本論:タイトルなし(考察のつづき)
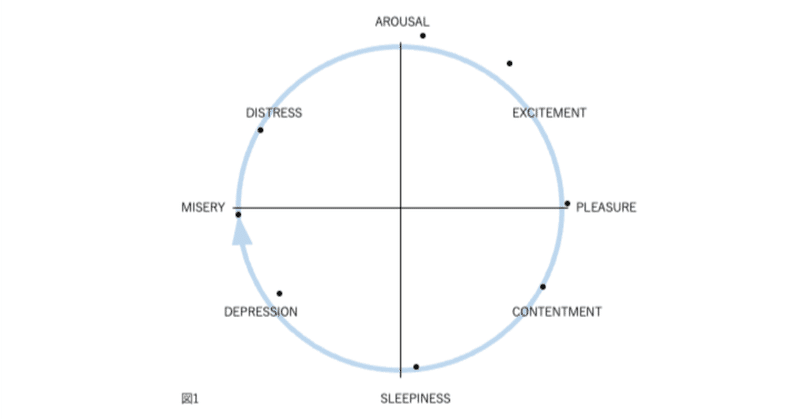
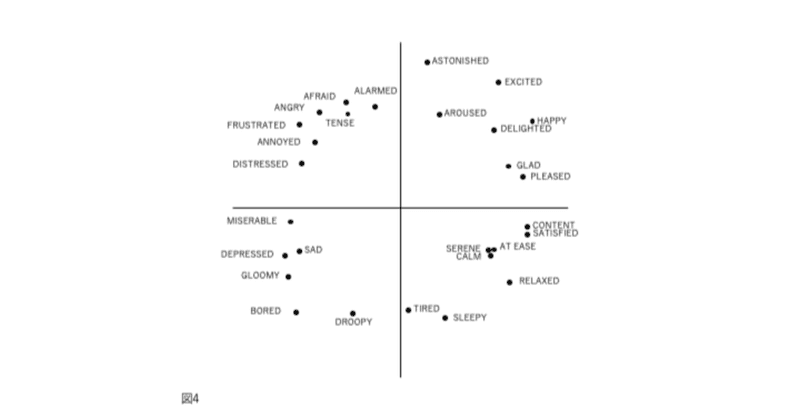
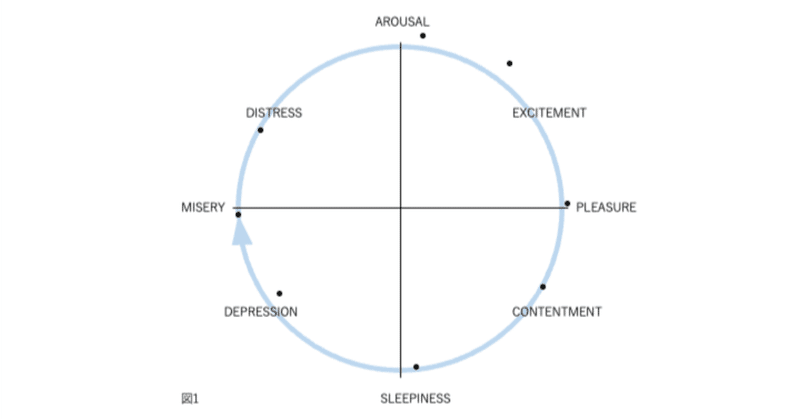
