Pythonを使ってイベントの来場者数をシュミレーションしよう!

1.前置
統計学を学んだ方なら「区間推定」や「仮説検定」について学んだことはあるのではないでしょうか。
そして、その中でポアソン分布や二項分布についても見てきたと思います。
今回の話では、実際のビジネスケースにおいて、一体どのような確率分布が従うのか、そしてどのようにビジネスに落とし込むのかを説明していきたいと考えてます。
2.ビジネスケース具体例
ex)ある駅前で一週間限定の野外イベントを開催することにした。
一年前に別の駅で同様のイベントを開催しており、その際には平均10000人、標準偏差100人が訪れていました。
同様のイベントは、今回開催する場所と人口がさほど変わらず、とても対照的です。
では、今回の累計来場者数の目標は10万人だったとする。
一週間以内に到達させることは可能なのだろうか。
今回はこのような例題を作成してみました。それでは考えていきましょう。
3.事象の整理
まず整理をしていきましょう
標本の平均=期待値E(X) → 10000
標本分散 =分 散V(X) → 10000
標準偏差 =標準偏差 → 100
標準偏差の2乗は分散になりますよね。
今回の確率変数(X)は、一日の来場者数です。


次に、これに従う確率分布は何かを考えます。
一見、標本平均、標本分散が出てきているので、標準正規分布を思い出してしまいそうですね。
ですが、今回には大きな罠があります。
それは期待値と分散が同じ値ということです。
何か思い出しは方はいらっしゃるでしょうか。
そう、ポアソン分布なのです
今回のシュミレーションはポアソン分布を使っていきます。
4.統計的シュミレーション
#必要なモジュールをインポート
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as snsnp.random.poisson()とは
ポアソン分布に従ってとりえる確率変数になります。
lamとは、ポアソン分布のパラメーターになります
平均来場者数が今回は10000人なので10000としていますが、別のシュミレーションで平均が100人であればパラメーターは100になります。sizeは取ってくる値の数になります。
今回のイベントの開催は一週間ですが、
念のため二週間分のデータを取ってくることにします。
あ
#10日分の来場者数を出力してみる。
n_visitor_each = np.random.poisson(lam=10000 , size=14)
n_visitor_each#出力結果
array([10018, 9930, 10048, 9874, 9991, 10092, 10033, 10011, 9956,
9883, 10102, 10086, 9976, 9931])私たちが知りたいのは累計の来場者数です。そのため累計値をとりたいので、np.comsum関数を使っていきます。
n_visitor_each = n_visitor_each.cumsum()
n_visitor_each
#出力結果
array([ 10018, 19948, 29996, 39870, 49861, 59953, 69986, 79997,
89953, 99836, 109938, 120024, 130000, 139931])値を見てみると、11個目に10万を超えていることが分かりますね。
これをコードで出力していきたいと思います。
ある値のインデックス番号を取りたいときは、np.where関数がとても便利です。では実際に使っていきます。
np.where(n_visitor_each > 100000)[0].min() +1
#実際に実装してみると分かりますが、
#np.where(n_visitor_each > 100000)
#上のコードのみを実装すると、10万を超えているインデックス番号が出力されます。
#今回知りたいのは10万人をこえる最初の日数なので、[0]としています。
#また、+1としているのは、0日目というのがそもそもこの世に存在しないからです。
#出力結果
11一回の試行の場合、11日目に10万人を超えると予想しています。
ただこれだとたった一回の試行回数で予測していることになるので、全く信憑性がありません。なんなら10000回くらい試行して値を決めたいですよね。
なので、繰り返しの試行をコンピューターにさせましょう。
def sample_day_over_3000 (max_day=14):
n_visitor_each = np.random.poisson(lam=100, size=max_day)
n_visitor_each = n_visitor_each.cumsum()
pred= np.where(n_visitor_each > 3000)[0].min() +1
return pred
result = [sample_day_over_100000() for i in range(10000)]今回はPythonリスト内包表記という使い方で、10000回の試行をリストに格納しました。
resultには先ほどの結果が10000個存在します
実際に試してみてください。
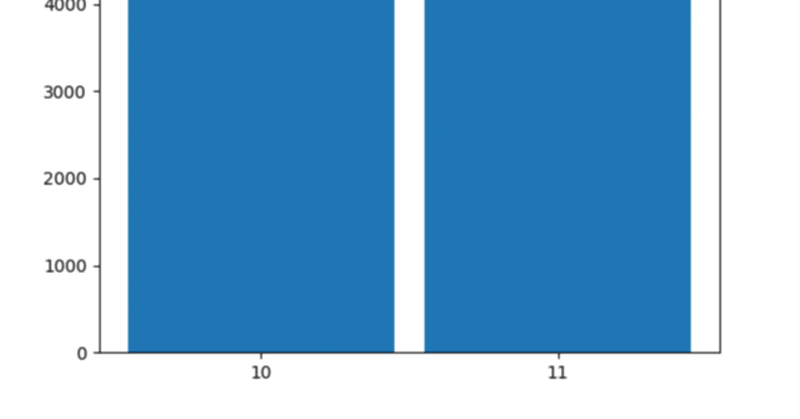
さて、10000回の試行結果がどうなったでしょうか。グラフにしてみましょう。
# ユニークな値とその発生回数を出力
unique_count , cnt = np.unique(result, return_counts=True)
#棒グラフで表示
plt.bar(unique_count ,cnt,width=0.9,tick_label=unique_count)
plt.show()
10000回の統計的シュミレーションの結果から一週間のイベントで来場者数を10万人にすることは難しいと考えられます。
そのため、一年前の同様のイベントよりも集客を増やす施策をする必要がありますね。
統計的シュミレーションで大事なことは、パラメーターは何か
今回の確率変数は何か
その確率変数はどんな確率分布に従っているのかを把握することが必要です。
私もこれからより多くのビジネスケースにおいて様々な見解を増やしていきたいと思います。
ご覧いただき、誠にありがとうございました。
この記事が気に入ったらサポートをしてみませんか?