
エンタープライズ情報システムの障害 傾向と対策に関する研究 はじめに - 研究の背景

1.はじめに
1-1. 本研究の問題意識
情報システムのシステム障害については一般に、予防措置の構築と迅速な対処指針の確立という2つのアプローチが必要とされている。これらは通常、過去の障害事例や先行検証(ベータ試験・事前試験)にて得られた情報を基に検討をする。
過去事例の数量的分析から知見を導いた先達の文献を見ると例えば、坂東・向殿(2001)は予期せぬ負荷に対する信頼性対策、意図的な脅威への対策、各種ミスへの対策が必要だと述べていた。これは非常にハイレベルな考察である。従って現場のシステム管理者が具体的な対象を絞り込んでアクションに結び付けることが極めて困難である。
他のシステム障害に関連する先行研究では、対象が絞り込まれアクションが具体的になっている文献を見つけることができる。しかしこれらは、対象を取り上げた理由や主張が個人の考えに基づいている。そのため取り上げた障害事例の発生頻度やその重要度・影響度といった情報がなく、情報自体の重要度や信頼度を測定することが困難だった。
システム管理の現場が必要としているのは、客観的かつ信頼ができ、効果が見込めかつアクションを起こせる情報である。ITIL(IT Infrastructure Library: 項2-1-1-2にて詳細を後述)がデファクトスタンダードになった理由は、これらを満たしているからだ。これまでのシステム障害に関する数量的分析を伴う先行研究がシステム管理の現場からの期待に応えられていない点について筆者は課題を見出した。
筆者は先達の研究者が入手できなかった、システム障害のフィールドデータを入手し、先行研究に倣って研究を進めるることにより、現場の期待に応えていきたい。
1-2.本研究の目的
本研究の最終的な目的は、緊急対応が必要とされる情報システムにおけるシステム障害の現状について明らかにし、その対策を提示することにある。
本論文での目的は、大きく分けて2つある。1つ目は、論文参照者が類似した分析の仕組みを構築できるよう、分析を実行するまでの過程を明らかにすることである。2つ目は、取得したデータの分析を行い、新たな知見を提示することである。
そしてこれらの目的へ到達することにより、システム障害の量的分析の研究リファレンスとなり、業界や社会に貢献することをその後の目標としたい。
2. 研究の背景
2-1. 先行研究レビュー
先行研究をレビューする目的は、同じ研究が既に実践されていないことを確認することに加え、既に存在する知見を効果的に引用し、研究が過去の知見に基づいて行われていることを示すことである。
また、自らの研究対象よりも幅広い範囲で先行研究をレビューすることにより、自らの研究を幅広い研究の中で位置づけることができる。そして自らの研究に関連する隣接分野の知見を得ることで、例えば技術的には実現できても現実としては実現できないような研究結果にならないよう意識をすることができる。
以上のことから、先行研究をレビューする目的およびレビューの観点を次の通り定めた。
先行研究レビューの目的
1. 先行研究との研究内容の重複を避ける
2. 有用な知見をベースに論理を積み重ねる
先行研究レビューの観点
1.研究課題
2.その解消方法
3.課題解消後の新たな課題
2-1-1. 先行研究の探索およびレビュー
先行研究の探索にはいくつかの方法が存在する。書誌情報あるいは抄録(アブストラクト)、全文を対象としたコンピュータによるキーワード検索が最も効率的に先行研究を見つけ出すことができる。このことから、国立情報学研究所が提供する論文検索システムCiNiiを利用し、情報システムの障害に関連した論文誌および一般雑誌の文献を探すことにした。
検索を実施する際には、次に掲げるキーワードを用いた。尚、キーワードの選定については、「システム障害」および「情報システム+障害」を中心的なキーワードとし、それに付随するキーワードを追加している。
・システム障害
・ITIL
・ISO 20000
・情報システム+信頼性
・情報システム+ディペンダビリティ
・ヒューマンエラー
・情報システム+障害
これらのキーワードをCiNii検索した結果、2013年10月1日時点で計3,367件の検索結果が得られた。タイトルや抄録を吟味し、明らかに情報システムに関連しないと思われる文献および重複した文献を除去したところ、最終的に278件の文献を抽出することができた。
