
【IMPS2023 参加レポート】 国際学会に参加して気になった研究のまとめ

この記事は【IMPS2023 参加レポート】 国際学会初心者が実際に足を運んで現場情報をお届けします!の、私が初めて参加した国際学会での経験と学びを詳しくお伝えする続きとなります。
IMPS2023で目にした数々の興味深い研究の中から、特に印象的だったものを選び、その内容と感想をテーマ別にまとめて共有させていただきます。この学会での経験が、今後の研究や学びの参考になれば幸いです。
テーマ1:計量心理学におけるログデータ活用
その中でも私が特に興味を持ち、深く学びたいと感じたテーマ「計量心理学におけるログデータ活用」に焦点を当て、Tomasz Zoltakさんの短期講義の内容と私の感想を共有したいと思います。
研究1:From Collecting Log-data to Analyzing Process Indicators with logLime R Package

説明
タイトルにある「ログデータ」は、Webアンケートシステムのログデータを指しています。Webアンケートシステムのログデータをデータマイニングすることで、最終的な回答結果を測定するだけでなく、特定の結果をもたらした前のステップやアクションという回答者の問題解決プロセスを分析することを目的にしています。

前半の形式は講義で、Tomasz Zoltak博士は「パラデータ」(Para-data)について説明しました。パラデータとは、データの収集方法に関する情報であり、さまざまな形式で存在する可能性があります。通常、応答時間、ハードウェアおよびソフトウェアの情報、タイピング速度、アクションシーケンス、マウスの移動、センサーの地理位置情報などが含まれます。
そして、彼は「ログデータ」(Log Data)について、パラデータはデータ収集の背景やコンテキストを提供するのに対し、ログデータはシステムの動作やユーザーの行動を詳細に記録すると説明しました。両者ともに、データ分析の際には前処理やクリーニングが必要となることが多いです。特に、大量のログデータやパラデータが生成される場合、そこから関連性のある情報を抽出するための処理が必要となります。それは「プロセス指標」(Process Indicators)です。
特にオンラインシステムの無制御環境では、さまざまな設定、デバイス、干渉、およびマルチタスク処理などの要因が存在します。これにより、同じデータ形式でも異なる方法で解釈や処理される可能性があります。また、回答者が使っていたブラウザウィンドウのサイズが通常異なりますので、スクロール補正をする必要もあります。
その後、Tomasz Zoltak博士はパラデータに関する先行研究の制約について説明し、自分で開発した『logLime』というパッケージがログデータの収集、前処理、および最も一般的なプロセス指標の計算までの完全なプロセスをカバーできることを言いました。
後半の講義は実際の分析を実践して、主にR言語でのパッケージの使い方について説明しました。このパッケージは、ログデータの類型を区別し、異常なデータをクリーニングし、カーソルのスクリーン座標系を修正することができます。
最後に、ヒートマップやGIFを使用してアンケート調査の結果の生成過程を表示します。これにより、回答者がアンケートに回答する際にマウスをどのように移動したか、カーソルが画面のどこにどれだけ滞在したか、最終的な回答を提出するまでに何回修正したかなど、視覚的にデータを解析する方法は、非常に直感的でわかりやすいと感じました。