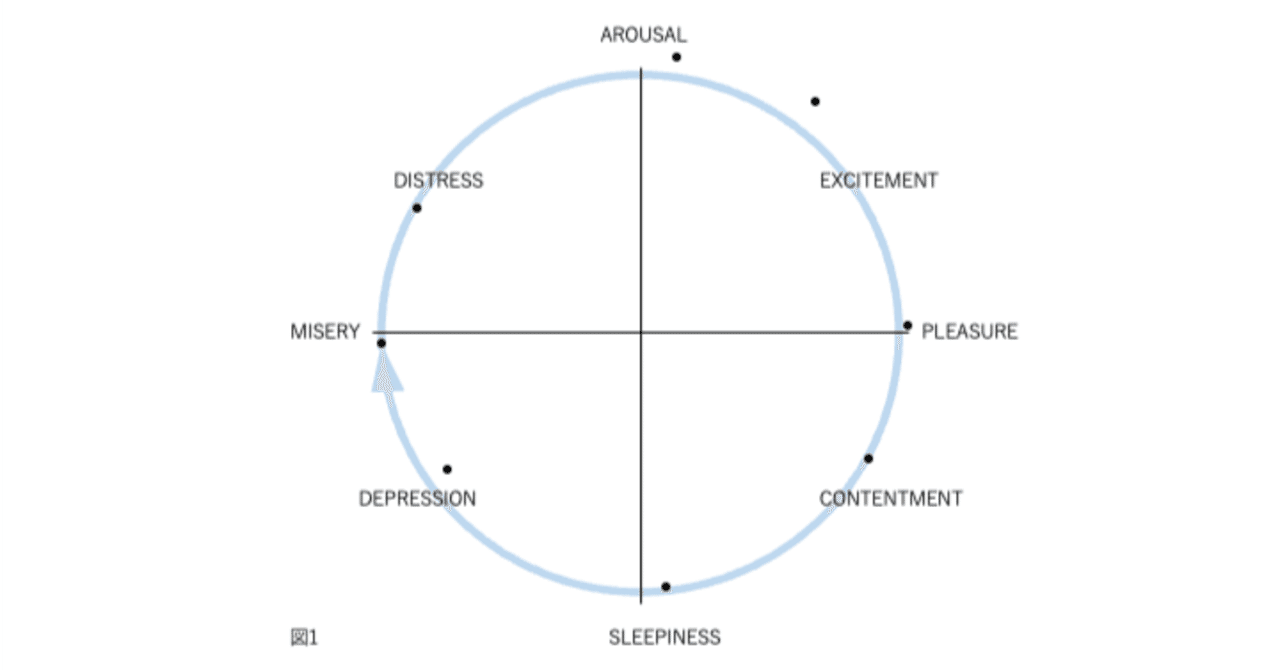
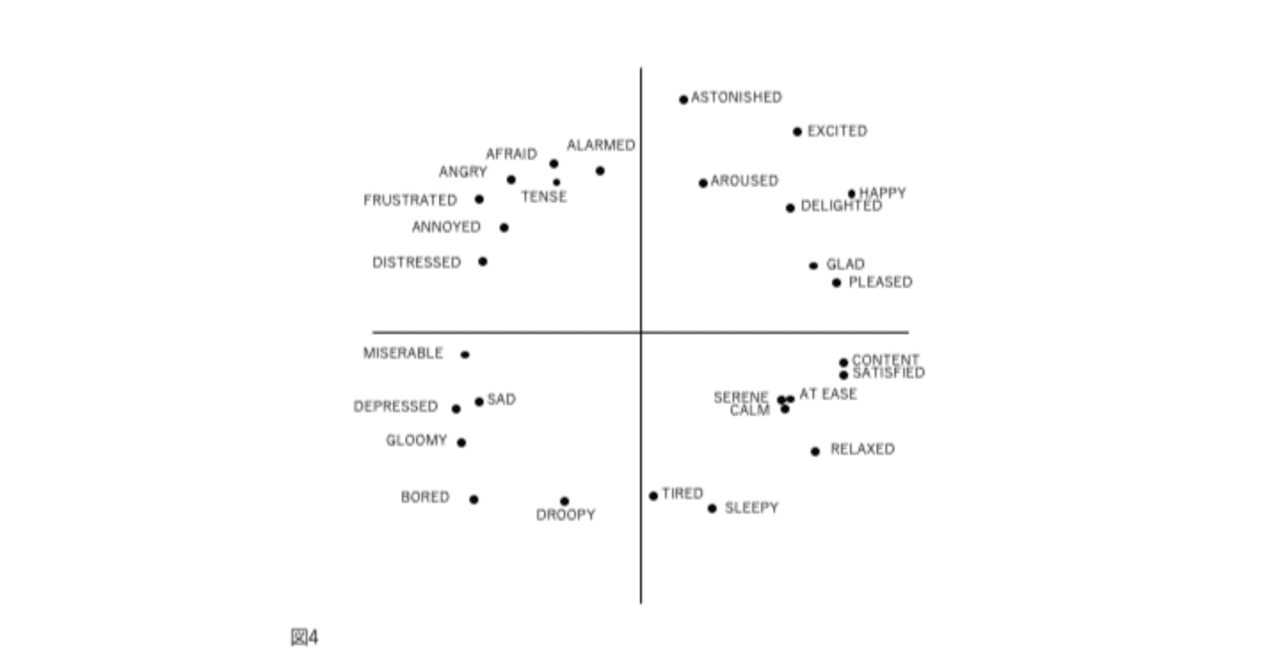
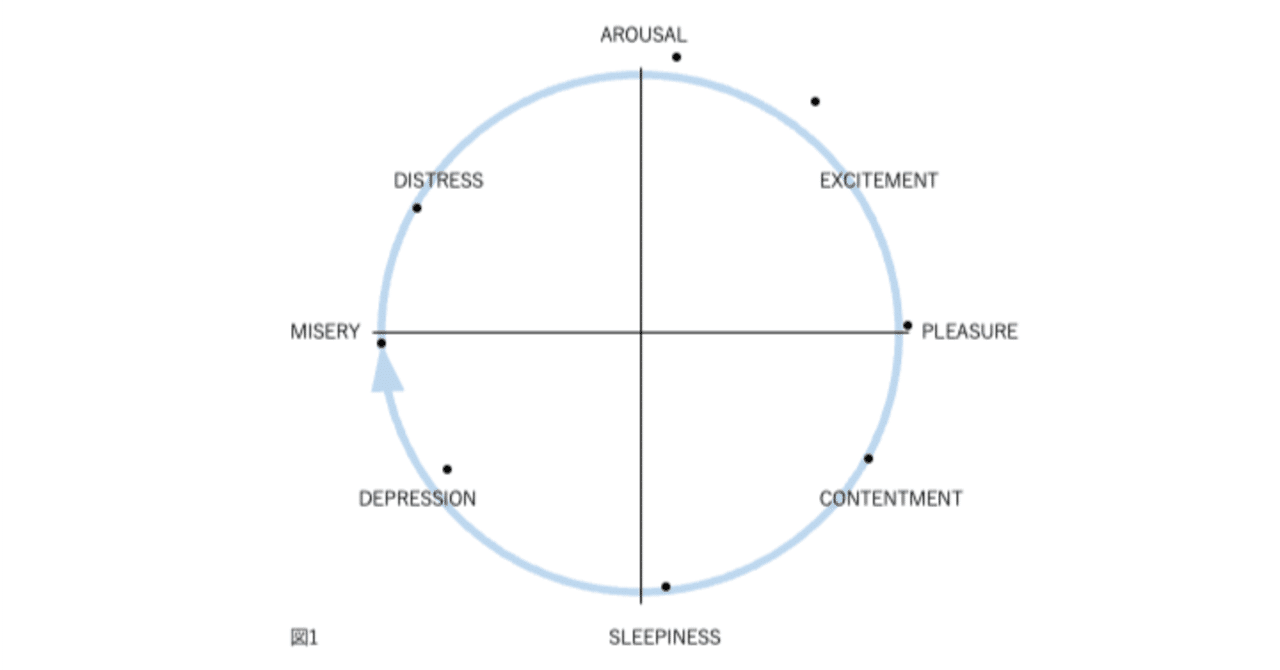
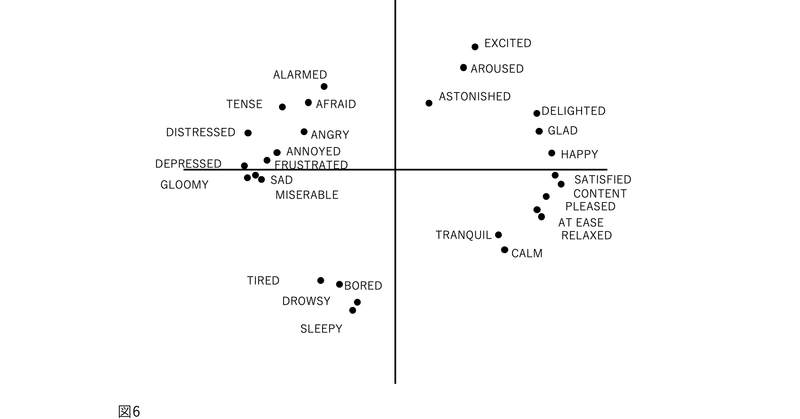