文献のレビュー後、それらの分類を行った。大きな分類として自らの研究に大きく関連する「障害の分析」と「それ以外」に分けた。障害の分析についても、データを分析し知見を出す「分析評価」とデータ自体の分析を行う手法等について述べた「分析技法」に分類した。
また、「障害分析」以外については、まずは障害がユーザーへ影響を与えるとされるフェーズとして運用・保守フェーズとそれ以外のフェーズに分けた。
運用・保守フェーズについては、八木隆他(2004)がITILでの管理対象ポイントとして区分けした、技術・プロセス・人という3つのポイントでの分類が考えられる。これらに加え、論点がそれら3つのポイントを複合的に有する個別の事例を別の分類として付け加えた。
その他のフェーズとなる、システム立案、計画、設計、製造等については、システム安定性や継続運用度、正確性を論点とした「信頼性」、そして「その他」に分類した。
分類した結果、各分類は次のような文献数となった。
表2-1-1. 文献レビュー
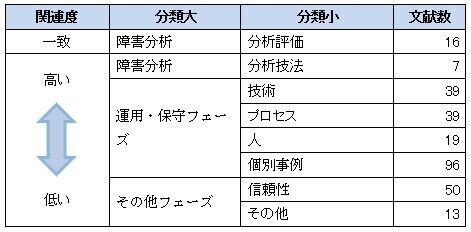
ここでいう関連度とは、筆者が研究で実践しようとするインシデントの数量分析という研究から見たときの関連性の度合いを指している。運用・保守フェーズで発生する問い合わせや事象そのものをインシデントと呼ぶことから、運用・保守フェーズとは関連があるが、「その他のフェーズ」となるシステム立案、計画、設計、製造とは関連度が低い。
関連度が低いということから「その他のフェーズ」についてはここでは取り上げない。また個別事例については、筆者が行おうとする「分析評価」が多くの事例を対象に研究を進めることから、研究の主旨が異なるため、代表的な事例を示すにとどめる。
運用・保守フェーズの分類は技術・プロセス・人・個別事例とした。技術・プロセス・人の3要素については、ITILでは管理対象として区分けしている。それらについてレビューした結果は次の通りである。
2-1-1-1. 保守フェーズ–技術
技術の観点では、その技術が何のために活かされているのかという観点で分類を行った。分類とは次のような分類となり障害が発生する前の障害検知、障害発生時に障害を回避するための耐障害性および迅速に障害解決を行う障害回復、障害発生後に重要となる原因究明の3つのフェーズでの分類も行うことができた。
表2-1-1-1. 技術での文献分類
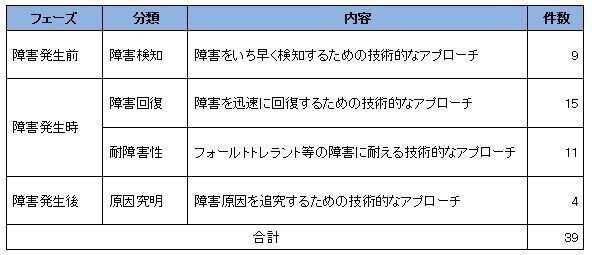
ここで対象となった39件の文献については、半数以上が2000年以前の研究成果だった。チェックポイントやフォールトトレラントなど2000年以前に研究されている従来の技術が現在もよく利用されているということが分かった。
特徴的なこととしては、原因究明に分類した研究は、パソコンが一般化し、コンピュータサーバーシステムのダウンサイジングが加速化しだした1995年あるいは1996年頃まで行われ、その後同類の研究が見当たらないことが挙げられる。
ダウンサイジング以前、特にメインフレームについては、障害の原因究明が業務として必須であり、この業務の負担を軽減するという観点で研究がおこなわれていることからも研究の流れが時代に沿ったものであることが伺える。
ダウンサイジングが進んでからは、原因究明よりもむしろ耐障害性確保や迅速な障害回復といったことが研究の主軸になった。時代背景として、PCサーバーの価格が下落したこと、ネットワーク装置も含め多重化や冗長化が容易になったこと、そして様々な技術を活用してシステムを構築するオープン化という考えが浸透してきたことが後押ししている。
ここでは、フェーズの観点から分類を行った。ここでいうフェーズとはシステム障害の発生を起点としたその前後を含めた3つの状態を意味する。それと同時にフェーズの中に分類を設け、障害検知、障害回復、耐障害性及び原因究明という内容で分けた。
障害発生前
障害発生前を対象とした内容として障害検知がある。これは障害を早く検知するための研究である。なぜこの研究が行われていたかいうと、予め障害の兆候を察知することができれば、問題の発生を回避できる可能性が高いからである。これに加え、将来的に技術化に結び付く、モデルの構築についてもここに含めている。
安井・尾崎(1989)は、ハードウェアを対象に、その一時障害の積み重ねが固定障害へ繋がることを防ぐため、1回の点検で一時障害の発見確率を最大化する点検方策に関する研究を行った。障害を発見するために秒単位で監視すれば一時障害の発見は十分できるが、秒単位で監視するのは現実的に不可能である。このことから、監視単位時間を広げつつ一時障害の発見確率を上げることで効率性を高めたことに貢献性を見出すことができる。
