
日刊 画像生成AI (2022年11月17-18日)

ジェネレーティブAI界は、今とても早いスピードで進化し続けています。
そんな中、毎日時間なくて全然情報追えない..!って人のためにこのブログでは主に画像生成AIを中心として、業界変化、新表現、思考、問題、技術や、ジェネレーティブAI周りのニュースなど毎日あらゆるメディアを調べ、まとめています。

📣お知らせ
ジェネレーティブAIで取り組みたい事業があり現在進めていますが、Webアプリケーション開発ができ今後一緒に取り組める方を探しています。
もし興味がありましたら、TwitterでDMをいただけますと幸いです🙇
過去の投稿はこちら
開発
InstructPix2Pix
人間の指示から画像編集 「ひまわりとバラを交換」「空に花火を追加」「雪が降っていたら?」などを入力すると数秒で画像編集してくれる「InstructPix2Pix」が発表されました。
2つの大規模な事前学習済みモデル、GPT-3、Stable Diffusionを組み合わせて、大規模な画像編集例データセットを生成。生成されたデータを用いて学習した条件付き拡散モデルが「InstructPix2Pix」。このモデルはフォワードパスで編集を行い、fine tuningやinversionを必要としないため、数秒のうちに高速に画像を編集することができるとのこと

Direct Inversion
拡散モデルを用いた最適化不要のテキスト駆動型実画像編集方法。
Direct Inversion: Optimization-Free Text-Driven Real Image Editing with Diffusion Models
— AK (@_akhaliq) November 16, 2022
abs: https://t.co/qTxdwyKa78 pic.twitter.com/BVaLMdsh7r
使いやすいローカルインストールのSD実装「ArtRoom」が公開
これまで出てきたSD実装のなかでもぱっと見シンプルでかっこいい。NVIDIA GPU のみをサポートし、8GB VRAM(最小 4GB)を推奨とのこと。

ここからダウンロードできます。
Discordサーバーもありました。
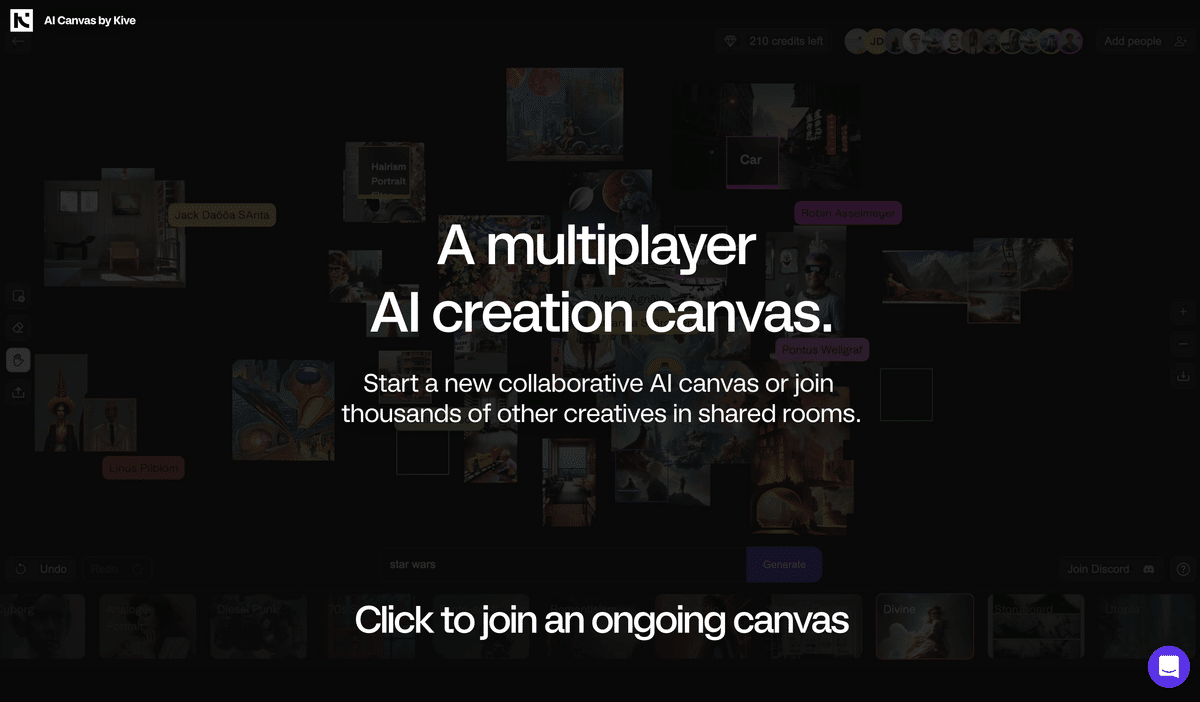
Kive AI Canvas
みんなで巨大なキャンバスに画像生成をしていくサービスKive AI Canvasが公開。マルチプレイSDサービスとしては3つ目の発見だけど、一番サービスとしてちゃんとしてる。
AI作品の投稿サイト「AIPIC」
AI画像投稿サイト、AIPICが公開。開発者の方は中学生のFくんという方。
(こちら、15日に追えていなかったもの)
【新・AIイラスト投稿サイト🎈】
— 【公式】AI絵作り研究会 (ここはちの妹) (@AiArt_Official) November 15, 2022
🌟#AI絵作り研究会 発、AIイラスト専用投稿サイト「AIPIC」リリース🎉
🔽是非下記リンクからご利用ください❣️
👉 https://t.co/k2bidXz7Dx
😲このサイトはなんと中学生の @fkunn1326 によって開発されています(@_@)✨
機能など詳しくは⏬
(1/4)
Null-text Inversion
ガイド付き拡散モデル(Stable Diffusion)を用いた実画像編集のためのNull-text Inversionが発表。


