日刊 画像生成AI (2022年9月15日)

画像生成AI界は、今認識できないスピードで進化をし続けています。
DALL・E2公開、Midjourney公開、StableDiffusionがオープンソースで公開されて..進化の速度が上がり続けており、日々異常なスピードで変化しています。

そんな中、毎日時間なくて全然情報追えない..!って人のために業界変化、新表現、思考、問題、技術を毎日あらゆるメディアを調べ、まとめています。
昨日までの投稿はこちら
開発
AdeptがACT-1(アクショントランスフォーマー)を発表
画像生成AIに注目している方々は関係ないとは言い切れない、重要すぎるトピックなので最初に紹介。ACT-1は、一連のソフトウェアツールを使えるように教えられた最初の大型モデルです。例えば、「4人で住める家をヒューストンで探して」と話せば、その通り調べて、探してくれます。SiriとかGoogle Home、Alexaがこれまでできなかったことが全部できちゃいそう。
以下のツイートの動画を見てもらえるとヤバさが分かります。個人的には、数日前のRunwayMLのテキストでの動画編集の衝撃以上….。いややばい。やばい。雑用全部本当に楽になりすぎるのでは。楽というかなくなるのかな。
1/7 We built a new model! It’s called Action Transformer (ACT-1) and we taught it to use a bunch of software tools. In this first video, the user simply types a high-level request and ACT-1 does the rest. Read on to see more examples ⬇️ pic.twitter.com/mq7c0Vyd7N
— Adept (@AdeptAILabs) September 14, 2022
この公式サイトに載っている動画を全部見てください。やばいです。
トピックとして、個人的にやばかった部分を翻訳+抜粋。
数年後、私たちは次のように考えています。
コンピュータとのやり取りのほとんどは、GUI ではなく自然言語を使用して行われます。私たちはコンピュータに何をすべきかを伝え、コンピュータはそれを実行します。今日のユーザー インターフェイスは、スマートフォン ユーザーにとって固定電話と同じくらい時代遅れに見えるでしょう。
「Salesforce、Unity、または Figma で X を実行する方法」についてフォーラムを検索することは決してありません。モデルがその作業を行うため、当面の高次のタスクに集中することができます。
そういう時代では何が重要なのか。この事例でいよいよ考え始める人が今まで以上に、圧倒的に増えそう。
ちなみにAdeptとはAIのリーダーからなる9人のチーム。Transformerの発明者、Ashish VaswaniさんとNiki Parmarさん。GPU コンピューティングのパイオニア、DeepMind共同主導者のErich Elsenさん。Google のコード生成モデルの構築者、Augustus OdenaさんとMax Nyeさん。Google の製品用音声認識モデルを構築したAnmol Gulatiさん。Google のデータおよび協調型 AI システムに関するグループのエキスパートFred Bertschさん。OpenAIのエンジニアリング担当副社長、GPT-2、GPT-3、CLIP、DALL-Eなどを送り出したDavid Luanさんなど.. いや経歴やばいし、写真かっこいい笑

今後の展開に要注目です。
Stable DiffusionのPhotoshopプラグインがバージョンアップ。img2imgが利用可能に。
Christian Cantrellさんが以前公開したDreamStudio APIを利用したプラグイン。レイヤーをそのまま元画像として設定して、img2imgできるそう。かなり画像生成AIを使ったいいワークフローを誰もができるようになりそう。
今後の展開としてローカルでも動くようにするとのこと。期待ですね。
The new version of the @StableDiffusion plugin for #Photoshop brings img2img to your creative workflow. Download it for free here:https://t.co/gqFWpABQLY pic.twitter.com/QXZq4IroDU
— Christian Cantrell (@cantrell) September 14, 2022
neural.love Free AI art generator公開。
EUの小さなスタートアップのサービス neural.loveにFree AI art generator betaが追加。Redditで注目が集まっていたのでシェア。かなり良さそうだが、コメント欄を見る限り、DreamStudioより遅い上クオリティが低い..?とのことでした。
neural.loveの他Stable Diffusion実装サービスとの違い
・基本画像生成は無料
・組み込みのプロンプト ジェネレーター(何も工夫しなくてもpromptを補完して、質もいいものを作ってくれる)
・カテゴリ変更
・interrogator組み込み(画像からpromptを生成)
・特注img2img(顔のクオリティが高いそう)

