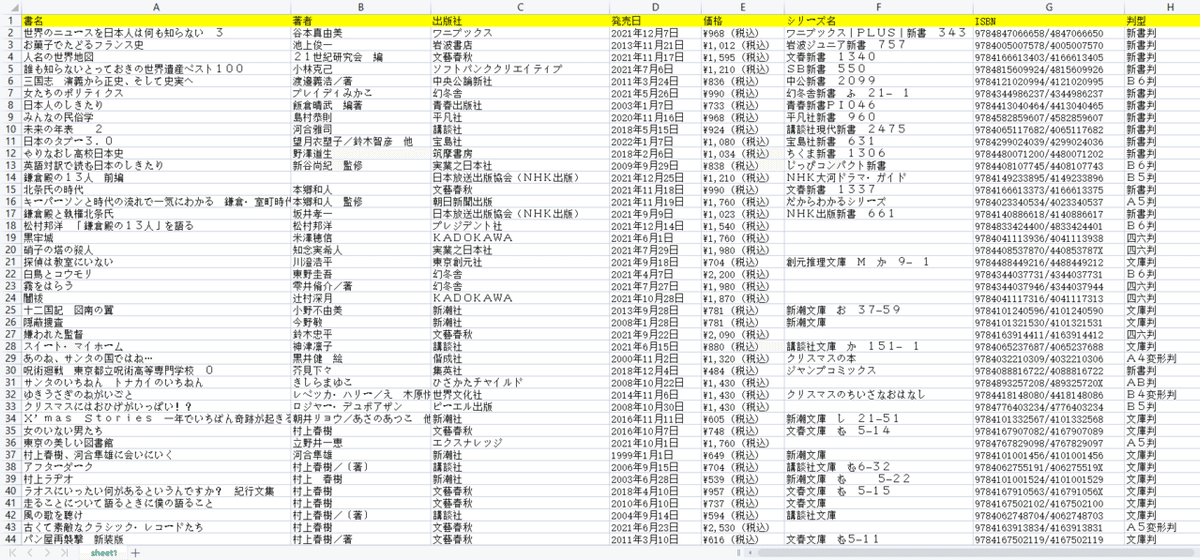
抽出されたデータは下記のようにご覧ください。
1.タスクを新規作成する
今回はURLジェネレーター機能を利用して、ISBN番号によって店舗の情報をスクレイピングします。
(1)URLをコピーする
まず、検索結果ページのURLの主幹をコピーしてください。

(2)パラメータを追加する
URLジェネレータでURLを入力して、パラメーターを追加画面に「ファイルから読み込む」を選んで、ISBNを入力します。生成したURLはプレビュー画面でチェックしてください。
URLジェネレータの使い方

2.タスクを構成する
(1)ページタイプとページボタン
今回は直接詳細ページのURLを生成しますから、ページタイプを「単一ページ」に設定してください。ページボタンは一応「詳細ページ」に設定しても大丈夫です。
ページタイプの設定方法

(2)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法

3.タスクの設定と起動
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。サーバーに負荷しないように、遅延時間を設定してください。5秒以上を推薦します。スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法

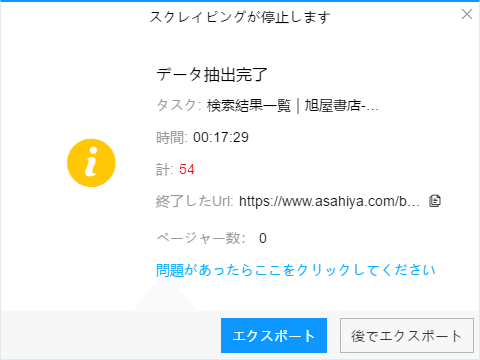
(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。ライトプラン以上のユーザーは、WordPressに直接投稿することもできます。
抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法

注意:法律違反しないために、抽出されたデータを悪用禁止です!
この記事が気に入ったらサポートをしてみませんか?