Null-text Inversion for Editing Real Images using Guided Diffusion Models
— AK (@_akhaliq) November 18, 2022
abs: https://t.co/otMgDpw5WA
project page: https://t.co/Lrwfa1XLyu pic.twitter.com/CHRq1qRxjn
物体検出のための拡散モデル「DiffusionDet」
DiffusionDet: Diffusion Model for Object Detection
— AK (@_akhaliq) November 18, 2022
abs: https://t.co/GBu4bZPwKp
github: https://t.co/bWHxGxayjB pic.twitter.com/7a8lfNaqp9
手を綺麗に描く新しい方法
逆に変形した手を学習させて、ネガティブプロンプトに使ったら手がちゃんとかけるという事例。なるほど..、人間のクリエイターさんと同じでダメな例を学習させればちゃんと良くなるの面白い。
#StableDiffusion のTextual Inversion追加学習で敢えて変形した画像を学習させ、学習結果を「ネガティブプロンプトに」使うという試み。手が!手がちゃんと出てる!! https://t.co/y5hzqSbye2 pic.twitter.com/kUkmKuQzgY
— Kenji Iguchi 💉⁴ (@needle) November 18, 2022
EimisAnimeDiffusion 1.0vが公開
高画質で詳細なアニメ画像を用いて学習したモデルが公開。アニメと風景画像で本領を発揮するとのこと。

高杉さんのメモ。これ見るとAnything-V3.0のfine-tuningモデルかな..?ってことはNovelAIリークモデルを利用しているから使えない、?
EimisAnimeDiffusionこれHypernetworkの掛かり方を見るにAnything-V3.0同様NovelAI系列であることは間違いないんだけど
— 高杉 光一🦋 (@kuronagirai) November 20, 2022
頭のちょん切れ具合からするとWaifu 1.3のソレなんだよな…
マージしたのか新たに追加で学習させたのか…
ディテールの上昇具合を見るにより高解像度の画像を雑にトリミングした? pic.twitter.com/SCfTYbFy7r
Fantastic Mr Fox Diffusionが公開
プロンプトに「fantasticmrfox」を使うことで利用することができます。狐以外に適用したい場合はネガティブプロンプトにfoxを入れるといいとのこと。

Pixel Art Diffusion by KaliYuga
Stability AIに現在は所属しているKali YugaさんがついにPixel Art Diffusion公開..かも。DALL-E2からMidjourneyまでの間のオープンソース界隈からいらっしゃて、オリジナルモデルを複数作られて、過去にDisco DiffusionのPixel Art Diffusionを作られていたKali YugaさんがSDで新しいモデルもうすぐ公開されるかもです。 品質がかなり高そうです。
This is WILD. My #stablediffusion model for #pixelart items is only finetuned on weapons but due to the way I structured it (you prompt with "sword: [sword description]", "gun: [gun description]", etc), I just discovered it can do *totally* unrelated categories of thing, too. 🧵
— KaliYuga (@KaliYuga_ai) November 17, 2022
"instrument: guitar", "boots: cyberpunk", "tree: crystal cypress", "pottery: zuni" pic.twitter.com/m7Euaav5Qp
— KaliYuga (@KaliYuga_ai) November 17, 2022
Nitro Diffusion
優れたコントロールと驚異的な汎用性を持ったマルチスタイルモデル、Nitro Diffusionが公開されました。