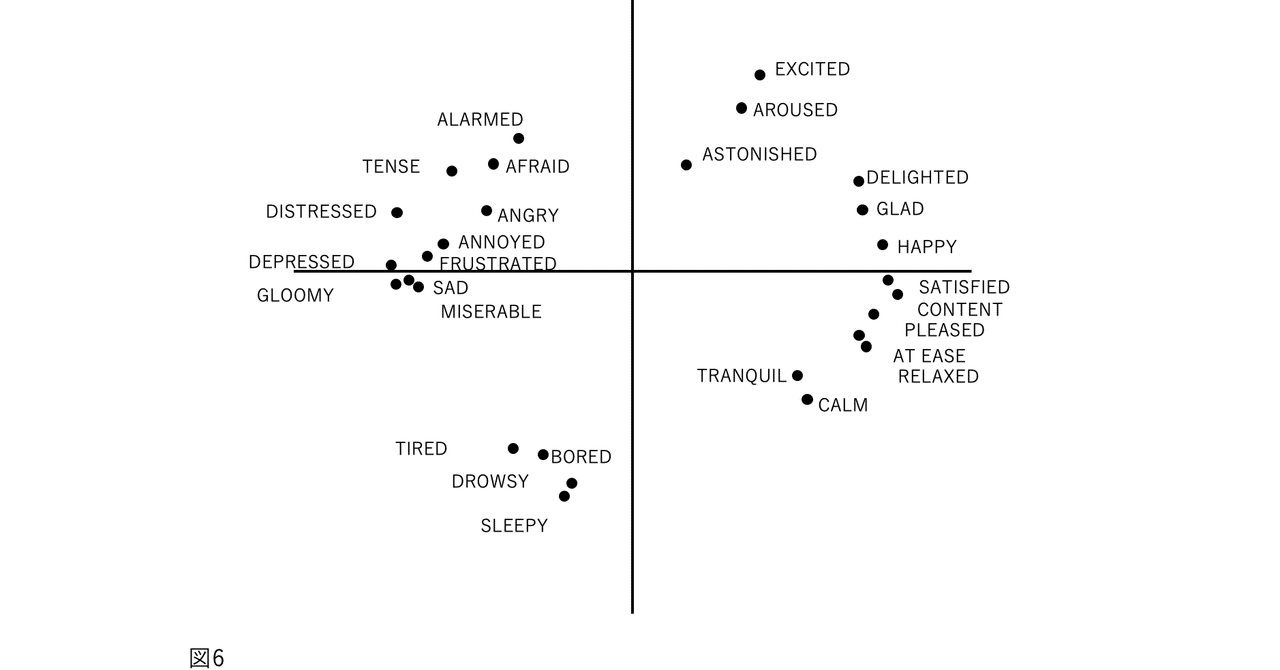
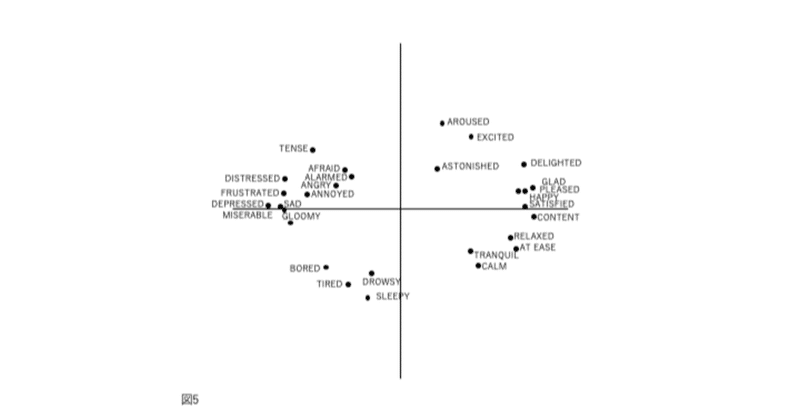
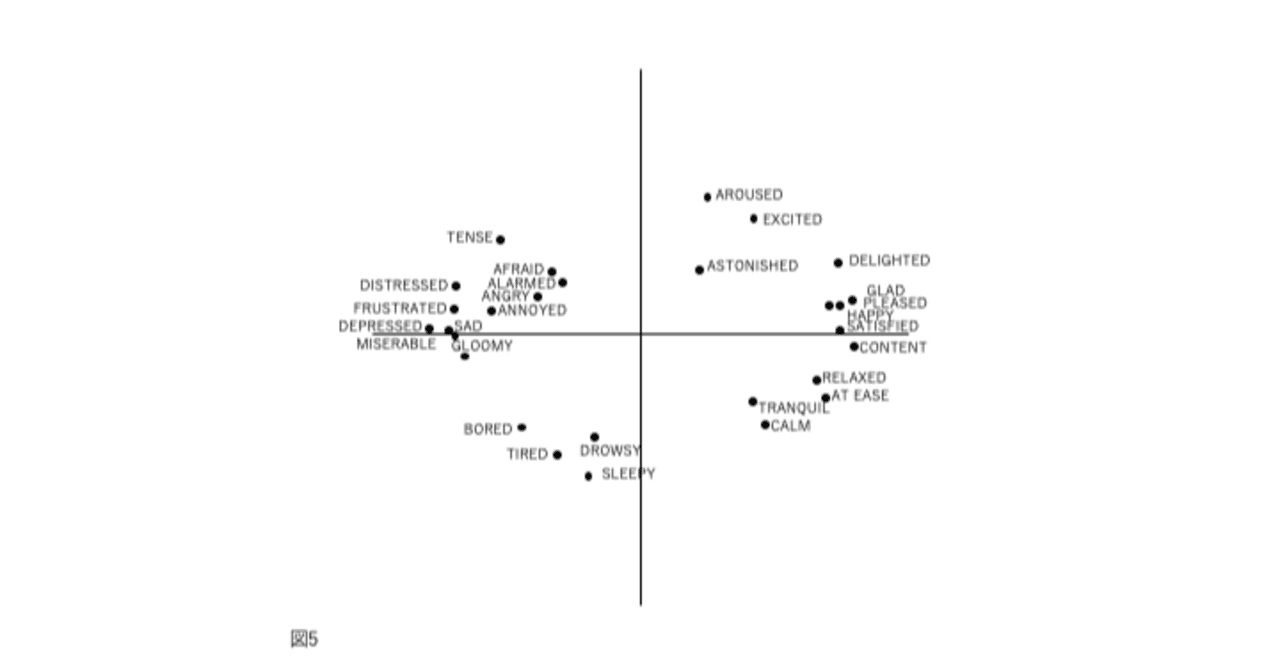
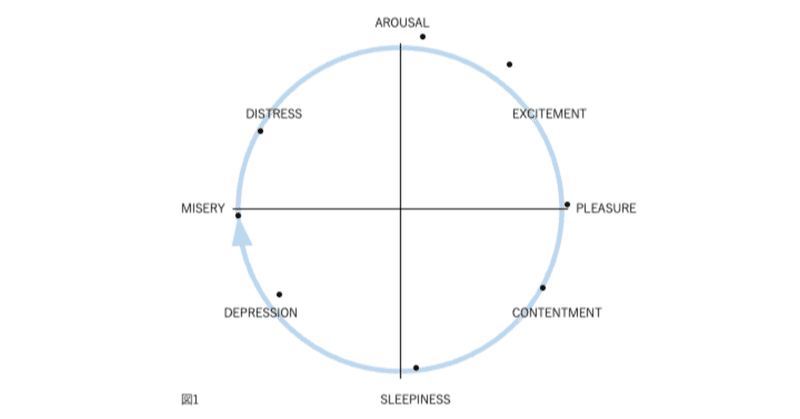
