
日刊 画像生成AI (2022年9月13日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
(暦本さんが発見してくれたみたいで、嬉しいです。)
数ヶ月前に冗談混じりで言ったら完全に現実化している😅 https://t.co/rilN7UCl4x
— Jun Rekimoto : 暦本純一 (@rkmt) September 13, 2022
昨日までの投稿はこちら
開発
Stable Diffusion for Photoshop、なにやらimg2imgを追加するらしいが..
一昨日公開されたDreamStudioAPIを利用したStable Diffusionが使えるPhotoshopプラグイン。開発者の方が今週この機能を実装されるとのこと。よく見ると「use document image」との記載が。レイヤーをimg2imgでそのまま生成できれば大幅な作業短縮になりますし、かなり使いやすくなりますね。

Look what's coming to the @StableDiffusion #Photoshop plugin this week. pic.twitter.com/NfU7Dj1AlK
— Christian Cantrell (@cantrell) September 12, 2022
Prompt Parrrot v2.4公開
Prompt Parrotとは自分のプロンプトのリストを入力し、言語モデルを学習し(gpt2を利用)、自分のスタイルのプロンプトが生成できちゃうというもの。v2.4ではサンプラーの選択ができるようになったそうです。
Releasing Prompt Parrot v2.4 🦜
— Stephen Young (@KyrickYoung) September 13, 2022
- now with sampler selection!#stablediffusion #imgsynth #promptparrot #aiart https://t.co/p9OYSMfY7w pic.twitter.com/SJgf3u9aaP
colabはこちら
Prompt2colorpallette
Matt DesLauriersさんが任意のテキストからオリジナルカラーパレットを生成するツールを開発しました。仕組みとしては、gifencという名の JavaScript GIF エンコーダーが、生成画像を分析し、色を特定のセットに量子化。そこでパレット情報を抽出するのだそうです
ローカルでStable Diffusionを利用できる環境+Node.jsが利用できれば使えるとのことです。

Just published the code for my NodeJS palette generator tool with Stable Diffusion:
— Matt DesLauriers (@mattdesl) September 13, 2022
→ https://t.co/QvFIj3Wstt
Below: comparing different color quantization modules for palette extraction. pic.twitter.com/yXj8KxWkCY

AI tool to generate colour palettes from any text prompt —#stablediffusion #ArtificialIntelligence pic.twitter.com/pPTk9bqejx
— Matt DesLauriers (@mattdesl) September 12, 2022
CEB Stable Diffusion 0.40 Betaに
Blenderで使えるStable Diffusionアドオン CEB Stable Diffusionが0.40Betaに。おそらくアップスケールできるようになったっぽい。8192x8192までアップスケールとのこと。
Ceb Stable Diffusion 0.40 Beta WIP (to be honest just need to test on Blender 3.3 before launching pic.twitter.com/9qFDAbz3eT
— Carlos Barreto (@carlosedubarret) September 12, 2022

ダウンロードはこちら。
Deep Danbooru
これはかなり前から存在しているものなようですが、今Waifu Diffusion、Trinartが流行っているのでメモ。画像からDanbooruタグを推定してくれるようです。これで思い通りの二次イラストにできるかも。
お持ちのイメージ画像をDeep Danbooruに入れてみてhttps://t.co/fpE88DWkZy
— forasteran (@forasteran) September 13, 2022
画像からDanbooruタグを推定
Danbooruならこんなタグって確信度みたいな数値とタグ一覧を出してくれる!
CLIP interrogator的な#WaifuDiffusion 用に、この画像ならどんなタグ使えばいいの?って時に呪文に使えて重宝する pic.twitter.com/jYDcNofDWz