所感
実際にこのログデータから何を分析することができるのかが気になったので、自分でログデータマイニングに関連する論文を検索してみたところ、教育ビッグデータの文脈におけるログデータマイニングとその応用
--中国におけるPISA(2012年)問題解決テストの事例研究という論文では、2012年のPISAの中国地域の「交通」という質問回答に関するログデータ(回答時間、マウスクリック数、マウスの移動範囲など)を使って、学生の行動パターンを分析し、戦略的習得と非習得のレベルが異なるグループを特定し、地域間の学生問題解決パターンの相違点の把握と比較をしました。
この短期講義を通じて、ログデータは大量に保存しながら実用に至っていないケースも多いと思いますが、実は非常に価値のある情報源であることを改めて認識しました。今後、私自身の研究や業務においても、このようなデータを活用して新しい知見を得ることができるのではないかと期待しています。
テーマ2:計量心理学と機械学習の融合
心理統計学の研究分野には、古典的テスト理論・項目反応理論に代表される心理測定手法や、実験や行動データに基づいた数理モデル以外に、機械学習などの技術も取り入れられてきています。
特に、近年では大量のデータを扱うことが一般的となり、その中でのパターンの発見や予測の精度を高めるための技術として、機械学習手法が注目されています。機械学習は、データから自動的にルールやパターンを学習する技術として、心理統計学の研究においても個人の心理的特性や行動の予測、異常検知、クラスタリングなどの多岐にわたるタスクでの応用が進められています。
今回のIMPS2023も機械学習セッションが設置されて、その中からいくつか面白い研究を紹介します。
研究2:Integrating Psychometric Analysis and Machine Learning to Augment Data for Cheating Detection in Large-Scale Assessment
この研究では、大規模評価データを使って、心理測定分析と機械学習手法によるデータ拡張をして、カンニング行為検出用のモデルを構築しました。バリバリに機械学習を使った心理測定研究ですね。
大まかに言えば、次のような内容です:
概要
課題:カンニング行為検出用のモデルの精度をさらに上げたいです。
手法:心理測定分析と機械学習手法によるデータ拡張をして、ベースモデルの出力と最も効果のある特徴量を使ってメタモデルを構築します。
結果:類似の研究で報告された値と比較して、最も高いF1スコアでカンニング行為検出精度を効果的に向上させました。
説明

Data Augmentation in Machine Learning for Cheating Detection in Large-Scale Assessment: An Illustration with the Blending Ensemble Learning Algorithm - Scientific Figure on ResearchGate. Available from: https://www.researchgate.net/figure/Data-augmentation-in-blending-learning_fig1_366822903 [accessed 4 Jan, 2024]
使用したデータは、カンニングの可能性が高い大規模な免許試験のデータです。テスト用紙は170個の正誤データで構成されています。1636人の受験者のうち、46人がカンニングの可能性があると判定されました。データセットは、項目回答、回答時間、合計項目回答時間、テスト受験の試行回数で構成されて、合計342の変数が提供されました。SMOTEとRandomUndersamplingでカンニングと非カンニングのクラスの不均衡問題を解決しました。
データ補強に四つの方法を使いました。それぞれ要約統計量に基づく拡張、異常検出に基づく拡張、パーソンフィット測定に基づく拡張、スタッキングアンサンブルに基づく拡張です。
要約統計量に基づく拡張は、テスト総得点、170項目にわたる平均値、中央値、最小値、最大値、項目応答時間などを使用特徴量に追加しました。
異常検出に基づく拡張は、Isolation Forest、Elliptic Envelope、One-Class SVM、Local Outlier Filterなどの異常検出アルゴリズムから出力された外れ値フラグを使用特徴量に追加しました。

パーソンフィット測定に基づく拡張は、テストやアンケートに対する異常な反応を検出することを目的とした一連の指標をRのパッケージPerfitとsirtによって算出して、使用特徴量に追加しました。ちなみに、今回「心理測定なんて誰が気にするだろうか?」を講演したKlaas Sijtsma教授が、ここでのパーソンフィット尺度の$${H^{T}}$$統計量(ある回答ベクトルと残りの人物の回答ベクトルとの類似性を定量化するための相関指標)を開発しました。


パーソンフィット尺度とは、観察された反応パターンが検査モデルから導かれた期待反応パターンと一致するかどうかをチェックすることです。例えば、ある受験者が、より難しい項目には正答したが、より簡単な項目には正答できなかった場合、その回答パターンは「予想外」、「異常」、「誤答」であると考えられます。
それで合計29のパーソンフィット尺度が計算されて、カット値を設定して不適合者と判定された受験者に対してフラグを立てて、ベースモデル開発のための特徴に加えました。

スタッキングアンサンブルに基づく拡張は、フィルター法、ラッパー法、埋め込み法などの特徴選択法によって、モデル性能と解釈可能性に影響するノイズや重要でない冗長な特徴量を削減しました。
最初にベースモデル開発をするために、決定木、ナイーブベイズ、ニューラルネットワーク、判別分析、ロジスティック回帰、サポートベクトルマシンとランダム・フォレストと勾配ブースティングを選びました。8つのベースモデルは、項目応答(170個)、項目応答時間(170個)、および要約統計量(7個)、パーソン・フィット尺度(29個)、および異常検出手法(4個)に基づく拡張特徴(合計380個)を使用しました。