鈴木・安東他(1990)は、ソフトウェアのメモリ開放忘れを防ぐことが固定障害へ繋がるという経験から、これを防ぐためメモリガベージの検出に関する研究を行った。ガベージコレクションというオペレーティング・システムやソフトウェアの実行環境が持つ、自動的にメモリ解放する機能と関連している。ここでは、ガベージコレクションをだけを信頼するのではなく、メモリ開放忘れを自ら防いていくことを主眼に研究がおこなわれていた。
細川・斉藤(1994)は、システム障害をシステム管理者へより早く通知することにより、システム障害の影響範囲を極小化するため、電子メールを用いた管理システムの開発に関する研究を行った。様々な通知手段のうち、電子メールを用いることによる優位性を分析から導き、システム開発を行っていた。
2000年以降になるとシステム障害はあってはならないものから起こる可能性があるものという見方に変わっている。熊谷(2002)は、システムやネットワークの障害は避けられないものとし、その予兆を事前に検知し障害時に短時間で復旧する方法を発表した。御木と冨澤(2005)は、「人が何かをしでかす」という前提に立ち、ネットワーク上で人為ミスを検知するためのシステムを開発した。また障害が起こるという前提に立った加藤と本多(2009)は、情報システムではデータを保全することが最も重要と考え、バックアップとリストアに加え、ハートビートや負荷の監視を提唱した。
近年では、吉野・廣田他(2009)が、Webシステムを対象に一部のプロセス障害がシステムダウンの予兆になるとしてシステムダウンの予兆検知の仕組みを発表、和泉・土肥他(2010)は分散プロセスのデッドロック検出をスケジューリングの実行に合わせたモデル化を行い、新たな分散実行環境の管理を提唱した。
これら全体を通して見えるのは、時代が変わるごとに検知のターゲットが変わっていくことである。2001年から大流行したコンピュータウィルスのCode RedやNimdaは生き残りがネットワーク内にいれば、対策されていないPCが感染するため、2005年くらいまでは様々な会社のネットワークで生存していた。そして2004年にSasserウィルスが大流行したという歴史から、御木と冨澤がウィルスの持ち込みを人為ミスとみなしていた。また、現在のようにシステムがフォールトトレラントを標準で実装する時代になれば、注目する検知の対象はノードが移動する起点となるイベントをいち早くキャッチするところとなり、吉野・廣田他らや和泉・土肥他らの研究がこれをカバーしている。
障害発生時
次に障害発生時の研究を見ていく。ここでの研究は主に、障害回復と耐障害性の2つに分類することができる。障害回復では迅速に障害から通常の状態へ回復するための方法等を研究している。そして耐障害性では障害が発生してもその影響範囲を限定的にさせること方法等について研究をしている。発生した障害から迅速に復旧させることはあらゆるシステム管理者に課された障害発生時の責任の1つである。また発生してしまった障害については耐障害性を有することで、障害が発生していない状態と同様の状態を保持できる。障害は実際に発生しても、業務への影響を最小限にできることから、ユーザー側の視点で見れば障害発生予防と捉えることができ、これもシステム管理者が準備をするという点で責任の1つとされている。
障害回復の観点では、久保・堀越(1982)はメインフレームのシステムサービス停止を回避するために、システムレベルの回復技法を研究し、複数の回復方法について説明を行った。相沢・宮内他(1994))は分散システムを活用することで障害回復をはかる方法について研究を行い、システムの開発を行った。土肥・尾崎他(1995, 1996, 1999)は、チェックポイントについて、システム障害とその復旧の間における期待損費用、期待リカバリー費用から新たなモデルを示した。
これに類似する研究として井川・横田(2000)は、分散型データベースを利用するワークフローについて、データ保持やキャンセル時のトランザクションの除去、システム障害発生時のトランザクション親子関係を含む再構築についてモデルを提案した。これはWebアプリケーションが2フェーズコミットを行うようになったことから生じた研究であろうと考えられる。
西村(2003)、田端(2003)、日経コンピュータ(2004)、日経Systems(2007)では、具体的な障害回復について実例を取り上げて対処方法等を説明していた。
