
日刊 画像生成AI (2022年9月18日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
昨日までの投稿はこちら
開発
Satble Diffusion for Figma「Ando」が次はtextual inversionを実装するようです。
以前かなり話題になったFigmaプラグイン「Ando」は2週間前から公開されていたのですがそれが今度はTextual Inversionで作られたスタイルを選ぶことができるようになるみたいです。
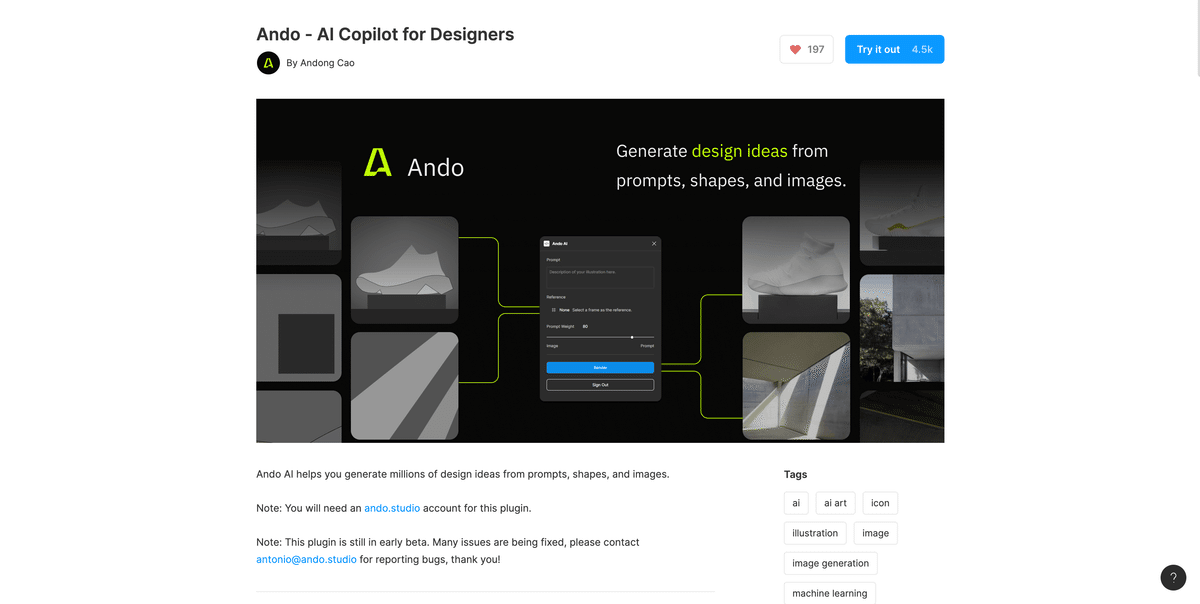
Shipped this AI design tool on Figma two weeks ago, and here’s a sneak peak of what’s coming next: fine-tuned models with consistent styles. #stablediffusion #aiart #figma pic.twitter.com/TEPfolVizk
— Antonio Cao (@RemitNotPaucity) September 18, 2022
現状のプラグイン自体もまだ試している方は少ない様子、試してみました。
まだ使用者が少ないからか分かりませんが、割と高速です。アップスケール機能もあって便利。

BlenderでStable Diffusionが使えるアドオン「dream-textures」がv0.4.0にアップデート
以下ツイートのリプ欄に日本語で分かりやすくインストールの仕方、使い方をまとめているのでよかったらチェックしてみてください。
🚀Blenderで #stablediffusion が使えるアドオン「dream-textures」がv0.4.0にアップデート
— やまかず (@Yamkaz) September 18, 2022
・img2img
・タイル化
・inpainting
・過去の生成物の履歴
・NVIDIA & Apple Silicon GPU のサポート
・Shader Editor, Image Editor対応
・無料
(インストール方法はリプ欄に)
pic.twitter.com/gtriocGQlc
Waifu Diffusion v1.3がもうすぐ公開。
今話題のWaifu Diffusionが9/26に1.3が公開されるそうです。また、Danbooru画像をラベル付けしたオープンソースのデータセットを公開するプロジェクトにも取り組んでいます。

前は56kの画像を学習されていましたが、今回は300k枚以上の高解像度danbooru画像からなる、より多様なデータセットで作られるとのことです。
以下の改良が施されているとのことです。
・モデルのプロンプトの出し方の柔軟性が向上
・より多様な出力。
・高解像度画像の顔や細かいディテールをより良く捉えるために、Danbooru Imagesで微調整されたVAE
現時点の能力でも、かなり高い性能を叩き出しているので1.3vは楽しみですね。
Stable Diffusion for PhotoshopにInpaintingが実装される予定。
Inpaintingとは、塗りつぶしたらそこを指定通りに置き換えられる機能。その機能がもうすぐ追加されるそうです。どんどん進化してきていますね。
Masking is coming to the @StableDiffusion #Photoshop plugin. pic.twitter.com/OSfQBN1ATt
— Christian Cantrell (@cantrell) September 17, 2022
ダウンロードはこちらから
Stable Diffusion in Tensorflow / Keras
この方のテストでは、8GB M1 MacBook Air での元の Torch 実装と比較して、約 4 倍速く実行されます。Divam Guptaさんはあらゆるプラットフォームで高速化を考えられているそうです。
Stable Diffusion implemented using @Tensorflow and #Keras.
— Divam Gupta (@divamgupta) September 17, 2022
- Converted pre-trained models
- Easy to understand code
- Minimal code footprint
Code : https://t.co/oPFfTcn7zz
Google Colab with @Gradio demo : https://t.co/41UCRNZbpg pic.twitter.com/3b0SLcxEyk
2つのモデルを混ぜれるbatファイルが公開。
Waifu Diffusionや、Stable Diffsuion本体のckptモデルを、好きな比率で混ぜれるbatファイルが公開。
Txt2mask公開
マスクを手書きで書いて修正すること(inpainting)は必要もなくなるのかもしれません。Txt2maskは、AUTOMATIC1111さんのStable Diffusion Web UIのアドオンであり、言葉だけで画像のマスクを自動的に作成するもの。素晴らしすぎる。

Stable Diffusion for GIMP アップデート
生成画像のSeedが追加レイヤーに表示されるとのことです。
#gimp #stablediffusion plugin has been updated!
— BlueTurtleAI (@BlueTurtleAI) September 16, 2022
The seed of the generated image is now displayed in an additional layer. Same or slightly modified images can now be generated by using seed.@GIMP_Official @StableDiffusion #ai #aiart #aiartcommunityhttps://t.co/69Vt4UX3MM
Unstable Diffusion今後公開予定
載せるか迷いましたが、日刊なので一応記載。アダルト画像方向に微調整されたモデル + そのサイトが公開されるようです。

詳細を見たい方はこちら
研究
Stable Diffusionを「いらすとや」で追加学習する。


DeepFake的な活用方法

inpaintingで詳細を綺麗に描く方法
Stable Diffusionで生成したらそのままではやはりあまり上手くいかず、どうしても顔や詳細が崩れていることが多い。その場合どうすればいいのかというのがRedditにまとまっていました。
(以下はWebUI (by AUTOMATIC1111)における話です。)
答えはInpaintingとのこと。部分ごと(例えば人ごと)にマスクをして、「バーカウンターに座ってる女性」などのプロンプトを入れていく。(strength:0.5)そしたら綺麗になるよとのこと。最後に「フル解像度で修復」するように
もう慣れている方からしたら当たり前の情報な気がしていますが、一応メモです。




写真から抽象芸術を生み出す。


DockerでStable Diffusion (WebUI) を動かす方法
Concepts Libraryへの登録の仕方
TrintArt上級者続々
エボシさんの投稿がかなり伸びていたのでメモ。ちょっとえっちなので載せるか迷いましたがこのレベルでいけてしまうのは結構衝撃ですね..。
昨晩の。ちょっとやばいな。昼間に貼っていいものなのか、これ🤔#trinart #stablediffusion pic.twitter.com/FuZ7wwOdmo
— エボシ@デネブラボ (@FakeKamaboco) September 18, 2022
まずいなあ、じつにまずい。もっとださなきゃ pic.twitter.com/J0Hka6UlKl
— エボシ@デネブラボ (@FakeKamaboco) September 18, 2022
表現
Scott Lighthiserさん新作
以前Ebsynthを使用した動画で話題になったScott Lighthiserさん。新しい作品制作に挑戦されていたのでメモ。もうVFXですね。
.@StableDiffusion Img2Img x #ebsynth Creature Test#stablediffusion #AIart pic.twitter.com/eh2h8chiUY
— Scott Lighthiser (@LighthiserScott) September 18, 2022
WeavingWithAIさんの作品
experimenting with 3D movements ... #stablediffusion #DeforumDiffusion pic.twitter.com/3vdnTvZSus
— WeavingWithAI (@GanWeaving) September 17, 2022
思想
(以下二点数日前に拾えていなかったものです)
Stable Diffusionとそれに纏わる問題について
OpenAI のCEO Sam Altman が語る AI の新境地
生成された建築の画像をもとに3Dモデラーに依頼している事例
生成された画像で、3Dモデラーさんに依頼されているようです。上手くいけばウォークスルーまでできるかもとのこと。
I asked some 3d architecture modelers to make a 3d model and render of the houses generated by https://t.co/lcPGMcrXfY, it might take a week or so but by next week hopefully we'll have a model we can walk through! Next after that would be full AutoCAD blueprint! pic.twitter.com/fLhsn1eGhh
— @levelsio (@levelsio) September 8, 2022
生成できるサイトはここ。
『メタバースではなく、マルチバース』
プロンプトは潜在的な多次元空間における探索要求であって、生成画像は、別の現実を「リモートで見ている」という考え方。この考え方好きなんですよね..。画像生成AIによって、LatentSpaceによって、あらゆる可能性への扉が生まれたという。アン サンミンさんも似ている素敵なことを書かれていたのでメモ。
GPT-3のような巨大言語モデルには無数のドアがある。まるで、モンスターズ・インクに出てくる魔法のドアのように🚪。"Prompt Engineering" はそのドアを開ける鍵🔑。開けるまで時間がかかるけど一旦開ければドアの向こうには想像もできてなかった世界が待ってる。英検の事例も無数のドアの中の一つ。 https://t.co/Y8vVx4hEFg pic.twitter.com/9EyYkye7PH
— sangmin.eth @ChoimiraiSchool (@gijigae) September 18, 2022
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。よかったらフォローしてくれるとうれしいです。
実験、最新情報まとめはこちら
https://twitter.com/i/events/1560957489730179077
前回の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます