
【E資格】AlphaGo【AI】

こんにちは
E資格合格を目指すサラリーマンのゆゆです。
前回、前々回で黒本と呼ばれるE資格唯一の問題集を解いた話をさせて頂いたのですが、その黒本の第17章にある「AlphaGo」の問題がまったく解けませんでした。
もちろんAidemyの教材でもAlphaGoは勉強したし、ネットでも調べたのですが、結局AlphaGoが何をしているのかわからなく問題の内容を理解すらしていなかったという感じです。
ということで、さすがにAlphaGoの仕組みをまったく理解していないのはマズイと思い書籍を買って勉強しました。
◆最強囲碁AI アルファ碁 解体新書
・書籍内容
さて、勉強させて頂いた書籍は「最強囲碁AI アルファ碁 解体新書 増補改訂版」です。
内容は、AlphaGoの対局レポートやゲームAIの歴史から始まり、ディープラーニング(CNN)、強化学習について、そしてAlphaGoの中身が書かれており、簡単ではないですがE資格を勉強している人であれば読み切れる内容だと思います。
一方で、AIについて何も知らないけどAlphaGoのこと知りたいという人には少し難しいかもしれません。
私は小学生・中学生のころ囲碁をしていたことも相まって、比較的短時間で読み終えることができました。(AlphaGo ZEROは読んでませんが笑)
・感想
非常に勉強になり買って正解でした!
やっと黒本の問題文が何を言っているかわかるようになりました!
(遅すぎ・・・笑)
もし私のようにAlphaGoが何しているのかわからないという方がいましたら、ぜひこの書籍を読まれることをオススメします!
もちろん原論文を読んで理解するに越したことはないですが。。
◆ゆゆ的AlphaGoの理解
ここからは、私が読んで終わりだとわかった気で終わるのは目に見えているので、理解した内容をアウトプットしていきます。
備忘録的かつ、初めてAlphaGoを勉強する自分に教えてあげられるならこう説明するという内容ですので、正確さに欠けているのは自覚しております。
ただ、大間違い・勘違いしている箇所がありましたら、ご指摘いただけると幸いです。
・AlphaGoのイメージ


図自体が大間違いしている訳ではないと思いますが、E資格を勉強する前はAlphaGoの中身は強化学習で仕上がったスーパーAIだと思っていました。
しかし実際は下図のように「3つのAI」を駆使し、制限時間いっぱいまであれやこれや手を考え、たぶんこれが最適解だろうという手を打つ意外と泥臭い作業をするAIでした。


泥臭いと言ってもAlphaGoの中身にがっかりした訳じゃなく、むしろこんなに考えて設計しているんだと感動でした!
・4つのAI
さきほど「3つのAI」と書いたのですが、学習時をあわせると4つのAIが存在します。
実戦(対局)で活躍する選手として
・バリューネットワーク
・SLポリシーネットワーク
・ロールアウトポリシー
そして、バリューネットワークを学習する際に使われるコーチとして
・RLポリシーネットワーク
がおります。

ここまではAidemyの教材で何となく理解してたのですが、これらのAIがどのように実戦で使われるかまでは理解しておりませんでした。
・実戦(対局)
実戦にてどのように3つのAIを使っていくか、どのように手を決めるかを説明します。
スーパーAIができ、あらゆる次の一手に対して100%の確率で勝敗がわかるネットワークがあれば単純に一つ一つ「勝」「負」「勝」・・・と評価して、「勝」となる手を選択すればいいのですが、実際はそのようなAIにはなっておりません。
そこでAlphaGoは「モンテカルロ木探索」というアルゴリズムに、上で挙げた3つのAIをうまいこと適用させ次の一手を決めます。
下図で黒い丸と白い丸がつながっているネットワークの絵があるのですが、これは上から手番の予測が展開されている様子を表したものです。
例では黒が置かれたとして、3つの次の一手が候補として挙げられている状態を示しております。