ベースモデル開発に使用された特徴量のうち、上位の効果的な特徴量がメタモデル開発のための拡張特徴量として選択されました。重複する特徴を除去した結果、55個のユニークな特徴が残りました。55の有効な特徴量のうち、2つのパーソン・フィット尺度、1つの異常検出尺度、5つの総テスト得点と応答時間の要約統計量、 20の項目応答時間変数、27の項目応答変数がありました。

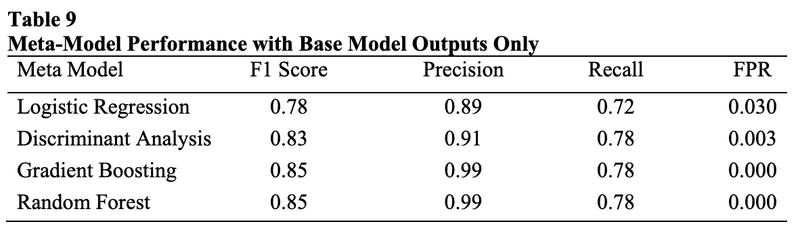
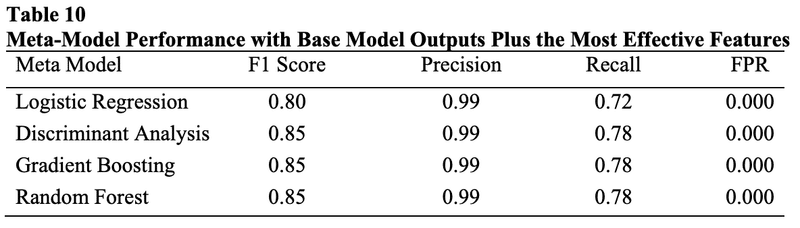
異なる特徴選択手法から選択された最も効果的な特徴量を集めて、ベースモデルから選択された55個の特徴量と各ベースモデルから出力、合計63個の特徴量がメタモデル開発に用いられました。ロジスティック回帰には改善が見られた。本研究で開発されたランダムフォレスト、勾配ブースティング、判別分析のメタ・モデルは、同じデータセットを使用した他の研究と比較して最も良い結果を示しました。
所感
個人的な感想ですが、この論文の最も優れた点は、データ拡張手法と精度向上のための様々な機械学習手法を非常に幅広く使用していることです。この論文を読むと、まるで体系的な機械学習の事例研究を見ているような印象を受けました。機械学習モデルに心理統計学で計算されたパーソンフィット尺度を特徴量として入れるのも面白いです。
研究3:Mixed effects in machine learning – A flexible mixedML framework to add random effects to supervised machine learning regression
概要
大まかに言えば、この論文は次のような内容です:
課題:機械学習モデルにランダム効果を入れたいです。
手法:機械学習と混合効果モデリングを組み合わせた混合効果機械学習フレームワーク(mixedML)を開発します。
結果:実データに対しても、伝統的な混合効果モデリング手法と一致した推定結果が得られました。
説明
クラスター化されたデータは、実は伝統的な心理統計学、社会科学、経済学、医学だけでなく、違う都市の天気予報や異なる地域の住宅価格などの機械学習問題でもよく考慮されています。この場合、データはいくつかのクラスターに分かれており、同じクラスター内のデータは関連性を持っています。このようなデータを扱う際に、同じクラスター内のデータは独立でないため、通常の統計的仮定が成り立ちません。推定の誤りや誤った結論を引き起こすことがあります。
こうした問題を解決するための一般的なアプローチは、ランダム効果をモデルに入れることです。そういうクラスターデータの具体的な説明と、社会心理学や社会学、経済学でよく使われているマルチレベルモデルは、以前のブログ記事を参照することができます。
この研究では、混合効果機械学習フレームワーク(mixedML)を紹介しました。これは既存な機械学習と混合効果モデリングを組み合わせたモデルです。教師あり回帰モデルやディープラーニングモデルに直接適用することができ、クラスターデータに対する予測力を高めることができます。そして、この研究は一つのフレームワークに手法を統一し、そのフレームワークの中で新しい推定手法を追加するとともに、機械学習手法の選択も柔軟にできます。
混合効果機械学習フレームワーク(mixedML)の詳しい中身は論文をゆっくり見て欲しいです。このフレームワークの有用性を実際のデータでテストするために、Snijders & Bosker (2011)の教科書で紹介されているデータセットを使用しました。データセットには、211個の異なる学校にグループ分けされた3758人の生徒の言語テストの結果が含まれています。生徒レベル(レベル1)では、生徒のIQと社会経済的地位(SES)を使用します。学校レベル(レベル2)では、学校平均IQ(sIQ)と学校平均SES(sSES)を用います。