Painting Generator
ブラッシュストロークに訓練されたモデル、素敵な結果を得るために、任意のアーティスト名やスタイルを置く必要はないとのこと。Loopbackを使ってもいい感じのようです。


Diffusion Land
画像を作成し、MJ、SD、および DALLE2 の高度なプロンプトを作成するためのシンプルなツール「Diffusion Land」が公開。これまで出てきたSD実装サービスの中で一番シンプルかも。CFGとSeedとか色々無くした設計が素晴らしい。

次世代の大規模言語モデルはあなたの心を吹き飛ばし、あなたのビジネスを混乱させます
// Next-gen LLMs //
— AI Pub (@ai__pub) November 17, 2022
Just co-wrote a piece on next-gen LLM capabilities, and implications for startups - with Swift VC, a B2B AI VC firm in the Bay Area.
Next-gen LLMs will be:
- Multi-prompt
- Agentic
- Vastly knowledgeable
More info:https://t.co/P7jr6YznAv
1/7
次世代LLMはこう進化する①マルチプロンプト。AIが筋道立てて順を追って思考できるようになる②エージェント能力。今のLLMは学習した事しか答えられないが、これからはAIが自分でググったりして答えを拾いに行く③エグい知識。今のLLMは何でもかんでもは答えられない。でも新しいLLMならできる →RT
— うみゆき@AI研究 (@umiyuki_ai) November 20, 2022
なるほど..面白い。アイアンマンに出てくるJarvisに向かってゆく。
Optimusみたいなのが世界を歩き回ってる時代になって、それが見た映像も検索して持ってこれるようになったら完全に人間には勝ち目が無くなりそう。
JukeboxWebUI v0.3
画像生成AIじゃないけどメモ。JukeboxのWebUIがアップデート。
Aaand, #JukeboxWebUI v0.3 is out with upsampling!
— Vova “words are a motherfucker” Zakharov (@vovahimself) November 16, 2022
- Mid-quality upsampling takes just 2 hours per minute of composed audio.
- Listen to intermediate audio as upsampling progresses.
- Stop and continue from any point.
Announcing with some (apparently live) crossover thrash 🤘 pic.twitter.com/5jqDwCFUns
NVIDIAがMicrosoftと協力して大規模なクラウドAIコンピューターを構築すると発表
(ポイントまとめ)Microsoft Azureがベース、AIの分散トレーニングと推論用に最適化された仮想マシンが含まれている、NVIDIAとしては初となる「高度なAIスタックを組み込んだパブリッククラウド」、世界で最も強力なAIスーパーコンピューターの1つにすることを目指すとのこと。
NVIDIAは「NVIDIAはコラボレーションの一環として、Microsoft Azureのスケーラブルな仮想マシンインスタンスを利用して、ジェネレーティブAIの進歩を研究し、さらに加速させます。ジェネレーティブAIの分野ではMegatron Turing NLG 530Bのような基本モデルが、新しい文章やコード、デジタル画像、ムービーや音声を作り出す教師なし自己学習アルゴリズムの基礎となります」と述べています。
Playground AIがデータセットを公開
StableDiffusionが利用でき、生成画像もたくさん見れるサイト、Playground AIで、いいねされた画像とプロンプトのデータセットが公開されたようです。