Phase.artにStableDiffsuion追加
Phase.artは、prompt支援ツールだったのですがそこにStable Diffusionの生成機能まで追加されました。どうなんだろう、便利なのかな

stablediffusion-infinity (outpainting canvas)
DALL・E2のOutpainting機能っぽく、Stable DiffusionでもOutpaintingできるように実装された方がいるようです。
Introducing stablediffusion-infinity: #outpainting with #stablediffusion on an infinite canvas.
— Lnyan (@lkwq007) September 14, 2022
Implemented with @huggingface's #diffusers and @martinRenou 's #ipycanvas in a Jupyter notebook.
Check the code here: https://t.co/BpUWQZuCqF
Also available in colab. pic.twitter.com/kQpoBT8hcY
Have I Been Trained?
StableDiffusionには58億枚超えの画像のデータセット LAION 5Bがつかわているのですがその画像を検索できるサイトができたようです。ClipFrontとは違って、画像を検索できるのがポイントですね
GIGAZINEさんがもう紹介されていたので、詳しくはこちらにどうぞ
Optimized Stable Diffusionがv1.0.4に更新。さらに超高速に。
Optimized Stable Diffusionは推論速度を犠牲にすることで元のリポジトリよりも少ないVRAMを使用するように最適化されたものです。そこにサンプラー、neonsecret のメモリ最適化、ふわふわしたボタン(おそらくUIデザインのこと..?)が追加されたそうです。
Introducing new optimized UI (with samplers, neonsecret's memory optimizations, and fluffy buttons)#StableDiffusion #AIArt #AIArtwork #DreamStudio pic.twitter.com/9O6d52URda
— Stable Diffusion 🎨 Pics & DreamStudio (@DiffusionPics) September 15, 2022
Stable Diffusion WebUI (Docker)
Stable Diffusionをかなり高度に使いやすく、機能も豊富なWebUIをDockerで利用できるようにしたものが公開されたようです。Macでは動作しないとのこと。Nvidia カードがインストールされているもので実行する必要があります。

polycam、 Room Modeを発表
これも画像生成AIにガッツリ関係してる訳ではないですが、Stable Diffusionで作る作品に利用できるかもと思い、一応載せておきます。空間を即座にキャプチャすることができるサービスです。ドア、壁、窓、家具を備えた間取り図をリアルタイムで生成してくれるとのこと。
表現
Midjourneyで制作した映像作品で、国際的な賞を多数受賞
こちらの映像、幾つも国際的な賞を受賞してるらしい。海外は早いですね。
ちなみに技術としては、D-IDというのを利用されている様子。声を入力したり、テキストを入力すると、入れた画像の中の人物が喋ってくれるというもの。検証してる日本ユーザーの人の投稿見る限り、日本語はあまりなのかなという感触。
A Message from a creation made by Midjourney and D-ID.#midjourney #Midjourneyai #AIart #Digitalart #animated pic.twitter.com/NJWSX8eu53
— Orcton (@OrctonAI) September 14, 2022

Paul Trilloさん新作が話題
以前この映像で話題になった監督のPaul Trilloさん。DALL・EのOutpaintingを使って新作を作られていました。
Using @OpenAI dall-e 2 AI to dream up what a Chinese restaurant skyscraper might look like. The fluid frame interpolation was made with @runwayapp new super slow motion setting that also uses the power of AI to morph between frames. #aiart #ai #architecture #vfx #dalle pic.twitter.com/HMUvUyqsxA
— Paul Trillo (@paultrillo) September 15, 2022
Stable Diffusionのアニメーション作品セレクト
昨日はこちらが良かった。と思ったら14日のでした。拾えてなかった。
引いていく映像はあまりないのでよく見えるんですよね。
もうすぐこういうMVが増えそうですね。
Whom are you looking at? #aiart #characterart #conceptart #modernart #characterdesign #midjourney #discodiffusion #dalle2 #stablediffusion #nft #portraitart #surrealart pic.twitter.com/ENXfA4otza
— kyii (@kyii49793141) September 14, 2022
研究
PaLI:Pathways Language and Image model
グーグルAI研究(PaLI:Pathways Language and Image model)
— 小猫遊りょう(たかにゃし・りょう) (@jaguring1) September 15, 2022
テキスト+画像からテキストを出力するAI。複数タスクで最高性能。データセット「WebLI」を構築(画像+テキスト100億組。100言語以上)。言語モデル「mT5-XXL(130億パラ)」と視覚モデル「ViT-e(40億パラ)」利用https://t.co/aHZkg96v8W pic.twitter.com/62rYcEdn84
どうやら見る限り、画像入れて英語で説明してって話したら説明してくれるAIって感じですね。Prompt逆引きのものはいっぱい出てはいますが、最高性能というのは気になりますね。