ソースも紹介してくださっていましたのでメモ。
表現
オリジナルヒューマン生成
CoffeeVectorsさんの制作物に注目が集まっていました。ワークフローはツイートのリプライに記載されてますが、以下に簡易的に解説してます。
Took a face made in #stablediffusion driven by a video of a #metahuman in #UnrealEngine5 and animated it using Thin-Plate Spline Motion Model & GFPGAN for face fix/upscale. Breakdown follows:1/9 #aiart #ai #aiArtist #MachineLearning #deeplearning #aiartcommunity #aivideo #aifilm pic.twitter.com/hzUtJvB8IK
— CoffeeVectors (@CoffeeVectors) September 12, 2022
まず、Daz 3d(3D人物が得意な簡易モデリングソフト)Daz Studio(3D アート作成ソフトウェア。(ご指摘があり、修正。))でモデルを生成。Unreal Engineのmeshtometahumanアドオン(モデルとか素材があれば簡単にメタヒューマンが作れるツール)でメタヒューマン化
First, here's the original video in #UE5. The base model was actually from @daz3d #daz and I used Unreal's #meshtometahuman tool to make a #metahuman version. 2/9 #aiartprocess pic.twitter.com/seCLzBjVQP
— CoffeeVectors (@CoffeeVectors) September 12, 2022
その動画から1フレーム画像として抜き出し、Stable Diffusionのimg2imgでイラスト生成。
Then I took a single still frame from that video and ran it through #img2img in a local instance of #stablediffusion WebUI. After generating a few options I ended up with this image. 3/9 #aiartprocess pic.twitter.com/l4gsrb5JJ7
— CoffeeVectors (@CoffeeVectors) September 12, 2022
それをThin-Plate Spline Motion Modelを用いて生成した画像をアニメーション化。Thin-Plate Spline Motion Modelとは動画と画像があれば、その画像をそれと近いように動かせるというもの。転送画像と動画にギャップがあるとうまくいきません。(ebysynthとやれることは同じですね、というかあの中身がこれなのか)

Then I used the Thin-Plate Spline Motion Model to animate the img2img result from #stablediffusion with the driving video from #UnrealEngine5. 4/9 #aiartprocesshttps://t.co/XLfJyp9n68
— CoffeeVectors (@CoffeeVectors) September 12, 2022
そしたらこの動画ができちゃうとのこと。
The result is 256 x 256. 5/9 #aiartprocess pic.twitter.com/oA9VuFd3S3
— CoffeeVectors (@CoffeeVectors) September 12, 2022
できたらTopazVideoEnhance(動画のアップスケーラー)で拡大。
なお、目などがこのプロセスでアーティファクト(歪み)が発生するとのことなので利用するビデオシーケンスは全て画像にしてGFPGANを通すとのこと。すると目の品質は向上するそうです。GFPGANは顔を復元するためのアルゴリズム。
GFPGAN changed the alignment of some things slightly for some reason and shifted the color. It also faded the birthmark a bit. Not sure how to control the strength of the effect locally just yet. GFPGAN link below. 8/9 #aiartprocesshttps://t.co/iSxl1QGGiY
— CoffeeVectors (@CoffeeVectors) September 12, 2022
自動生成した歌詞からAI動画生成
最近すきえんてぃあさんがDeforumDiffusionでかなり制作されているので気になっていました。こちらはおそらく生成した歌詞をカットして、その歌詞のpromptがいくつもキーフレームになっているという感じだと思います。
#DeforumDiffusion #deforum #stablediffusion
— すきえんてぃあ@書け (@cicada3301_kig) September 12, 2022
AIが歌詞から自動生成
Mili - Paper Bouquethttps://t.co/M4lw0S7kMM
アニメ「処刑少女の生きる道」 OPhttps://t.co/Siy5x2s8u3 pic.twitter.com/wSEVJkB7hn
僕も最近実験しています。
Buildings Audio Visualizer #stablediffusion pic.twitter.com/xkQkcHJras
— やまかず (@Yamkaz) September 14, 2022
Midjourneyで生成したものを3Dに
midjourneyで作った絵を3Dにしてみた。
— 常橋岳志 (@tunetake) September 12, 2022
ん〜〜〜midjourneyすごいなーーー。やば〜〜。#midjourney #3D #Animation #cinema4d pic.twitter.com/NwnDIZu7dW
生成画像のバリエーションを用いることで動画を生成。
試験的に作った、Midjourneyでアニメーション・エフェクトを作るチュートリアル動画です。大したことはしていませんが、慣れれば5分もかからないのでオススメです。
— 庭月野議啓 NIWATSUKINO Norihiro (@Dir_NIWATCH) September 13, 2022
My first tutorial video how to create animation effects with Midjourney.
[YouTube] https://t.co/TuIEbY7yLr pic.twitter.com/zOmfGnX722
研究
SD + IMG2IMG + After Effectsのワークフロー
最近このようなワークフローの映像がアップされてきていますが、こういうのを見てると本当に従来のレタッチ、デザイン、イラスト作業を抜本的に変えていくことが目に見えて分かります。