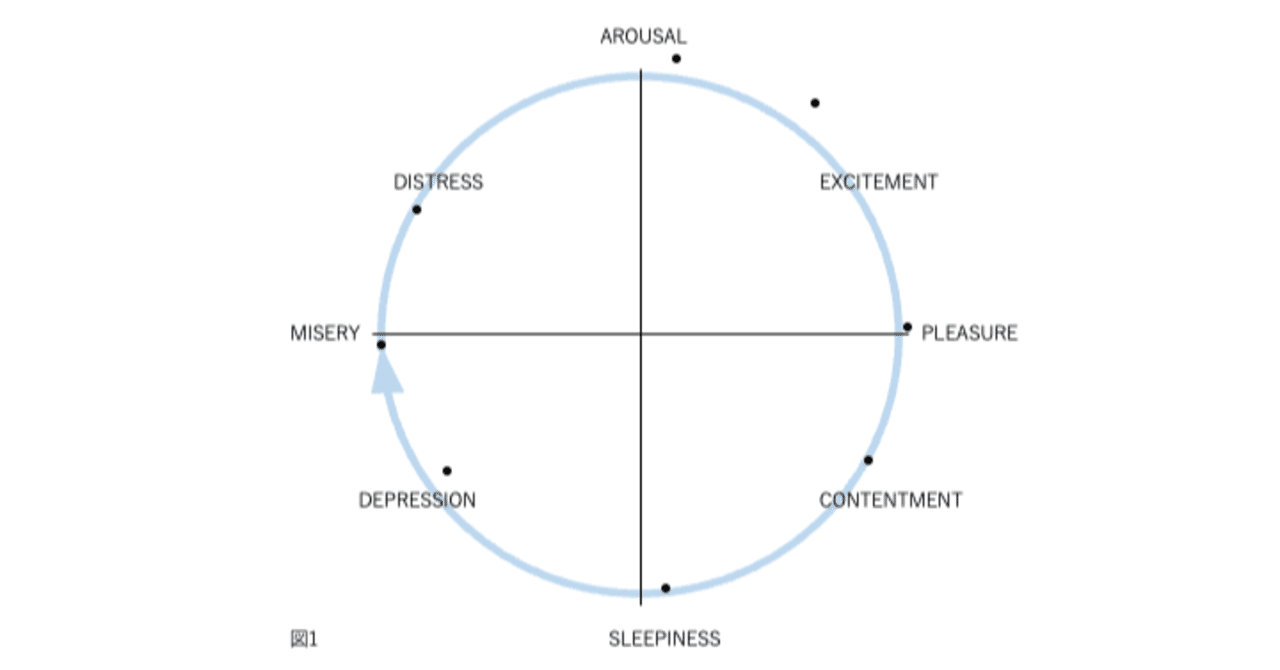
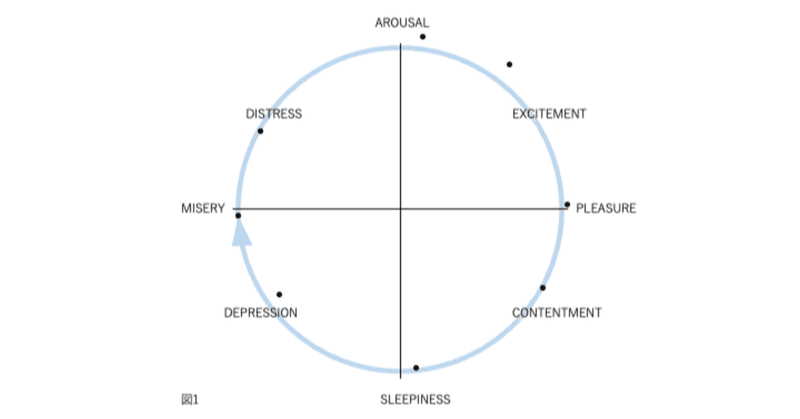
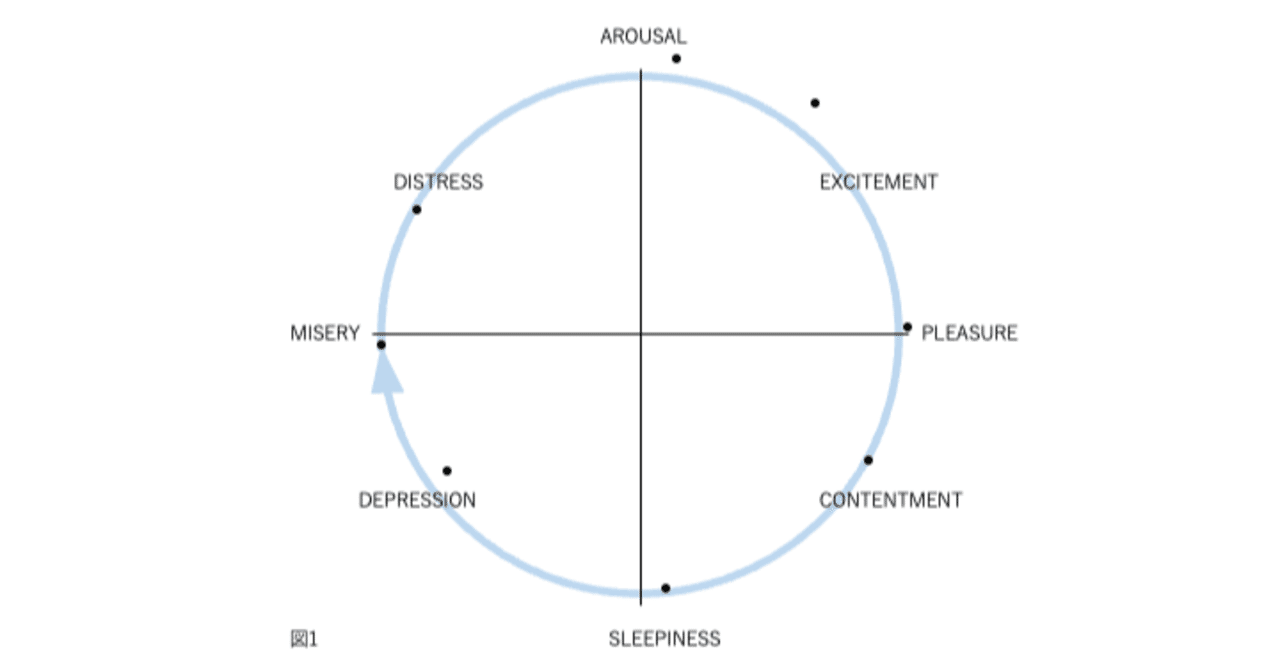
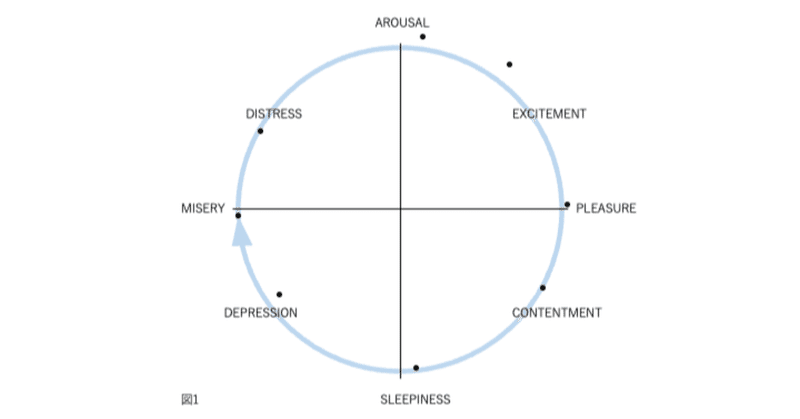