0.5などの数字は私が勝手に名付けた「暫定勝率」なるもの。試行回数は深読みした回数を示しております。
まず暫定勝率の高くなる手を選びます。
そしたらプレイアウトと呼ばれる深読みを行います。プレイアウトは2,3手先を展開するのではなく、ゲームで勝敗(200手先くらいまで続く)がつくまで対戦シミュレーションを行います。
このときシミュレーションで用いられるのが、「ロールアウトポリシー」です。
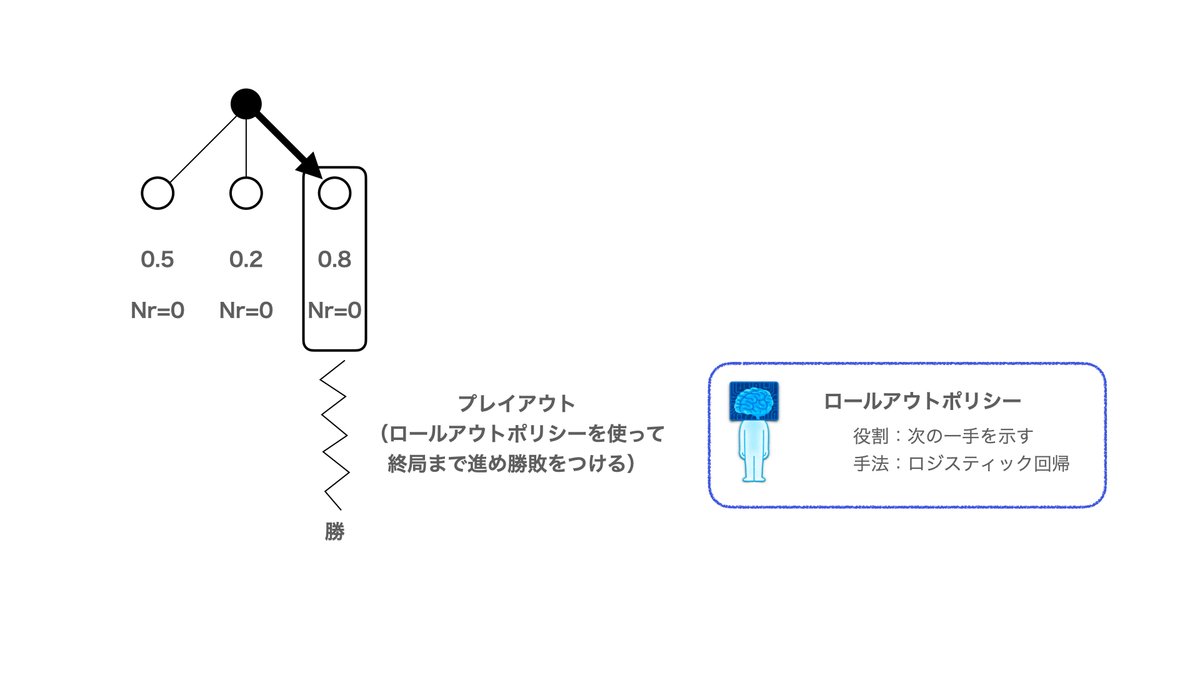
ロールアウトポリシーは「ロジスティック回帰」で学習したAIで「次の一手」を出力します。似たようなものにCNNで学習させた「SLポリシーネットワーク」がありますが、なぜ「SLポリシーネットワーク」を使わないかというと、遅いからです。
もちろん精度は「SLポリシーネットワーク」の方が高いのですが、いかんせん遅いためプレイアウトで使っていたら、200手先まで進めている間に持ち時間が終わってしまうということになってしまします。
なので、プレイアウトでは精度で劣るが速い「ロールアウトポリシー」を使います。
プレイアウトの結果、勝ったり負けたりするのですが、その結果を暫定勝率に反映させます。そして、試行回数も+1して更新します。
(図中の更新値は適当に書いております)

シミュレーションを進めていく中で「暫定勝率」は上がったり下がったりするのですが、何回か繰り返すと規定値以上の試行回数を終えた「手」が出てきます。
下の例ではその回数を10回としました。