高解像度イラスト生成のワークフロー(Grid Upscalerを使用)
グリッド分割して、それぞれでまたimg2imgでディテールを描写して、それをまたphotoshopで修正して..というプロセスを経て、違和感のない美しいイラストを生成されています。
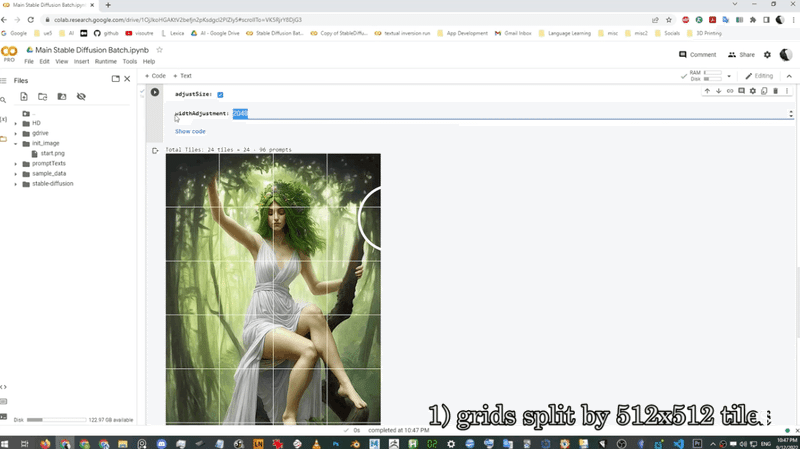

こちらのcolabでgrid upscaleができるそうです。
512x512 の 24 倍のピクセル「3072x2048」での適切な生成方法

Soft Diffusionの発表

Announcing Soft Diffusion: A framework to correctly schedule, learn and sample from general diffusion processes.
— Giannis Daras (@giannis_daras) September 13, 2022
State-of-the-art results on CelebA, outperforms DDPMs and vanilla score-based models.
A 🧵to learn about Soft Score Matching, Momentum Sampling and the role of noise pic.twitter.com/vSDRM5CmDY
( ) は囲まれた単語への注意を高め、[ ] はそれを減らします。
これはStable Diffusion Web UI(by automatic1111)のみに入っている機能だそうです。ただこのフォークが多いため、色んなところでこの方法は使えるとのことです。

モデルのハイブリット
trinart_v2 と waifu-diffusion+stable-diffusionハイブリットができるみたいです。(forasteranさんの投稿で知りました。)
Some AI bangers. Prompts are all minor variations of the alt. text of the first image, no img2img was used.
— OrangeW (@OrangeW_) September 13, 2022
Model used is a 50/50 hybrid between trinart_v2 and another hybrid of waifu-diffusion+stable-diffusion. pic.twitter.com/PazRsMHNJq
Stable Diffusion Concept Libaryを試す
いつも新しいのが出たらすぐ試して、すぐnoteを書いてくださってる布留川さん(npakaさん)。いつも感謝しています。最近でたConcepts Libraryを試されているのでぜひ。
拡散モデルのサーベイ
拡散モデルサーベイhttps://t.co/b2g4jk2FmY pic.twitter.com/JJFeX2zTI1
— phalanx (@ZFPhalanx) September 13, 2022
思想・ムーブメント
「REALMS」が販売されています。
先週Midjourneyで制作されたコミックがAmazonランキングに入ったとニュースがありましたが、昨日も1冊の投稿が伸びていたので紹介。
キャラクターの類似性は「--chaos 0 --sameseed 12345」を使うことで乗り切ったそう。ちなみに「chaos」は結果がどれくらい一貫性が失われるか、「sameseed」はmidjourney特有の最初の生成画像4候補に同じseed値が適用されるというもの。なるほど..確かにそうすれば今でも一貫性が作れるのか。漫画自体はmidjourneyで生成した画像を、PhotoshopとComic Life 3で改造されたそうです。


こちらで購入できます。日本だとTwitterで投稿してる人しか確認していないのでやれば注目は集まるかもしれませんね。
StableDiffusionが使えるアプリ「AIピカソ」開発者、冨平準喜さんインタビュー
StableDiffusion公開から爆速でリリースされたAIピカソ。その開発者の方のインタビューがDIAMOND SIGNALさんからまた投稿されていました。このシリーズは続きそう。
将来AI生成画像が学習データに含まれ、ノイズになるのでは?
深津さんもこのようなお話をされてましたね。
過去の質問でStabilty.aiのCEOのEmadさんは問題ないとお話しされているようでした。
Emadさん
いいえ、データやあらゆる種類のものを重複排除できますが、心配する必要はありません。
最後に
日刊を公開し始めていつの間にか13日経ちました。気づけばずっと見てくれていつもいいねしてくれたり、コメントくれたりしてくれる人も増えてきました。励みになっています。ありがとうございます。
Twitterに、毎日製作したものや、最新情報、検証を載せています。よかったらフォローしていただけますと幸いです。
前回の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます