
第13話 ディープラーニングに必要な数学知識 -正規分布-

ディープラーニングに必要な数学ということで、今回は正規分布について学びます。
第8話から行列やら微分を学んできましたが、今回でいよいよ数学の勉強は最後です。
いやあ長かった。
今回の内容は次のとおりです。
・正規分布とは
・正規分布になるデータを作ってみよう
・正規分布の曲線を描いてみよう
それでは今回の学習をスタートします!
(教科書「はじめてのディープラーニング」我妻幸長著)
正規分布とは
自然界や人間の行動・性質などの様々な現象に対してよく当てはまるデータの分布のことを、正規分布(normal distribution)またはガウス分布(Gaussia distribution)といいます。
例えばヒトの身長やテストの成績も正規分布におおよそ従うようです。へぇ。
グラフを描くと次のような形状になります。
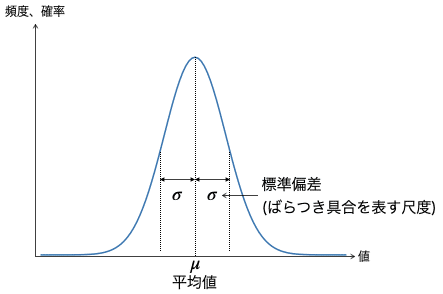
この曲線は、平均値で頻度が一番多く、平均から外れるほど頻度が下がることを意味しています。
数式表記もできて、確率密度関数と呼ばれます。
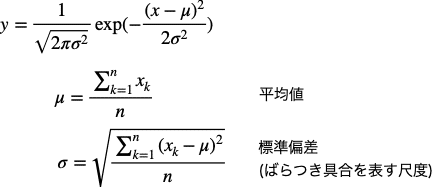
平均値と標準偏差がわかれば、正規分布のグラフを描くことができます。
正規分布になるデータを作ってみよう
NumPyのrandom.normal関数を用いれば、このように正規分布に従うデータを簡単に作ることができます。
では久しぶりにソースコードの登場です。
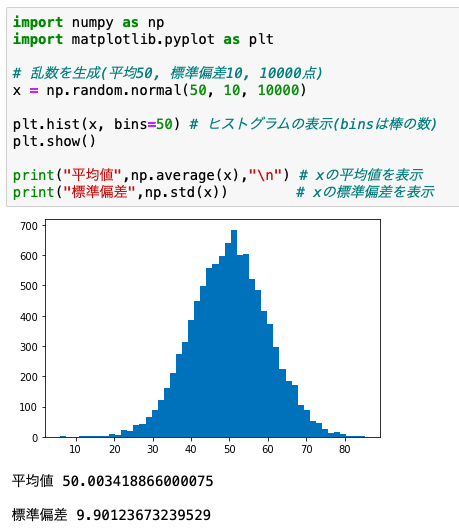
random.normalでは引数に平均、標準偏差、生成するデータ点数を渡します。
確認のため、xの平均値と標準偏差を計算してみました。
おおむねrandom.normalで指定した値と同じですね。
random.normalは実行するたびに違う値を出すので、上記のソースコードは実行するたびに出力結果が変わります。
正規分布の曲線を書いてみよう
さきほどランダム関数を使ってヒストグラムは描けましたが、やっぱりきれいな曲線を書いてみたいですよね。
というわけで書いてみましょう。
xのデータ列を作って、平均値と標準偏差を決めて、正規分布の式yを計算だ
!と意気込んだらエラーメッセージが表示されました。

うーん、なんでだろう・・・そうか!
xは配列でしたね。
y[i] = exp(-x[i]^2)ということがしたいので、xは各要素の2乗となるようにしなくてはなりません。
ということは、配列の各要素の掛け算(アダマール積)をソースコードで実装 すればいいですね。
(アダマール積が気になる人は第10話をご覧ください。)
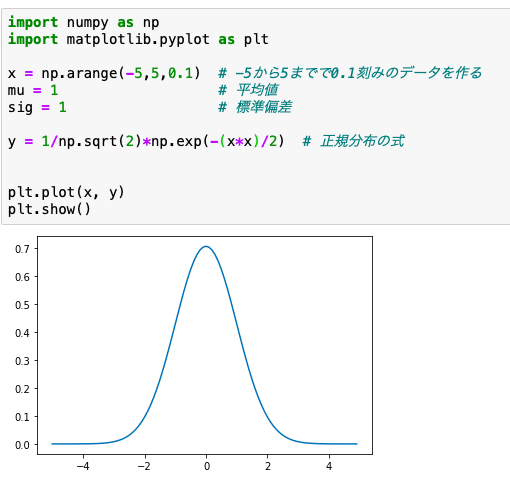
今度はうまくいきました。
数式をプログラムで実装するときは、そのままやると思うとおりの結果にならない場合があることがわかりましたね。
今回は正規分布について学習しました。
教科書では言われてませんでしたが、多数のデータを扱うときには正規分布に従うか否かは重要なポイントになりそうです。
次回からはニューラルネットワークを学んでいきます。
いよいよAIっぽい内容になってきますよ。楽しみですね。
それではまた(^_^)ノシ
よろしければサポートお願いします!いただいたサポートは書籍代等に活用いたします!