高品質なゲームアセット生成の作成マシンがもうすぐリリース
I have some important news to share!
— Emm (@emmanuel_2m) November 17, 2022
We’re shipping https://t.co/vnGUQ30nd8 in a few weeks (@Scenario_gg).
It's the ultimate creation machine for making high-quality, style-consistent #game assets. pic.twitter.com/xKG3XOaDMi
Revel.xyz
http://Revel.xyzで、AI によって作成された収集品を作成、鋳造、および取引ができるようです。StabilityAIのAPIを利用しているとのこと。
Create, mint, and trade your AI-created collectibles on https://t.co/oX5VjXqgeN, the first social platform to launch generative AI authoring for consumers with @StabilityAI & @EMostaque https://t.co/IduFGmFYPH
— Revel.xyz (@RevelXyz) November 17, 2022
オーディオ・音楽生成の最新動向
近年の画像生成AIの成功を受け、オーディオ・音楽の生成にも拡散モデルの波が押し寄せています。音とテキストの関連をとらえる「CLAP」や、高品質な効果音・音楽を生成するモデルなどが次々と発表されています。
— ステート・オブ・AI ガイド (@stateofai_ja) November 16, 2022
本記事では、オーディオ・音楽生成の最新動向をまとめました https://t.co/8b5A5OxnRG
スタンフォード大学、LLMを理解するための初のAIベンチマーク「HELM」を公開
大事なところだけピックアップ
過去数年間に急加速して発展してきたこれらのモデルを評価するための標準的方法を提供するAIベンチマークはこれまで存在しませんでした。
LLMは特にAIコミュニティを魅了していますが、スタンフォード人間中心AI研究所(HAI)の財団モデル研究センターによると、評価基準がないため、コミュニティがこれらのモデルを理解し、その能力やリスクを把握する能力が損なわれているとのことです。
このため、CRFMは本日、HELM(Holistic Evaluation of Language Models)を発表しました。HELMは、言語モデルおよびより広範な基礎モデルの透明性を向上させることを目的とした最初のベンチマークプロジェクト であるとしています。
このベンチマークが目指していることのひとつは、モデル間の差異を把握することだという。
表現
美しい…. SD風景の生成画像




プロンプトとしては、スタイルとして、"by alexi zaitsev, by Antoine Blanchard, by Brent Heighton, by Jeremy Mann" よりいい絵を出すために、"masterpiece, intricate, 8k", ネガティブプロンプトには、"name, tiled, frame, border, lowres, signs, memes, labels, text, error, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry"を利用しているとのこと。
TikTokでプチ伸びているi2i動画
おそらく3DモデルをnovelAIでi2iしている動画がプチ伸びていました。
めちゃめちゃ魅力的だからもっと見たい..、結構需要ありそう。
The strange case of the "grandmas fever" (12 august 1991)
Redditでこの日トップだった作品。Midjourney v4が生成する映画風の写真生成素晴らしすぎる。こういう作品個人的に好きなのでどんどん溢れ出してほしい。