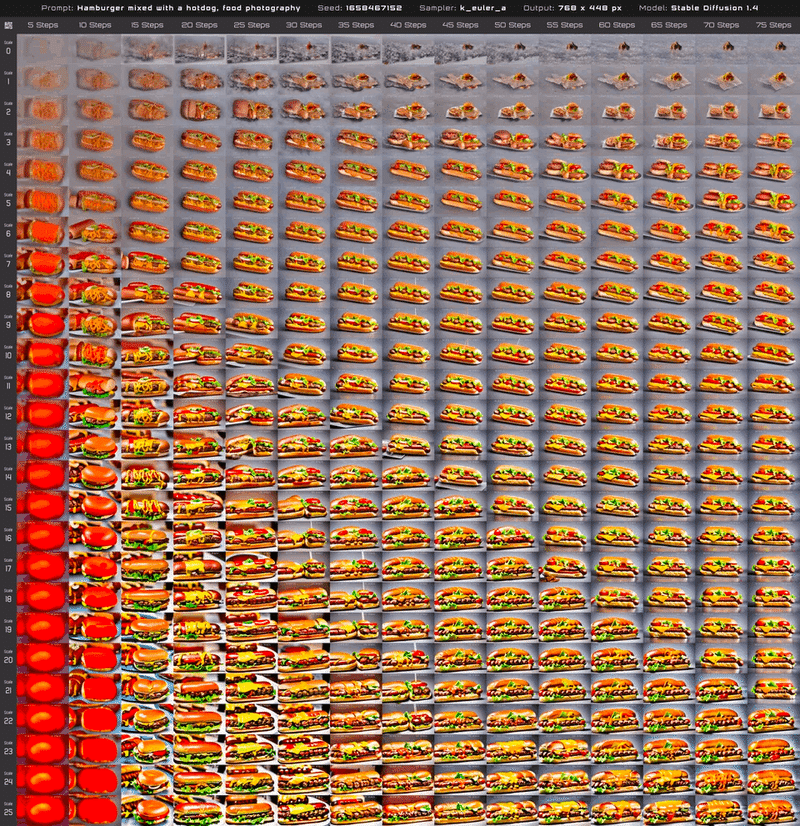
Steps と Guidance Scale 値の比較
思想・ムーブメント
852話さんインタビュー公開。
可愛い女の子のイラストや、Midjourney検証で話題になった852話さんがインタビューしてもらってました。
週刊アスキー様にインタビューしていただきました。https://t.co/zUyv6rlM07 @weeklyasciiより
— 852話 (@8co28) September 15, 2022
最後に
毎日日刊画像生成AIを続けてきましたが、そろそろこれをリリースします。
「日刊 画像生成AI」を毎日書いていて思ったのが、これ使いたいな..見たいな..って思った時にすぐに取り出せない事。今全情報を整理して1つにまとめています。もうすぐ公開します。待っていてください。
— やまかず (@Yamkaz) September 16, 2022
Twitterで待っててください。
割とサービスや生成された面白活用みたいなものは一旦落ち着いてきているので..(いっぱい投稿はされてるけど、これといって過去に紹介したものと違いはないから紹介してないです)こういうまとめを作る作業に移るのでもいいかもと思ってます。と思ってたら次の日結構出たりするので分からないですが..。
前回の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます