noteユーザーに捧げるR tutorial #2

前回はRを導入したので、今回から早速Rを使って【標本平均】や【標準偏差】などといった様々な統計学の計算をやってみよう。
今回の目標:オブジェクトを理解し、基本的な計算をRで行えるようになる。
【目次】
1. 簡単な計算からやってみる
2. オブジェクトを使ってみよう
3. R言語の基本的なモード
4. ベクトルタイプという便利なタイプ
5. 演習
1. 簡単な計算からやってみる
Rを起動すると、R consoleが立ち上がって> (プロンプト)が命令を待っている状態になる。早速> に続けて命令を書いてあげよう。
例えば、Rに算数をさせてみる。
足し算 : +
引き算 : -
掛け算 : *
割り算 : /
例えば(3+5×2)÷2-10はこんな感じ。
(3 + 5 * 2) / 2 - 10【Enter】を押すと命令が実行される。[1] -3.5と返ってくれば成功だ。
2. オブジェクトを使ってみよう
プロンプトに適当な文字を打ってみよう。例えば「りんご」と打って【Enter】してみる。
りんご「エラー: オブジェクト'りんご'がありません」と返ってきたはずだ。これは皆さんが初めてみたRのエラーだと思う。Rのエラーはとても親切なので、面倒くさがらずに読むことをお勧めする。今回のエラーからは次のことが分かる。
(1) Rに文字を入力する時は、なんらかの形式がある。
(2) オブジェクトというものがある。
このオブジェクトというもの、Rを使う上で最も重要なのでぜひ覚えてほしい。オブジェクトは箱のようなもので、例えば次のように使う。
りんご <- 80 # りんご1個当たり80円
みかん <- 120 # みかん1個当たり120円
3 * りんご + 2 * みかん # りんご3個とみかん2個の合計金額りんご3個とみかん2個の合計金額600円が返ってきていれば成功。<-は代入演算子と言って、
りんご <- 80は、80という値を「りんご」というオブジェクトに代入したことを意味する。
りんごと打って【Enter】を押すと、80という値が返ってくる。適切なオブジェクト名をつけると、スクリプトがとても読みやすくなるのでオブジェクトの名前は拘ってつけることをお勧めしたい。
ちなみにオブジェクトは上書きできる。
りんご <- 80 # りんご1個80円だった。
りんご
りんご <- 60 # りんご1個が60円になった。
りんご # さっきと返り値が変わる。
3. R言語の基本的なモード
R言語には、数値や文字などを扱うためのモードがあって、それぞれに様々な処理や計算を実行するための関数が準備されている。
mode("ねこ") # 文字
mode(1) # 数
mode(TRUE) # 論理それぞれ、"character", "numeric", "logical"と返ってきたはずだ。
(1) 文字モード character
Rで文字はクオテーションかダブルクオテーションで囲う必要がある。囲わない場合、それはオブジェクトと判断される。例えば、文字モードにはncharという関数が用意されている。
nchar("ねこ", type = "chars") # 文字数を数える
nchar("ねこ", type = "bytes") # byte数を数える例えば、記事の単語数を数える時に使うので便利。
(2) 数値モード numeric
Rで数値を扱うときは、そのまま数を使えばよい。ここで数をダブルクオテーションで囲ってしまうと、文字として判断してしまうので注意しよう。
mode(1)
mode("1") # 比較してみよう数値モードには最初に紹介した四則演算+, -, *, /以外にも便利な関数が様々なあるが、これらの紹介はベクトルタイプを導入してからにしよう。ちなみに、特別な数値に非数値NaNと無限大Infがある。
0/0 # NaNが返ってくる。
1/0 # Infが返ってくる。これらは、しばしば計算時にエラーが起きた時に出てくるので、知っておくと便利。
(3) 論理モード logical
論理モードには、条件式が正しい・間違っているときの返り値TRUE, FALSEや、無回答を意味するNAなどがある。
2 < 3 # 3は2より大きい (TRUE)
2 > 3 # 3は2より小さい (FALSE)
4. ベクトルタイプという便利なタイプ
ついにRで実際のデータを扱う上で、とても重要なタイプを勉強しよう。それはベクトルタイプだ。
c(1, 2, 3, 4, 5) # 1から5までの数値の列
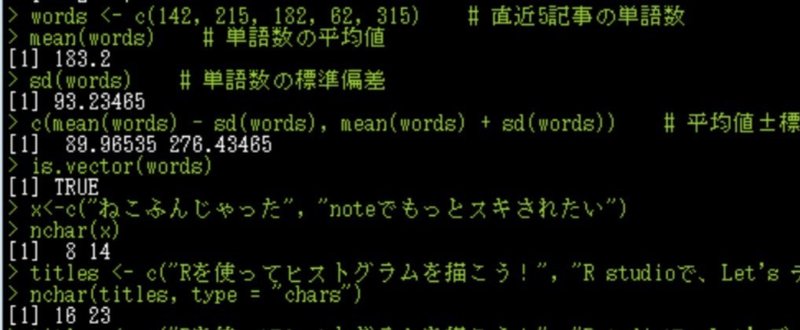
c("cakes", "note") # 文字列ちなみにcはcombine valuesのcから来ている。ベクトルタイプを使えば、数値モードの列を1つのオブジェクト、文字モードの列を1つのオブジェクトとして扱うことが出来る。例えば、直近のnoteに投稿した記事の単語数も
単語数 <- c(142, 215, 182, 62, 315) # 直近5記事の単語数
mean(単語数) # 単語数の平均値(mean)
sd(単語数) # 単語数の標準偏差(standard deviation)
c(mean(単語数) - sd(単語数), mean(単語数) + sd(単語数)) # 平均値±標準偏差のように扱うことが可能になる。この様に、Rでのデータ分析はベクトルタイプによって支えられている。
5. 演習
Ex 1. 次のようなタイトルのついたnote記事がある。
・Rを使ってヒストグラムを描こう!
