
臨床における良い予測モデルとは?

はじめに
前回、予測モデルの研究について少し書きました。
(よければこちらを先にお読みください)
今回はその臨床現場において予測モデルを評価する上で重要と思われる指標について書きます。
(この記事では生存・死亡などの二値変数のアウトカムについて書きます。)
予測モデルとは
予測モデルとは手元のデータから予測したいものの確率を計算する計算機です。臨床的によく用いられているのは予後(院内死亡などの悪いイベント)を予測するタイプのモデルで、簡易的にスコアで計算できるタイプが多いです。例:CURB65スコア、CHADS2スコアなど
臨床における予測モデルの目標
予測モデルの究極的な目標は、これです。
「予測に基づき治療方針が変化し重要なアウトカムが改善する」
例えば、救急外来にいる患者さんの予後を予測し、状態が悪化する確率が高ければ、悪化しないように先手を打つ事ができます。その結果、悪い結果を回避することができれば、予測したことに重要な意義があります。
逆に、予測しても未来が変わらない、患者アウトカムもコストも何も変わらないのであれば、その予測が必要かどうか疑問です。
予測の最大の目標である「重要なアウトカムが改善する」かどうかを本当の意味で評価するためには、「もし予測せずに治療してたらこの患者はどうなっただろうか?」を考える必要があります。
実際には「もし」の未来を評価することはできません。
なのでランダム化比較試験で
「予測で治療を決める介入群」と
「予測を用いないで治療する対照群」の
アウトカムを比較するのが理想です。
(前回記事のステップ3にあたります(1))
そもそも予測モデルは当てになるのか?
しかし、そもそも、、
予測モデルの予測が正しくなければ、それはただの不要な情報です。
ですので「予測に基づき治療方針が変化し重要なアウトカムが改善する」ことを目標とする前に、まずは「予測モデルの予測が信じるに値するかどうか」を評価することが必要です。
(前回記事のステップ1、2にあたります)
予測モデルの評価指標
予測モデルの評価指標としては、
・識別能 (Discrimination)
・較正能 (Calibration)
・臨床的有用性 (Clinical utility)
などがあります(2,3)。
識別能 (Discrimination)
識別能は「予測モデルが正しく予測対象のイベント発生のリスクが高い患者とリスクが低い患者を区別できる性能」を表しています。いわゆるROC曲線のArea Under the Curve(AUC)で評価されます。
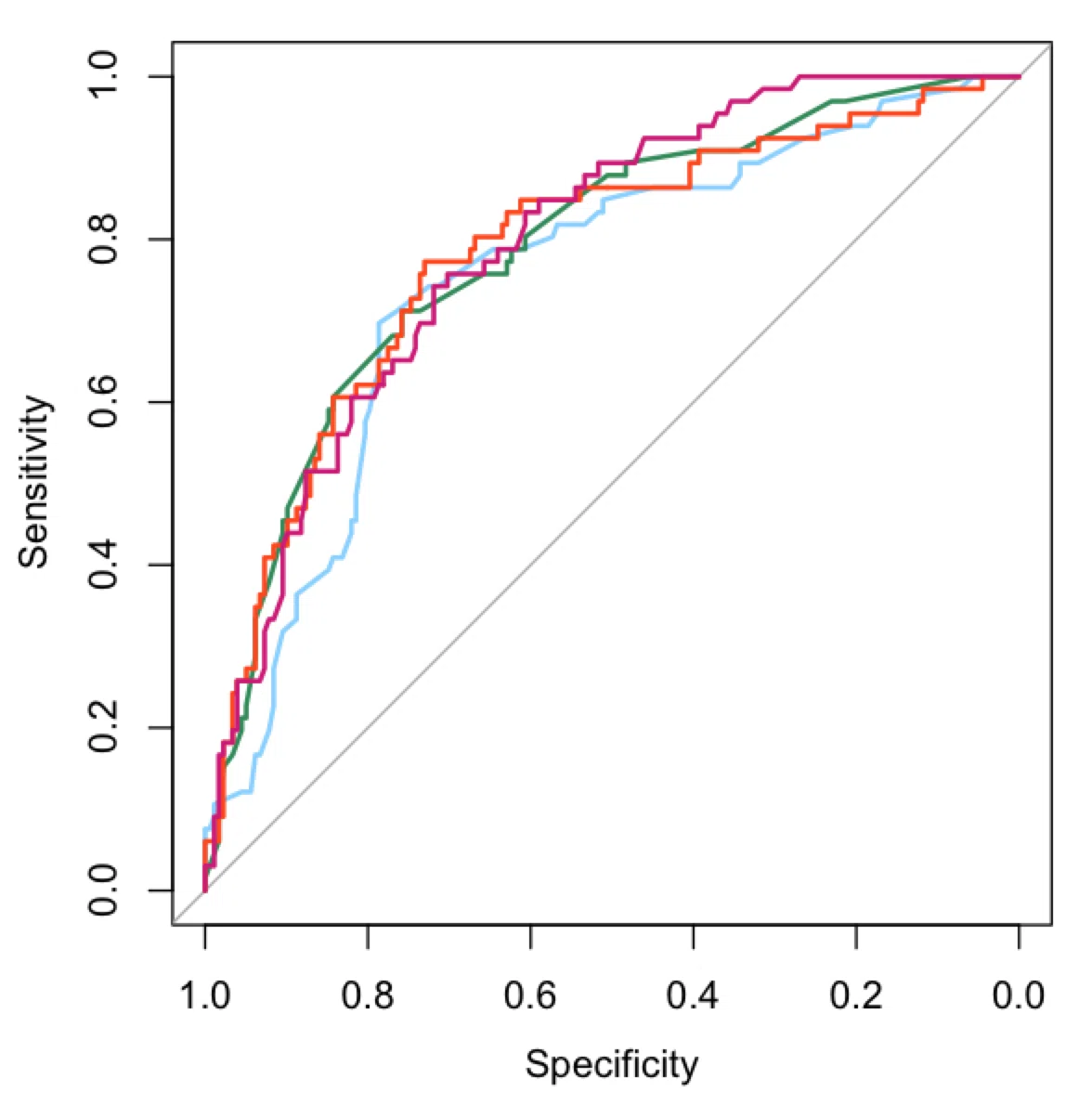
しかし予測モデルの評価のためには、このROC曲線のAUC(C統計量とも呼ばれる)だけでは不十分といわれます(1)。リスクが高い患者とリスクが低い患者を区別できる性能(AUCが高いこと)は臨床での有用性を反映しないからです。
例えば、死亡リスクが1%の患者と2%の患者を精度高く識別できたとしてもあまり臨床的な有用性はほとんどなく意思決定につながらないと思われます。このように「識別能が高いこと」=「予測モデルの臨床的意義がある」と簡単に結びつけて考えることはできません。(しかし識別能AUCが低い予測モデルはおそらく役に立ちません。)