またこれらと同時期に、Candea, Brown他(2005)および尾崎・日高他(2007)は回復手法として、リカバリーコンピューティングの技法を研究して、提案を行っていた。
障害回復を対象にした研究について総合的に見ると、1990年代中盤から2000年にかけてはチェックポイントやトランザクションといったデータベースで利用される技術が対象になっていることが分かる。2000年以降は詳細な技術から具体的なオペレーションへの展開がなされ、同時にリカバリーコンピューティングについても研究が進められていた。
耐障害性の観点では、フォールトトレラントの観点での研究がほとんどを占めている。
益田・多田(1994)は、データを保持するコンピュータがダウンした際のデータ利用不可の状態を避けるため、ネットワークで接続されたコンピュータ間で冗長性を確保するシステムを開発した。齋藤・曽我他(1994)は、複数プロセスの協調処理を支援しフォールトトレラント性を高めるHillary(プロセスの信頼性を実行時に向上させるためのツール)のデザインについて研究を行った。
石田・香川(1995)は、Unix向けに高可用性サーバーの開発を行い、ホットスタンバイシステムの構築についてまとめた。内田・佐藤他(1996)は、オフコンに自動障害回復アーキテクチャを実装する開発を行った。
菊池・松岡他(1997)は、ディレクトリサービスの耐障害性を高めるアーキテクチャを開発し発表、杉野・横田(1998)は、冗長化による性能低下について着目し、複数のモデルを用いて耐故障並列ソフトウェアについて解析を行った。
2000年以降はこれまでの文献とは若干異なり、実務的な内容が含まれてくる。日経コミュニケーション(2001)による多重化による耐障害の紹介や日経Internet(2003)による耐障害性の高いWebサイト作りの記事などがあげられる。
近年では、佐藤・小西他(2009)が耐障害性の高いファイルシステムとしてログ構造化ファイルシステムを設計し発表、杉木・奥畑他(2012)は障害検知での考えとなる1つの障害が全体への波及の引き金という考えから大きく転換し、全体の処理の継続を優先し,一部の障害を見逃すことでシステム全体の可用性の向上を目指した。
耐障害性についてまとめると、2000年くらいまではフォールトトレラント技術に関する研究が主体となっていた。2000年以降については、具体的な例を含む構築方法の紹介がなされるようになった。また最新の研究では、1ラックに大量にサーバー機材を保持するブレードサーバーシステムの考えに対応し、ラック内の1サーバー上で発生した障害を切り離すことで全体のシステムに影響を与えないようにする技法が研究されるようになっていた。
障害発生後
障害発生後の研究としては、原因究明が挙げられる。原因究明という活動では、原因を究明するための資料となるログファイルやトレース等が適切に確保できなければ原因究明を行うことが難しい。そのため、どうすればそれら情報を適切に確保できるのかという観点を主体として研究がおこなわれている。
加藤・林田(1994)は原因究明の際、トレースデータの解析が莫大で時間がかかり、迅速に対処が行えないという点を解消するために、新たな解析方式の提案を行った。
織田・北村他(1996)と渡部・松本他(1996)は共にNTTソフトウェアあるいはNTT情報システム本部に所属。いずれもハード障害の事前兆候の把握・管理により、障害発生前に部品交換を行う予防交換やオーバーホールの適切な実施を目指す研究を行い、有用な分析が行えるようになった。
原因究明の研究が下火になったのは、メインフレームからオープンシステムへの転換があったことが大きな要因である。メインフレームは無停止を原則としているため、障害発生時には原因究明を行い、障害原因を除去する。メインフレームは開発期間が長く、費用が莫大にかかる。それに比べオープンシステムはシステムの統制はとれていないものの安価でシステム開発期間がメインフレームの数分の1程度であるため、ダウンサイジングという形でオープンシステムへの転換が進んだ。また2007年問題にあるようメインフレーム技術者が大量に引退する中、メインフレーム回帰という発想はもはやIT業界にはない。このことから、システム障害の原因究明の研究はIT業界の時流・要請から外れている。
2-1-1-2. 運用・保守フェーズ–プロセス
プロセスの観点では、管理という点で分類を行った。それに所属しない内容については、システム管理ベストプラクティスとしてまとめた。
ここから先は
¥ 1,000
サポートをお願いします。サポートを活用して新境地や新たな役に立つ知識を皆様に提供させて頂きます!