このモデルのパラメータ推定値をSnijders & Bosker (2011)の結果と比較して上の表6に示しました。この研究で使われたREML推定法は、実データに対しても、伝統的な手法と一致していると結論づけられます。結構強力な機械学習モデルと言えます。
所感
このモデルをどう適用するかと言えば、今のAISCの全国賃料予測ツールは、各都道府県のデータごとに教師あり機械学習モデルを訓練しています。なぜなら、 都道府県ごとの平均家賃相場も異なるですから。もし各都道府県の平均家賃相場をランダム効果と見なし、mixedMLによって全国賃料予測機械学習モデルが一つのモデルにまとめられるかという発想がありました。
テーマ3:項目反応理論のモデルをツリー構造に
IRTree(Item Response Tree)は、心理学や教育学の分野でよく用いられる項目反応理論(IRT)を基盤としたモデルの一つです。このモデルは、項目応答にたどり着くまでの被験者の反応プロセスを詳細に分析するために開発されました。
今回の学会では、いくかのIRTreeのモデルや、実際のデータに適用した結果などの研究発表が行われました。これらの発表を通じて、IRTreeの有用性やその応用の幅が広がっていることが確認されました。
また、IMPS2023には掲載されていないものの、IRTreeに関する基本的な概念やモデルの詳細、IRTreeモデルを推定できるパッケージなどをわかりやすく説明した文献を検索しました。以下で紹介します。
IRTreeの概要:A generalized item response tree model for psychological assessments
普通の項目反応理論 (IRT) モデルは、心理評価および行動評価におけるカテゴリ別項目反応を分析するために広く使用されている心理統計手法です。数学的には、特定の応答項目が選択される確率は、その人の潜在的な特性を説明できます。
この研究では、結果だけでなく内部の認知的または心理的意思決定プロセスにも焦点を当てた新しい IRT モデルに関心があります。このモデルは、サブツリーとそれに対応する内部ノードと分岐で構成されるツリー構造を使用して、仮定された内部意思決定プロセスを記述することができます。木は葉に達するまで枝を分岐し続けます。葉は、観察されたカテゴリ項目の応答を表す終端ノードです。このモデルは、ツリー構造を利用しているため、項目反応ツリーモデル(IRTree)と呼ばれます。
以下の図は、よくあるIRTreeの構造です。

ツリー (a) は、カテゴリ 1 から 4 までの順序での応答の連続選択を表します。「まったく悲しくない」、「少し悲しい」、「ほとんど悲しい」、「完全に悲しい」などの選択肢を含む単極スケールのために使用できます。
ツリー (b) は、2 つの隣接するカテゴリのグループが最初に選択される 2 段階の選択プロセスを示しています。 そして、隣接するカテゴリのペア内で最終的な回答が選択されます。「完全に悲しい」、「やや悲しい」、「やや楽しい」、「完全に楽しい」のようなオプションを持つ双極スケールを記述するために使用されます。
ツリー (c) では、カテゴリ 1 の選択は他の 3 つのカテゴリ (2、3、および 4) とは定性的に区別されており、カテゴリ 1 を選択しない場合はフォローアップの決定が必要です。例えば、カテゴリ 1 は「悲しくも楽しくもない」、「おそらく」、「わからない」、「未定」、「?」などの中間応答、カテゴリ 2 ~ 4 は通常の応答カテゴリを表します。
ツリー (d) では、カテゴリ 1 と 2 は質的に異なる 2 つのオプションであり、カテゴリ 3 と 4 とも区別されます。3 と 4 の間の選択には 2 番目の決定が含まれます。
項目反応ツリーは、項目応答カテゴリの独特の特徴を説明するために利用することもできます。
そして、項目反応ツリーは欠損データに対して扱うこともできます。欠損データは心理評価や行動評価においてよく発生しています。一般的な欠損データ処理方法には削除法と代入法があり、代入法でも少なくともランダム欠落(MCAR、MAR)が必要です。項目応答ツリーのアプローチは、欠損データメカニズムをモデル化するのに便利なツールです。