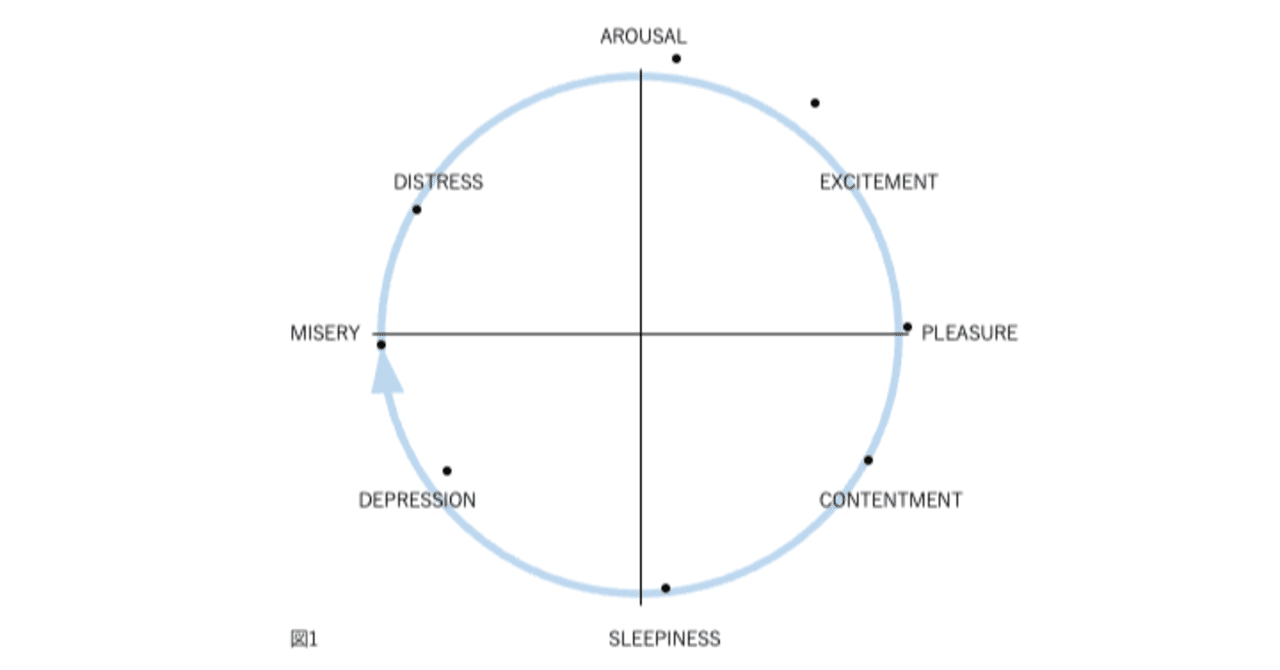
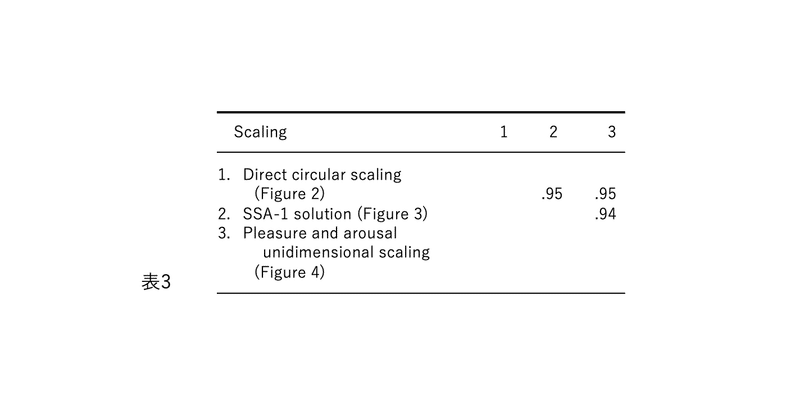
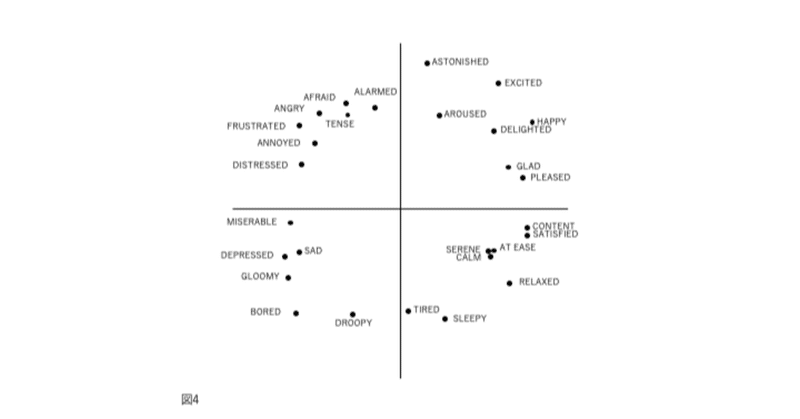
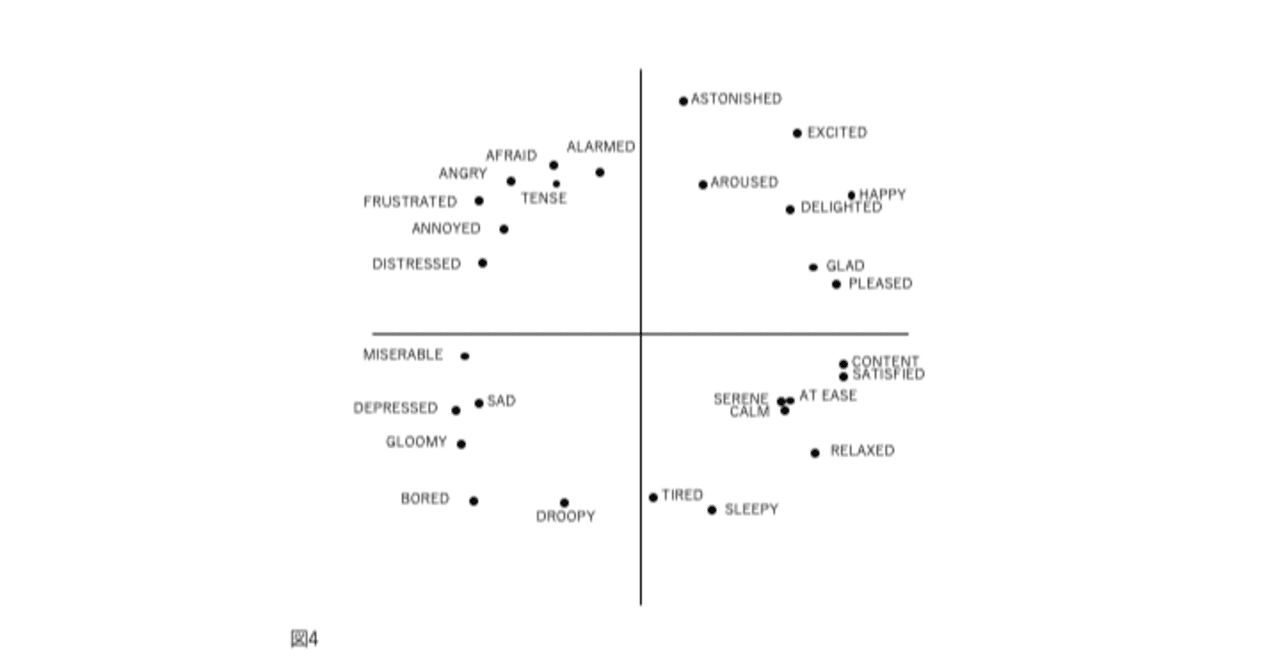
