
LightGBMで株価予測(年利90%のモト)

はじめに
はじめまして、ゆーすです。note初投稿です。よろしくお願いします。
2023/6から運用している株価予測モデルがもうすぐ1年というところで、運用成績90%まで行きました!
丸1年より少し早いですが、良好な成績となり、せっかくなので解説記事を書いてみます。
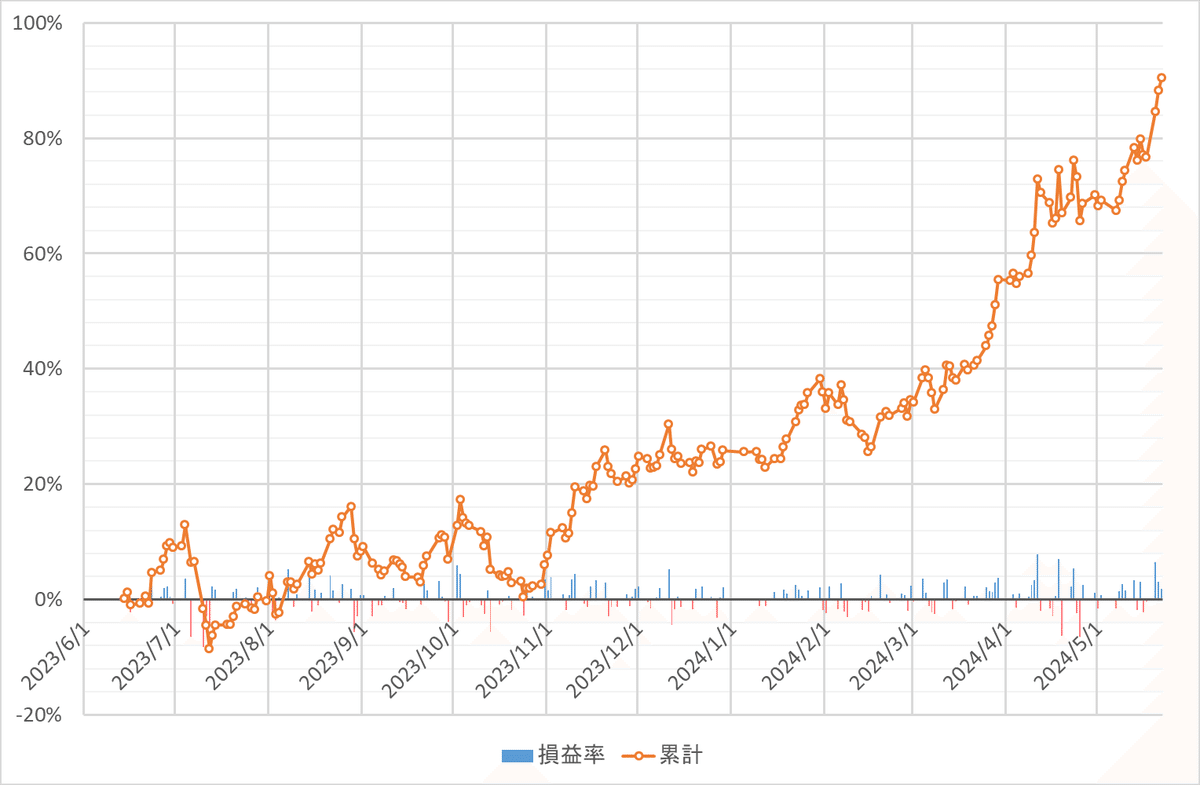
マーケットインパクトを考慮して一部特徴量や学習パラメータなどは隠してありますが、そこまで複雑な処理を入れずとも利益を出せるモデルは実現可能、ということをお伝えできればなと思います。
サマリ
対象銘柄
TOPIX500 銘柄
トレード方法
寄引トレード(寄付に買い or 売りの成行で仕掛けて、当日引けに成行で手仕舞い)
予測モデル
GBDT(LightGBM)
本記事のスコープ
この記事では以下を実装したPythonスクリプトを紹介します。
株価データのDL
目的変数の定義
説明変数の定義(簡易版)
予測モデルの構築(デフォルトパラメータ)
運用シミュレーション
一方で、例えば以下などは含まれませんのでご留意ください。
説明変数の詳細
予測モデルのパラメータの詳細
シグナルの配信方法【追記】記事を書きました
自動発注方法
資金更新方法
開発環境
ローカルのWindows 10環境でのみ動作確認済みです。
Python本体、及び各ライブラリは以下を install してください。
Python 3.11.2
numpy 1.26.4
pandas 2.2.2
tqdm 4.66.4
yfinance 0.2.38
scikit-learn 1.4.2
lightgbm 4.3.0
株価データのダウンロード
TOPIX採用銘柄の一覧を取得
まず、TOPIX採用銘柄の一覧をダウンロードしておきます。
日本取引所グループ(JPX)の「マーケット情報 > 株価指数関連 > TOPIX(東証株価指数)」にアクセス
「構成銘柄情報 > 構成銘柄別ウエイト一覧(m月末現在)」の csv ファイルをダウンロードし「topixweight_j.csv」として保存
以下の csv が保存されるので、ここから TOPIX500 の採用銘柄を取得します。

import pandas as pd
# -------------------
# TOPIX500の株価一覧を取得
# -------------------
topix_df = pd.read_csv(
"topixweight_j.csv", encoding="sjis", dtype={"コード": str})
categories = ["TOPIX Core30", "TOPIX Large70", "TOPIX Mid400"]
combined_mask = topix_df["ニューインデックス区分"].isin(categories)
tickers: list[str] = topix_df["コード"][combined_mask].tolist()これで tickers にTOPIX500の銘柄コードが取得されます。
株価のDL
yfinanceを使って株価をダウンロードします。
import datetime as dt
import os
import yfinance as yf
# -------------------
# 株価一覧のダウンロード
# -------------------
# yfinanceで扱うために.Tを追加
tickers_T = [tick + ".T" for tick in tickers]
# 過去15年分をDL (メモリ次第で調整)
# (初稿掲載時は 2009-05-25 ~ 2024-05-21)
start_date = dt.datetime.now() - dt.timedelta(days=365 * 15)
if not os.path.exists("prices_df.csv"):
prices_df: pd.DataFrame = yf.download(
tickers_T,
start=start_date,
interval="1d",
progress=True)
prices_df.to_csv("prices_df.csv")
else:
# 2回目以降はダウンロード済みのファイルを再利用
prices_df = pd.read_csv(
"prices_df.csv",
index_col=0,
header=[0, 1],
skipinitialspace=True)
prices_df.index = pd.to_datetime(prices_df.index)上記のコードでは、yf.download()の前後で以下を行っています。
yfinanceでは、例えば 6753 の株価をDLするためには末尾に".T"を付けた"6753.T"を指定する必要がある
何度も実行する場合に毎回ダウンロードされると面倒なので、"prices_df.csv"でローカルに保存しておく
ダウンロードされた株価データの確認
ここでダウンロードされた株価データを確認します。

通常のDataFrameとは少し異なり、columns(列)がMultiIndexになっていることに注意が必要です。第一要素が四本値 + 調整終値 + 出来高、第二要素が銘柄コードです。



目的変数の追加
続いて、モデルに予測させたい値である目的変数を、prices_dfの列として追加します。
ここから先は
¥ 2,000
この記事が気に入ったらサポートをしてみませんか?