規定以上の試行回数を超えたら、その「手」からさらに先読みを行います。
ここで用いられるのが「SLポリシーネットワーク」と「バリューネットワーク」です。
「SLポリシーネットワーク」は次の一手の候補を選び出します。
「バリューネットワーク」はその手の勝率を出力します。
あとは同じように暫定勝率の高い手からプレイアウトをして、暫定勝率を更新というのを時間制限がくるまで行います。
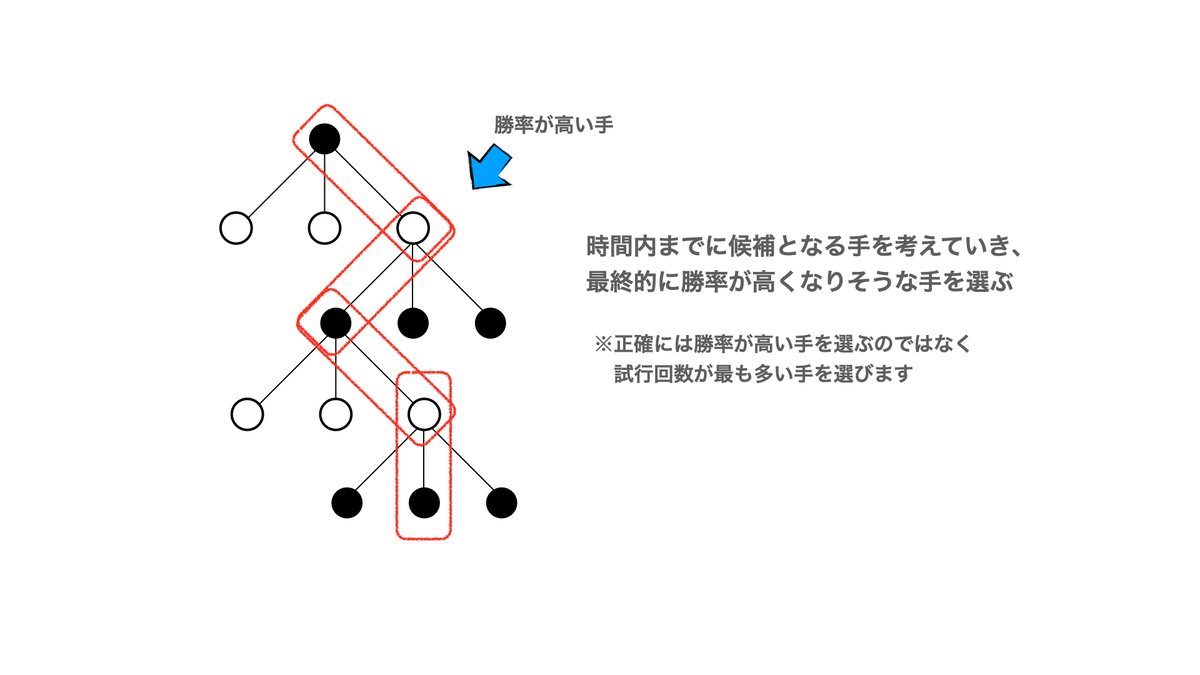
時間制限が来たら勝率の高い手を選び実際に石を置きます。
こんな感じで「次の一手」を決めていくのですが、AlphaGoではここに挙げたものだけではなく、色んなことがものすごく工夫されていています。
例えばCNNに入力する画像のチャンネル数は48もあるのですが、その考え方もすごく工夫されております。
◆最後に
肝心の黒本の問題を解けるようになったかですが、半分は解けるようになりました。
「最強囲碁AI アルファ碁 解体新書 増補改訂版」のAppendixに数式の話が乗っているのですが、黒本と若干表記が異なっており、そこのところが私の中で一致できていません。
最終的にはわからなければ暗記しかありませんが、暗記するにもある程度は考え方を抑えておきたいと思います。(暗記しないといけない数式は他にもいっぱいあるし笑)
一部でも数式の内容を記載できたらnoteに書きたいと思います。試験が差し迫ってて書けないかもしれませんが、落ち着いたあとでも書きたいと思います。
そもそもAlphaGoって試験に出るのだろうか・・・
この記事が気に入ったらサポートをしてみませんか?