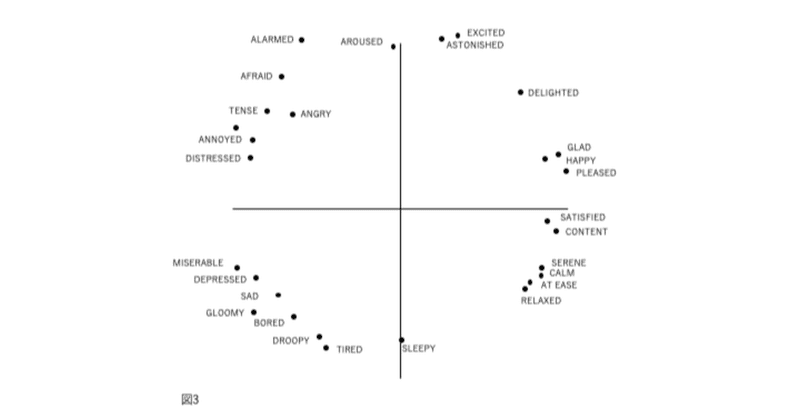
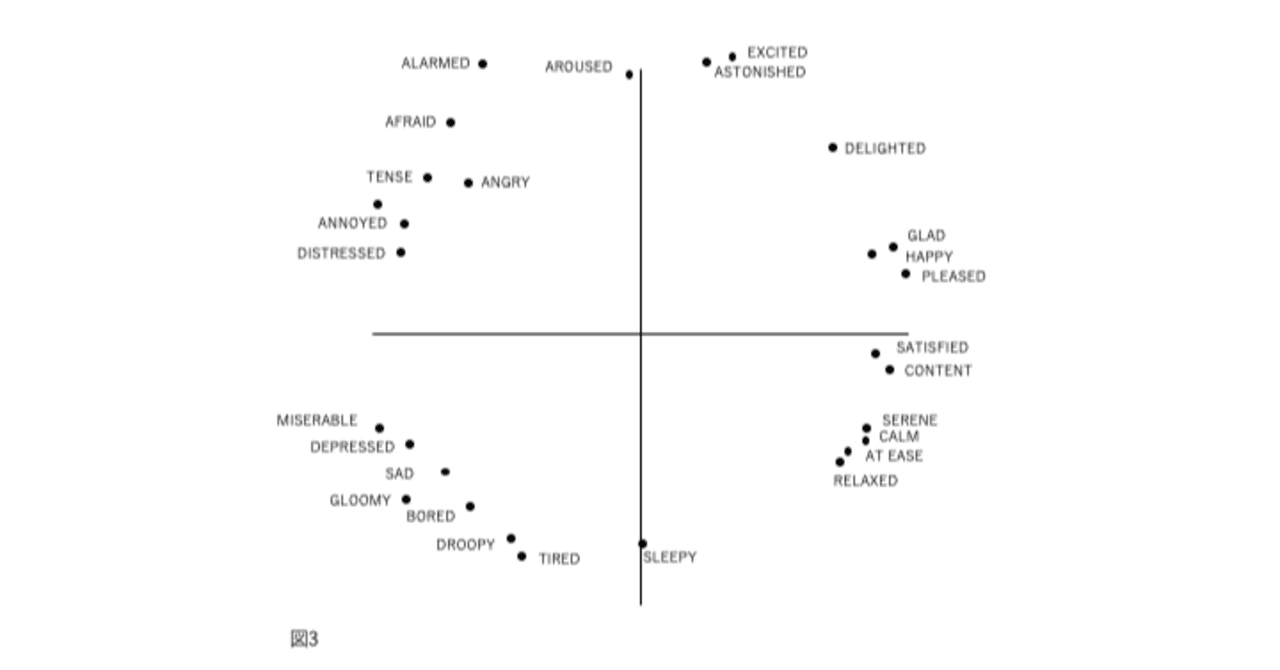
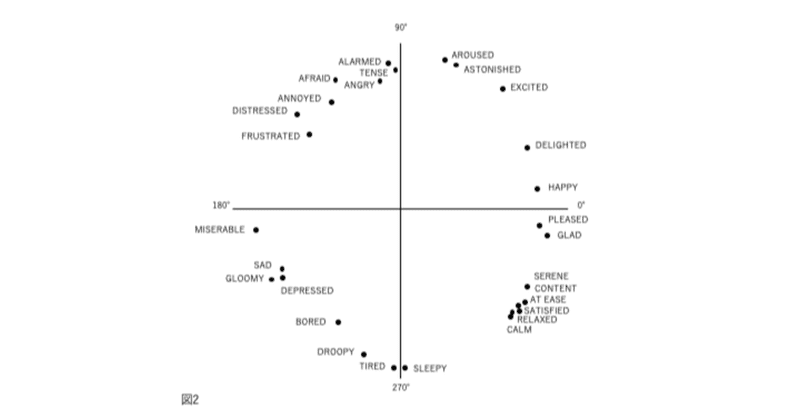
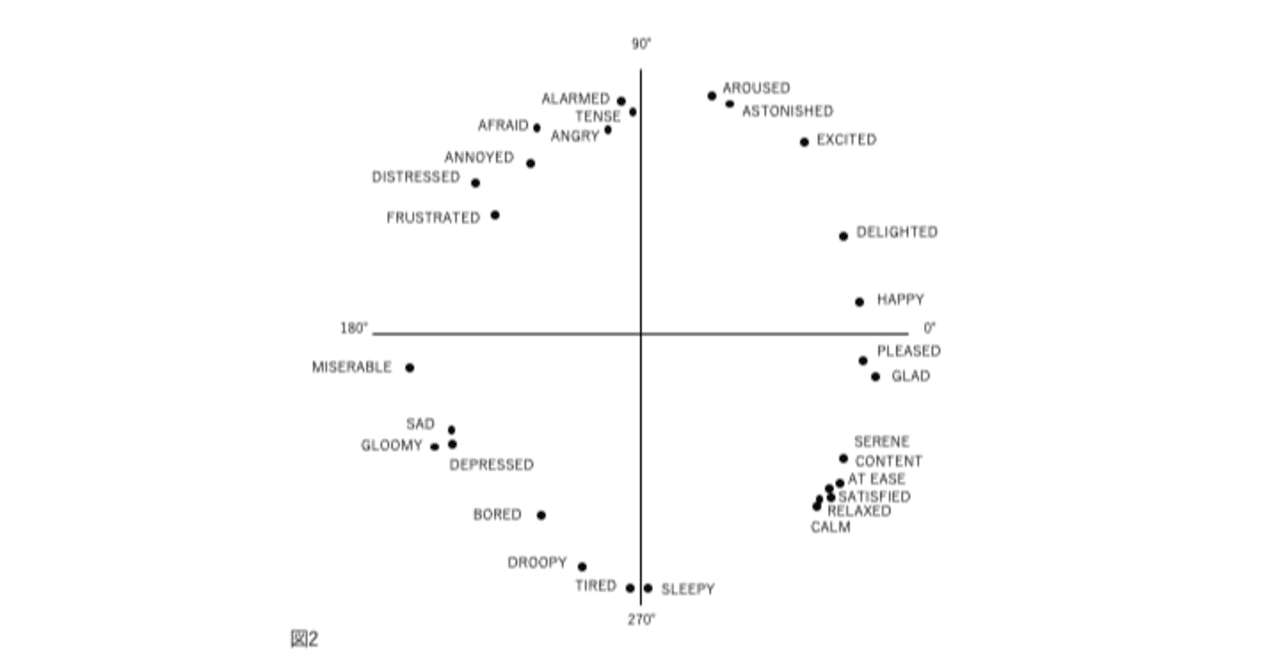