研究
「前方優位の法則」と「色が混ざる現象」の根拠
AI画像プロンプトの学習者なら体感的に知っている「前方優位の法則」と「色が混ざる現象」の根拠を数値上で確認しました。CLIPというかTransformerの仕様上そんな気はしていたんですが、「各トークンは登場箇所から<以降すべて>に影響を及ぼし、<前方に遡って影響を与えることは無い>」ようです。続く pic.twitter.com/sEJLy2azZT
— でべろぱ (@ai_prompt_dev) November 18, 2022
そしてStabel Diffusionは恐らく77トークンすべてをおよそ平等に扱うか、後方ほど無効な情報(空トークンによるパディング)で埋められがちなのを理解し、軽視するように学習してしまっています。以上が長大なプロンプトにおける後方の記述ほど効きにくくなる根拠です。
— でべろぱ (@ai_prompt_dev) November 18, 2022
色混ざりについても、前方にある記述が薄らとはいえ末尾まで影響を与えるようなので、プロンプトの最初の方に書いた色ほど全体に影響を及ぼすという事でしょうね。複数色を指定する場合は回避が困難ですが、プロンプト末尾近辺に指定した色は比較的前方の物体と混ざりにくいのかもしれません。
— でべろぱ (@ai_prompt_dev) November 18, 2022
Can't Believe There's No Images!言語データのみを用いた視覚的タスクの学習
男性らしさを表す表現と「なぜ絵が女性化してしまうのか?」についての考察、対処法について
BL元素法典がほぼエターなりそうなので、執筆過程で得た結果の考察やらを画像にして投稿していく事にします。
— 電々 (@den2_nova) November 17, 2022
これは、男性らしさを表す表現と「なぜ絵が女性化してしまうのか?」についての考察、対処法について考えてみた内容です。#NovelAI #AIイラスト #NovelAIイケメン部 pic.twitter.com/mtx5zvlCSy
思想・ムーブメント
Animé LA での議論、今後の対応
ロスのアニメコンベンションはめちゃくちゃ厳しい対応をとっています。
ザックリ訳すとロスのアニメコンベンションにて、「AIアートの現状や配慮無きアーティストの方向性を考慮した結果、AI生成されたアートは偽造/海賊版とみなし商品として物販コーナーでの取り扱いを禁止する事にしました」とのこと https://t.co/Dkoo7W8iWw
— ヨーヘイ/Animator (@YoheiKoike) November 16, 2022
DeepLの翻訳だけどこちらに添付。
AI生成アート作品に関する公式方針
最近、AIで作られたアートワークとそのコンベンション空間(展示ホール、アーティスト・アレイなど)での位置づけが、多くのネット上の議論の焦点になっています。
ネット上での議論に注目が集まっています。私たちスタッフは、この議論を注視してきました。
このような事態を放置しておくわけにはいかないと判断しました。
このような製品を私たちのスペースに存在させることは誠意を持ってできません。
私たちアニメロサンゼルスは、AIによって生成されたアートピースが私たちの販促物に使用されることを容認しませんし、受け入れません。
また、展示ホールやアーティスト・アレイで販売することも認めません。
もし、販売されている作品がAIで作られたものであるとスタッフが判断した場合、それは偽造品とみなされます。
模倣品・海賊版と判断し、撤去をお願いする場合があります。
ブランドに関して、私たちはアーティストが制作した作品を非常に大切にしています。
私たちのアイデンティティとコンベンションスペースにもたらす価値を認識しています。ウェブサイトに掲載されているもの。
ウェブサイト、プロモーション用作品、製品に掲載されているものはすべて、私たちが直接仕事を依頼したアーティストによって制作されたものです(今後もそうあり続けます)。
直接仕事を依頼したものです。AIによって作成されたものは非公式なものであり、アニメロスのスタッフによって承認されたものではありません。
のスタッフによって承認されていません。
このポリシーにおいて、アーティストが所有していない、または権利を有していないソースを使用するAIプログラムによって作成された作品は、違反であるとみなします。将来、そのようなプログラムが作成された場合。
将来、アーティストが所有する特定の画像のみを使用できるようなプログラムが作成された場合、アーティストの責任において、その画像を提供する必要があります。
将来的に、アーティストが所有する特定の画像のみを使用できるようなプログラムが作られた場合、その作品が盗用された画像から作られたものではないことを証明するのは、アーティストの責任になります。
私たちはこの立場を堅持し、今後の議論を見守りながら、この立場を徹底していきます。
今後ともよろしくお願いいたします。
ジェネレーティブ AI は、3D 以来、ゲーム業界に起こった最大の出来事、何が起こるでしょうか?
Generative AI is the biggest thing to happen to the game industry since 3D. If you're in games, and you're not experimenting with it, then you're already behind.
— James Gwertzman (@gwertz) November 17, 2022
Some observations and predictions on just how revolutionary it's going to be. 👇 pic.twitter.com/O4VNi3WozN
ゲームにおけるジェネレーティブAI革命
プロンプトチャレンジ:映画を見ているミツバチ
海外でもプロンプトチャレンジが起きている。
Search is Overfitted Create; Create is Underfitted Search
近い将来の AI はアクション駆動型であり、AGI によく似たものになるでしょう
脳のダイナミクスを解くと、柔軟な機械学習モデルが生まれます
ジェネレーティブ AI が創造的な仕事をどのように変えているか
AIにできないこと
AI凄い!という話ばかりなので、一応AIへの期待値が中庸な記事。
— bioshok(INFJ) (@bioshok3) November 17, 2022
2026年までにAIが「できないこと」https://t.co/55pvIw2zff
・ハリウッド映画をエンドツゥーエンドでは作れない
・みんなが隣人にシェアするほどのブログ等のコンテンツは生成できない
・複雑な(1万行)コード生成はできない
創発、スケーリング、帰納的バイアスについて
勉強
拡散モデルと基盤モデルの関係について
新しい動画です。拡散モデルと基盤モデルの関係について、
— mi141 (@mi141) November 18, 2022
・基盤モデルによる拡散モデルの拡張
・基盤モデルとしての拡散モデルの活用
の2つの視点で、様々な技術をざっくりと紹介してます。
社内講演の再録なので資料は英語ですが、日本語で喋ってます。お気軽にどうぞ~https://t.co/s72pcvTe0G pic.twitter.com/MCM6mRLz23
最後に
Twitterに、毎日製作したものや、最新情報、検証を載せたりしています。
よかったら見ていただけたら嬉しいです。
画像生成AIの実験, 最新情報のまとめはこちら
過去の号はこちら
次の号はこちら
サポートいただけると喜びます。本を読むのが好きなので、いただいたものはそこに使わせていただきます