較正能 (Calibration)
予測モデルの性能の評価として較正能(Calibration)があります。これは「予測がどれくらい実際に当たるか」を表しています。
例えば予測モデルを用いて死亡の確率25%と予測した患者さんを4人集めます。その4人の患者のうち実際に1人が死亡した場合、「予測の死亡確率=実際の死亡確率」つまり予測が当たっている、となります。このような予測モデルは較正能が高い(well-calibrated)といえます。
較正能を評価する方法にはいくつかありますが、よく用いられているのがCalibration plotです。これは予測確率をx軸に実際の確率をy軸にとり図示するものです。

緑の線が予測モデルによる予測を表しています。y = xつまり対角の点線上であればPerfect calibrationです(予測と実際の確率が完全に一致している)。
この点線から大きく外れると予測が外れることを意味します。
このモデルだと、
予測確率が75%-100%のところでは少し過大評価(Over-estimation)
予測確率が25-70%程度のところでは若干、過小評価(Under-estimation)
のようです。例えば50%と予測した患者の実際の死亡確率は60%程度であることを示しています。しかし実際この程度の予測のブレは臨床での意思決定に大きく影響しないと思われます。
これ以外にも較正能評価の指標がありますが、ややこしいので割愛します。
臨床的有用性 (Clinical utility)
上記の二つ以外に予測モデルの臨床的有用性を評価する方法としてNet-benefitを用いたDecision-curve analysisなどがありますが、ややこしいので、また別の記事で紹介したいと思います。
まとめ
この記事では予測モデルの評価について紹介しました。予測モデルの最大の目標は予後の改善に結びつくことですが、その前提として「臨床的に意思決定に役立つ予測として信じるに値するか」を評価する必要があります。ROC曲線のAUCなどの識別能(Discrimination)が一般によく用いられていますが、どちらかというと較正能(Calibration)を評価する必要があります。
よければこちらもご参照ください!
下記の文献も参考にしてください。
文献
(1)医学文献ユーザーズガイド ―根拠に基づく診療のマニュアル 第3版 相原 守夫 (著)
(2)Clinical Prediction Models A Practical Approach to Development, Validation, and Updating, Steyerberg
(3)JAMA Users' Guides to the Medical Literature Discrimination and Calibration of Clinical Prediction Models, JAMA 2017
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?