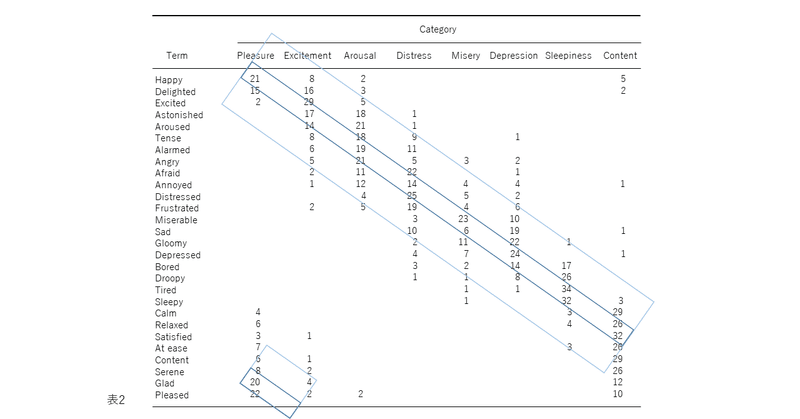
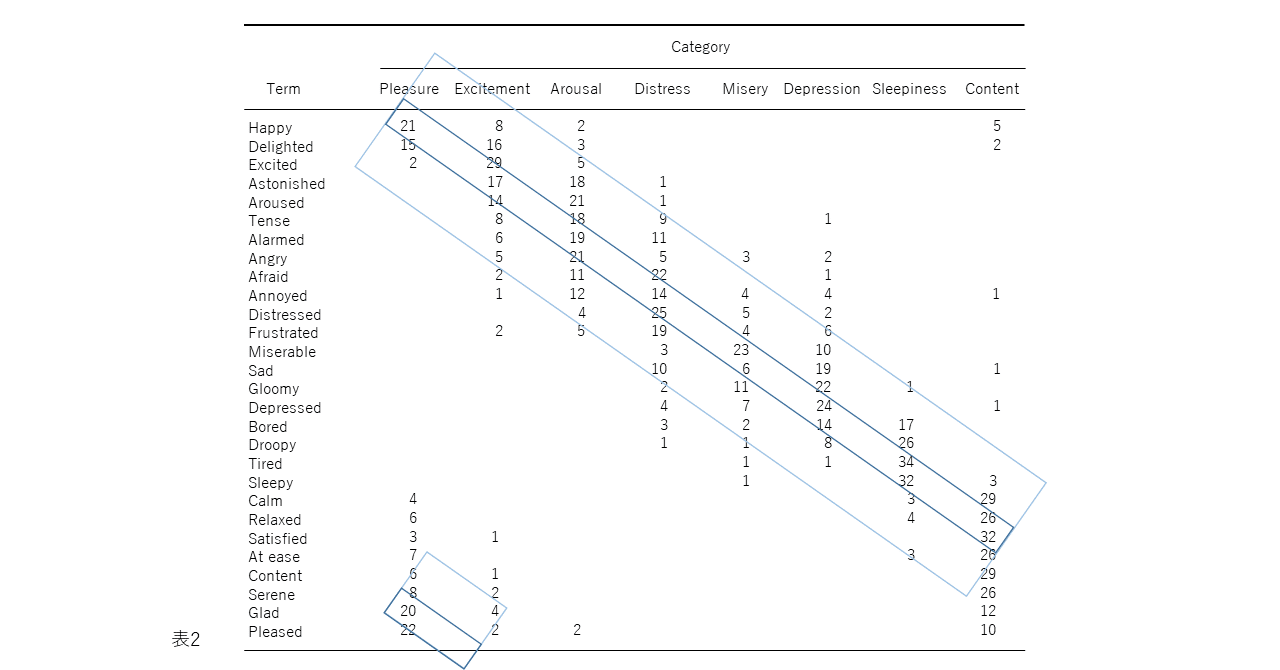
図1、2、3、および4の表現が因子分析構造と異なる4番目の理由は、後者が追加情報を含むことです。図2では、感情用語の位置は概念的な重複を反映しています。意味が重複しているため、「幸せ」は「喜々とした」に近い。「幸せ」は概念的に異なるため、「眠い」とほぼ直交します。自己報告データの因子分析研究では、相関係数はこの程度の概念的な重複を測定します。「幸せ」をチェックした被験者がだいたい「喜々とした」もチェックするのは、これらが偶然に共に起きた2つの別個のイベントではなく、これらの言