
広告運用におけるデータマネージメントの仕組み作り

こんにちは、Carat中井です。
Caratでは転職アプリGLITを運営していますが、転職という領域では、ユーザーが中長期的にリテンションしないという特性があります。
そのため、常に新規ユーザーを獲得する必要があり、広告運用は大きな事業イシューの1つと言えます。
そんな広告運用で重要なのが、データを可視化し、課題を特定し改善するPDCAをしっかり回していくことです。
広告周りのデータの更新・反映の仕組みに課題があったので、改善した話を今回は出来ればと思います。
課題感
広告運用のオペレーションに下記のような課題があったため、改善を進めました。
複数のデータソースからデータを集計する必要がある
広告媒体の管理画面:広告コスト・imp・click等のデータ
MMP(※):流入経路・アプリ内イベント等のデータ
サービスのDB:CVの実データ・売上データ等
集計しているスプレッドシートが重い
全ての更新を人力で手動更新
用途毎にファイルが作成されており、作業工数が肥大化
※MMPとは、モバイルアプリ用の広告効果計測ツールです。GLITではApps Flyerを利用しています。
解決策
集計作業の半自動化
大部分はプログラムを書いて自動化することにしました。
集計作業を観察すると、下記のような特徴があったため、コスト回収が分かりやすく、自動化する価値が明確だったので進めました。
複雑/ハイコンテキストな判断が不要
全く同じ内容を日々行う繰り返し作業
日次で行うほど高頻度
下記のイメージのようなプログラムを作り、自動化することができました。
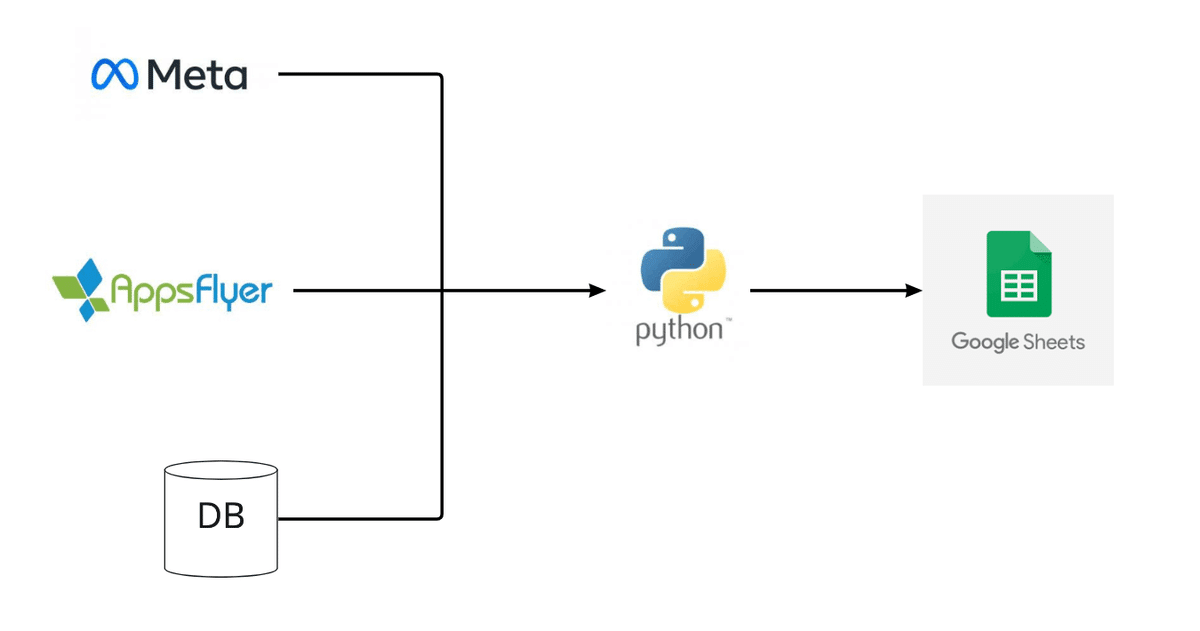
Pythonがデータの抽出・変換・格納といったETL的な役割を司っています。
各ツールが提供するAPIを利用して、データを抽出。
抽出したデータをPython上で、格納したい形式に変換・
最終的にスプレッドシートに格納しています。
データパイプラインの構造化
並行して、スプレッドシートの軽量化と更新作業の削減のため、データパイプラインの構造化を行いました。
具体的には、ローデータを蓄積するファイルと特定用途のための分析・可視化などの加工用ファイルを分割しました。

上記のように構造化することで
更新作業がデータレイクに集約され、更新工数減少
1ファイル毎のデータ保有量が減少し、軽量化
用途別にファイルの分割が容易になり、1ファイル当たりの処理量が減少し、軽量化
といった効果が得られました。
データパイプラインの構造化は、下記の記事や書籍を参考に構築しました。
(とても参考になる内容なので、今後もデータ周りの参考図書にしていきたい)
今後に向けて
既存のスプレッドシートを活かす形で更新作業の自動化をすることで、オペレーションの課題を解決することができました。
ですが、GLITのユーザー数が増加してきているのもあり、そもそもスプレッドシートに依存すること自体が厳しい状態になってきつつあります。
また広告運用以外の部分でのデータ分析も考えると、より良い状態にしていきたいと考えています。
近い将来、troccoなどのデータ統合サービス等を利用し、より生産性の高い状態にしていければと思っています。
最後に
Caratでは転職活動における負をいっしょに解消してくれる仲間を絶賛募集中です。
以下の募集ポジションを現在積極募集しています。
募集ポジションに当てはまらない方でも、少しでも興味を持っていただけた方は中井のTwitterまでお気軽にご連絡ください。
この記事が気に入ったらサポートをしてみませんか?