段階 1 では、人は応答するかどうかを決定します。
段階 2 では、人は 4 つの順序付けされた応答カテゴリの中から 1 つのカテゴリを選択します。
SA は強く同意、A は同意、D は同意しない、SD はまったく同意しない。
この論文ではRのパッケージflirtを紹介しましたが、他にもirtrees、mirtのパッケージを使用することができます。
これからはIMPS2023で実際にIRTreeに関連している二つのポスター発表研究です:
研究4:Investigating Pre-knowledge and Speed Effects in an IRTree Modeling Framework(Hakyecong Kim, Justin L.kern)

概要
課題:
予備知識効果は、テストにおいて受験者が試験を受ける前に既に試験の問題や答えに接触した場合に発生します。
予備知識が応答時間と正答率に影響を及ぼすか、応答時間が正答率に影響を及ぼすかを調べたいです。
手法:
2段階ネストのIRTeeモデルで予備知識効果と速度効果を調べます。
第一レベルのノード$${Y_{1}^*}$$は速度の潜在的特性$${\tau_{j}}$$に、第二レベルのノードは能力特性$${\theta_{j}}$$によって制御されます。
第二レベルのノードは、第一レベルのノードへの応答に依存しています。ノード2の$${Y_{2}^*}$$は、ノード1への応答が遅いと評価された場合に、ノード3の$${Y_{3}^*}$$は、ノード1への応答が速いと評価された場合に到達します。
ノード2およびノード3の切片(つまり、難易度)は異なる値を持つようにし、2つの切片の差$${\delta_{i}= \beta_{i3}-\beta_{i2}}$$は、ノード1への応答の違い(つまり、速度効果)が原因です。
予備知識効果は、予備知識を持つ、持たない被験者の間のパラメータの違いです。
結果:
第2レベルの速度効果に制約がなく、速度に対する一定の予備知識効果、および第2レベルノード全体にわたる一定の正答率予備知識効果があるModel 10モデルの適合度が一番良かったです。
速度に対する予備知識効果は正であり、テスト前に項目を接触したことが迅速な応答をもたらすことを意味しています。迅速な応答の確率が約30%増加します。
正答率に対する予備知識効果は正でした。つまり、予備知識は正しい応答の確率を約45%増加させます。予想通り、予備知識は正しい応答向上をもたらしました。
正答率に対する予備知識効果は、応答の速さに依存しませんでした。
研究5:Empirical comparisons among models in detecting extreme response style(Jianhung Huang, Hui-Fang Chen)

概要
課題:
項目反応モデルの枠組み内で、極端な応答スタイル(ERS)を識別するためのモデルが提案されており、これらは3つのアプローチに分類できます。
第1のアプローチは、ERSを意図された測定される潜在能力以外の別の次元として扱い、アイテム応答に影響を与えるものです(例:MNRM)。
第2のアプローチは、ERSが各応答カテゴリ間の異なる空間をもたらす可能性があることを認識し、各カテゴリのしきい値の重みパラメータを設定して個々の参加者のERSを推定します(例:ERS-GPCM)。
第3のアプローチは、IRTに意思決定モデルを組み込みます。ERSの存在を参加者間で示すために二項指標を使用します(例:UD tree)。
手法:
極端な応答スタイル(ERS)を検出するアプローチの実用化を促進するために、実データセットを使用してベースラインモデルGPCMと三つのアプローチの性能を比較しました。
結果:
すべてのアプローチが同じく潜在能力の推定値を提供し、相関は0.70から0.99の範囲で、UD treeは他のアプローチからの潜在能力の推定値との関係が最も弱かったが(それでも中程度から高いレベルで)、相関がありました。
ERSの推定に関しては、異なるモデル間の絶対相関は0.61から0.88の範囲でした。MNRMが一般的に他のモデルよりも優れていました。
説明
この学会の多くの発表者は、反応スタイル(Response Style)によって正確な評価が脅かされる可能性があると言及しました。反応スタイルには極端なカテゴリを好むタイプ(ERS)と中間のカテゴリを好むタイプ(MRS)があり、これらが個人の回答に影響を与えることが報告されています。
ERS とは、参加者が声明への同意を 0 (まったく同意しない) から 4 (非常に同意する) までの 5 段階評価で評価するときに、評価カテゴリー 0 と 4 などの 2 つの極端なエンドポイントを使用する傾向を指します。MRS の回答者は、2 つの「反対の極端な」カテゴリを避け、すべての項目にわたって一貫して中間範囲の回答カテゴリ (1、2、3 など) を選択する傾向があります。
ここでのUD treeは、IRTreeの一種です。