・R studioで、Let's データ分析!!
(1) 記事タイトルをまとめたオブジェクトを作成せよ。
(2) それぞれの文字数をカウントせよ。
【Ex 1の解答】
titles <- c("Rを使ってヒストグラムを描こう!", "R studioで、Let's データ分析!!")
nchar(titles, type = "chars")ちなみに(2)の結果から、nchar関数は空白も1文字としてカウントすることがわかる。("R studioで、Let's データ分析!!"の空白を詰めて、やり直してみよう。)
Ex 2. 以下の問いに答えよ。
(1) 次の演算の返り値を予想し、実際にRで計算してみよ。
c(1, 2, 3) + c(2, 2, 2)
c(1, 2, 3) + 2
c(2, 1, 5) * c(5, 5, 5)
c(2, 1, 5) * 5(2) 以下はR scriptとその実行結果である。[ア], [イ]に当てはまる適切な数値を答えよ。
> c(3, [ア], 2, [イ], 1) / c(2, 0, 0, 3, NA) # 実行したR script
[1] 1.5 NaN Inf NA NA【Ex 2の解答】
(1)の答え
それぞれ、次のような返り値を得る。
[1] 3, 4, 5
[1] 3, 4 ,5
[1] 10, 5, 25
[1] 10, 5, 25
同じ長さのベクトルどうしの演算の場合、それぞれの要素ごとに演算を実行する。1行目と3行目はその例だ。一方で、2行目と4行目の返り値からも分かるように、Rはベクトルと数とでも演算できて、数を片方のベクトルの長さ分だけのベクトルだとみなして演算する。いわゆるブロードキャストだ。
c(1, 1, 1, 10, 10, 10) * c(1, 2, 3)
c(1, 1, 1, 10, 10, 10, 100, 100) * c(1, 2, 3)この2行の返り値と、特に2行目を実行した際に起こるエラーは、Rのブロードキャストを理解する上でとても示唆的なので、ぜひ参考にしてほしい。
(2)の答え
[ア] : [ア] / 0にNaNが返ってきている。もし[ア]が1や2など0以外の数値であれば、3番目のようにInfが返ってくるはず。故に、[ア]は0だとわかる。
[イ] : [イ] / 3にNAが返ってきている。[イ]はNAである。普通の数値が[イ]であれば単純に割り算の結果が返ってくるし、仮に
NaN / 3
Inf / 3としてもNaNやInfが返ってくる。
Ex 3. 最近、sadaakiさん / konpyuさん / fladdictさんが書いたノート記事のタイトルを集めてみました。
・すべてをjsにまとめる思想を理解する
・noteでコードが投稿できるようになりましたβ
・#今週のお題 「ハマってる食べ物」に参加してみる
・セレブになったら…
・個別記事に、「他者のオススメ記事」をつける実験をはじめました
・noteの注目デザイン・マーケ記事を、slackに自動配信するには?
(1) 記事のタイトルをひとつのオブジェクトにせよ。
(2) 記事のタイトルの文字数をカウントし、その結果をオブジェクトにせよ。
(3) 記事のタイトルの文字数の平均値と標準偏差を求めよ。
【Ex 3の解答】
タイトル <- c("すべてをjsにまとめる思想を理解する", "noteでコードが投稿できるようになりましたβ", "#今週のお題 「ハマってる食べ物」に参加してみる", "セレブになったら…", "個別記事に、「他者のオススメ記事」をつける実験をはじめました", "noteの注目デザイン・マーケ記事を、slackに自動配信するには?")
文字数 <- nchar(タイトル, type = "chars")
文字数
mean(文字数)
sd(文字数)大体23±9文字くらいが、note.muの方々の平均的なタイトル文字数のようす。
【補遺 : スペースと文字数のカウントについて】
ところで、
・#今週のお題 「ハマってる食べ物」に参加してみる
には、「お題」と「ハマってる食べ物」との間に半角のスペースが空いていることに気づいただろうか。nchar関数はスペースも1文字としてカウントする。もし、この半角スペースを削って文字数をカウントしたければ、
タイトル_スペース削除 <- gsub(" ", "", タイトル)
文字数_スペース削除 <- nchar(タイトル_スペース削除, type = "chars")とすることで、半角スペースを削除することが出来る。gsub関数は文字の置き換えを行う関数で、
gsub(置き換える前の文字, 置き換えた後の文字, 文字の置き換えを行うオブジェクト)という形で用いる。
サポートをいただいた場合、新たに記事を書く際に勉強する書籍や筆記用具などを買うお金に使おうと思いますm(_ _)m