本論:タイトルなし(考察のつづき)




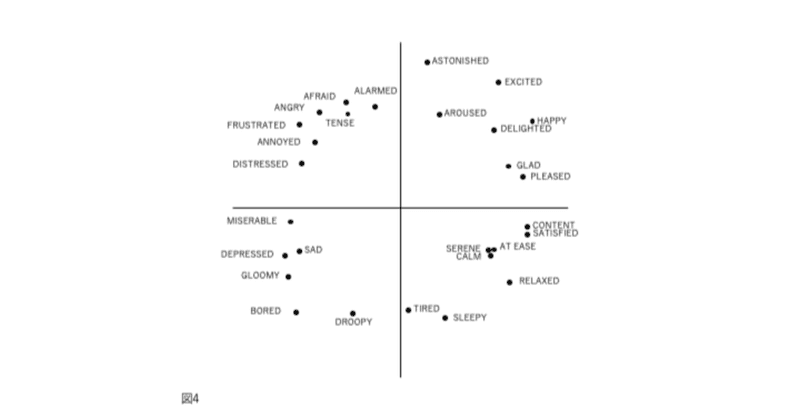
図1、2、3、および4の表現が因子分析構造と異なる4番目の理由は、後者が追加情報を含むことです。図2では、感情用語の位置は概念的な重複を反映しています。意味が重複しているため、「幸せ」は「喜々とした」に近い。「幸せ」は概念的に異なるため、「眠い」とほぼ直交します。自己報告データの因子分析研究では、相関係数はこの程度の概念的な重複を測定します。「幸せ」をチェックした被験者がだいたい「喜々とした」もチェックするのは、これらが偶然に共に起きた2つの別個のイベントではなく、これらの言葉がしばしば同じ感情状態を表すからです。ただし、相関係数は共起の可能性も測定します。たとえば、ここでの最初の一連の研究は、「快-不快」が「覚醒度」と概念的に区別されることを示しました。ただし、これらの2つの次元は、現実の世界では相変わらず変化します。 (例えば精神年齢と体重は、概念的には異なるが、経験的には変化する)。実際、自己報告データでは、快と覚醒の尺度が中程度に相互相関していることがわかりました。
快(喜び)と覚醒は、たとえ概念的に明確であっても、喜々とした(+快/+覚醒)または退屈(-快/-覚醒)など、これら2つの成分が等号で現れる感情状態に正の相関がある場合、怒り(-快/-覚醒)や静けさ(+快/-覚醒)など、2つの要素が反対の兆候で生じる感情状態よりも頻繁に発生します。怒っている人よりも退屈している人が多いか、静かな人よりも喜々としている人が多いと考えられます。 (私たちのサンプルでは、退屈の平均スコアは怒りの平均スコアよりも大きく、喜々としたの平均スコアは静かな平均スコアよりも大きかった)。さまざまな感情状態の頻度のこれらの違いは、それらの状態の測定値の間で観察される相関に反映され、順番にそれらの状態の因子構造に反映されます。ただし、さまざまな感情的状態が発生する頻度は、その状態の意味を構成する概念的な成分とは別の問題です。
要するに、ここで最初の3つの研究で採用された判断タスクが必然的にいくつかのユニークな分散をもたらしたように、被験者の大規模なサンプルからの自己報告データによって感情を調査することは必然的にその方法論にいくらかのユニークな分散をもたらします。このユニークな分散よりも興味深いのは、4つの異なるスケーリング方法が多くの分散を共有しているという現在の発見です。
この記事が気に入ったらサポートをしてみませんか?