UD treeの構造は、まずステップ1では、発言に対する否定的、中立的、肯定的な態度を決定するのに対し、ステップ2では、より極端な回答、より極端でない回答、中立的な回答があります。回答者は、ステップ1で賛成でも反対でもないことを選択するか、ステップ2で賛成か反対かを強調しないかの2つのルートで、中間のカテゴリーを選択することができます。このツリー状のアプローチは、ステップ1から測定された潜在能力とステップ2から得られた回答スタイルを同時に推定することができます。
テーマ4:regdifパッケージで複数の DIF 共変量を処理
実は、口頭発表やポスター発表以外にも、スポンサー展示エリアでも論文を手に入れることができます。

今回私はcoffee break areaでduolingoの企業ブースに行って、そこの担当者はシールやペン、そしてある印刷された論文をくれました。その論文を書いた方は急な事態で来られなかったが、企業ブースに論文を配布していました。


研究6:The regDIF R Package: Evaluating Complex Sources of Measurement Bias Using Regularized Differential Item Functioning
概要
実は大まかに言えば、この論文は次のような内容です:
課題:測定バイアス (MB)、つまり潜在変数の測定特性の差異を複数の連続的かつカテゴリ的な背景変数 (性別、年齢、文化など) にわたってMNLFAで同時に評価できるようになりましたが、応用研究者が正則化 DIF (Reg-DIF) を実装することが困難です。
手法:regDIFという R パッケージに対して、シミュレーションデータと実際のデータを使用してこれらの機能を実証します。
結果:Reg-DIF メソッドの比較的高速かつ柔軟な実装であることが示されています。複数の背景変数、さまざまな項目応答関数、および複数のタイプのペナルティ方法の同時モデリングが可能になります。

(a) 単純な測定バイアス。グループ (文化的グループなど) が分析の単位です。
(b) 複雑な測定バイアス。個人 (文化間の異なる年齢など) が分析の単位となります。
最後に
以上は私が学会に参加し、その中で特に興味を引かれた研究を選び、まとめてみました。この記事を通じて、私が学会で得た知識や感想を少しでも皆様と共有できたら嬉しいです。もしこれらの研究に関する理解に誤りがあれば、教えていただけると幸いです。
また、これを読んで興味を持たれた方が、さらに深く研究テーマに触れてみたいと思うきっかけになれば嬉しいです。
参考文献
首新, 叶萌, 胡卫平. 教育大数据背景下log数据挖掘与应用: 以PISA (2012) 中国区问题解决测验为例[J].电化教育研究, 2017, 38 (12) :58-64.
Jiao, H., Yadav, C., & Li, G. (2023, May 2). Integrating Psychometric Analysis and Machine Learning to Augment Data for Cheating Detection in Large-Scale Assessment. https://doi.org/10.31234/osf.io/fjz2c
Tendeiro, J. N., Meijer, R. R., & Niessen, A. S. M. (2016). PerFit: An R Package for Person-Fit Analysis in IRT. Journal of Statistical Software, 74(5), 1–27. https://doi.org/10.18637/jss.v074.i05
Pascal, K., Sangbeak, Y., Augustin, K. (2022, Dec 18). Mixed effects in machine learning – A flexible mixedML framework to add random effects to supervised machine learning regression. https://openreview.net/forum?id=MKZyHtmfwH&nesting=2&sort=date-desc
Jeon, M., De Boeck, P. A generalized item response tree model for psychological assessments. Behav Res 48, 1070–1085 (2016). https://doi.org/10.3758/s13428-015-0631-y
William C. M. Belzak (2023) The regDIF R Package: Evaluating Complex Sources of Measurement Bias Using Regularized Differential Item Functioning, Structural Equation Modeling: A Multidisciplinary Journal, DOI: 10.1080/10705511.2023.2170235
この記事が気に入ったらサポートをしてみませんか?