
第33話 AIの良し悪しアヤメで測る!? Irisデータセットとは

これまでディープラーニングのことを色々と学習してきましたが、今回は少し毛色が変わります。
ディープラーニングに限らず、機械学習(いわゆるAI)では学習するためのデータと、学習が完了したAIを評価するためのデータが必要になります。
そこでよく使われるのがIrisデータセットです。(Iris=アヤメ)
今回はIrisデータセットについて学習します。
Irisデータセットって?
1936年に統計、生物学者であるRonald Fisherの「The use of multiple measurements in taxonomic problems (分類問題における複数箇所の測定の使用) 」という論文に掲載されたデータセット(データの集まり)です。
これには3種類のアヤメに関するデータがまとまっています。

ちなみに元の論文はこちらです。(私は10秒で読むのを諦めました^^;)
なんでこれが使われるの?
端的に言うとめっちゃ使い勝手がよいからです。
1936年の論文が今でもあらゆるところで引用されている(その数2000回以上)というので、これを物語っていますね。
データをまとめてちゃんとした場(学会)で報告すると、箔がついて信頼性のあるデータとして認められるのですね。
中身はどうなっているの?
データセットは、3品種について4つの特徴量のデータがこんな感じでまとまっています。

ちなみに「がく」「花びら」と品種の違いはこのようになっています。

(画像はこちらのサイトから引用させていただきました。Classification of Iris Varieties)
Irisデータセットは、scikit-learn という機械学習用のモジュールから呼び出すことができます。
Anacondaにはこのモジュールが標準的に含まれているので早速呼び出してみましょう。
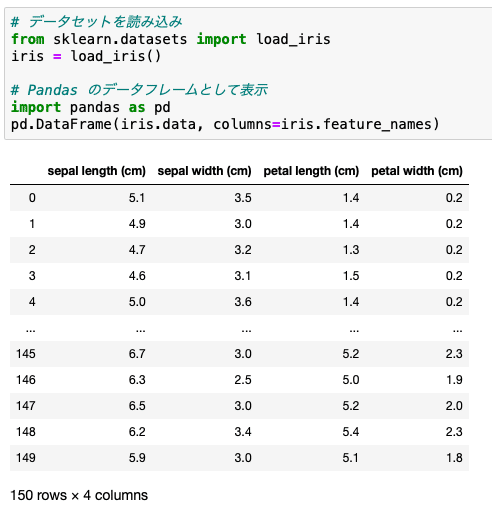
データセットの読み込み自体は2行のコードで行うことができます。
簡単・便利ですね。
できる人っぽく表示してみた
データセットは所詮データセット。
何かの検証などに利用してこそその真価を発揮するので、悲しいかなデータセットのままでは何の付加価値もありません。
せっかくIrisデータセットを学んだのにこのままでは収穫が少ないので少し遊んでみます。カッコよく表示してみます!
seabornを使うとまとめてグラフ化できるようなのでやってみましょう。
Irisデータセットの読み込みにたった2行を追加するだけです。

ご覧ください、この実行結果を!
一見してできる人っぽくないでしょうか!?

品種ごとの傾向が一見してわかりますね。
こういうデータの表示方法を知っておく大量のデータを処理するときに役立ちそうです。
今回はIrisデータセットについて学習しました。
Irisデータセット自体はただのデータの塊なので、seabornを使ったプロットの方がタメになったかもしれないですね^^;
次回からは、どういった内容にしようか検討中です。
それではまた(^_^)ノシ
よろしければサポートお願いします!いただいたサポートは書籍代等に活用いたします!