
発音記号の作り方、および多言語対応とNFTベースのフォントという話

さて、まぁ、今回は前々回の続きでフォントにおける多言語対応の……というおはなしなんだけど、本来このネタはオリパラに合わせて話を作っていたのに、個人的な都合で色々ありすぎ、間が開きすぎてタイミングも逸したので、内容を再構成しなおし発音記号の話を少し追加。それで、する予定だった話の一部はまた別の機会に……といってもまぁ、待ってる人もいないだろうし黙っていればわからない話を冒頭にされても困るだろうけど、なんか謝ってから始めないとなかなか筆がのらないというそういう気分って……え? わからない? まぁ、すみません、そんなかんじなので粛々と進めます。
多言語対応と言った場合、まず、ここで問題になるのは、世界中に存在する膨大な数の書記体系をカバーするフォントファミリというものは……まぁ、ほとんど存在しないという事実だ。調和のとれたルックアンドフィールですべての言語をサポートするという謳い文句のNoto Fontsはその例外のようなものだが、常識的に考えてもこんな馬鹿みたいなことができるのは金と労働力を湯水のように使える組織だけなので、将来に亘ってもGAFAM以外でこんなことをするフォントファミリは出てこないだろう……と考えられていたのだが、現在では自動化の方法も進んで、開発もAIでどうたらとかUMLでどうしたとか、いろいろ変なことを考える人はいるので、技術的アプローチのやり方次第だけど、金と労働力に頼らなくても、もしかしたら案外どうにかなっちゃうんじゃないか……というはなしもあることはある……といっても現状ではまだNoto一択というか、金融資本と人的資本が大きいところには敵わないので、金も力もない組織にこんなことは不可能……なのだけれど、実はフォント開発に必要な金と労働力の手配を何も無いところから調達してしまうというという素敵なアイデアも存在する。

font.communityというNFTベースのフォントプラットフォームが計画していることがその例で、自前のトークンを発行しそれで報酬を設定することで、金と労働力と、可能ならば業界の支配力までをも手にしようなどということを目論んでいる。多言語対応化などのコストのかかる書体の包括範囲の拡張や少数言語の開発に対してもより多くの報酬……まぁトークンだけど、それを支払うなどすればいいなどという……自分で札刷ってりゃそりゃぁなんでもできるよねというマイニング魂の震えるやり方だ……ただ、葛西の知恵ブログによればトークン自体は5分もあれば誰でも作れるそうなので結果最終的に$FONTが詐欺コインにならなきゃいいのだけれどね。まぁ、自前のプラットフォームに乗せるフォントをNFTして資産化することでフォントで信用創造されたフォント本位制の$FONTという早口言葉のようなトークンと、NFTフォントの両輪で資金を調達しようという皮算用。必要なのはやる気だけで一文無しからでも始められるビジネスみたいな話で一歩間違えるといろいろアレだけど。ただ、このビジネスアイデアをそのままそっくり日本で真似するのはいろいろグレーなところがありすぎる気がするんだけど、まぁ、どうなんだろう? 教えてKasaiさん?
ところでNFTというのは、Non-Fungible Tokenの略で、知っている人には今更だがざっと説明すると、暗号通貨と異なり相互交換できない。ビットコイン同様サトシ・ナカモトの応用技術で、簡単に言えば複製や改竄をしにくくした鑑定書付きのデジタルデータといったところ。規格でいうとEthereumのERC721とか1155とか……まぁ、そんなかんじのアレ。ご存知の通りデジタルデータは容易にコピーが出来るため、物理的な製品と異なり昔はそんなものに資産価値があるとは見なされなかったのだが、イーサリアムブロックチェーン上での仮想猫売買なんかに端を発するこのNFTというデジタルテクノロジーの出現により事態は一変する……まぁ、デジタルアセットでアセットマネジメントなんて下手な落語家の洒落みたいなことが容易にできるようになったというわけだ。ただ、これが俄に注目を浴びだしたのは最近で今年の春頃からのことになる。
tweet一本が3億円で落札されたり子供の落書に馬鹿みたいな値段が付いたりしたことなんかがニュースになるなどしてNFTの認知度があがってきた事により取引がどんどんと活発化し前年比20倍だったっけ? え? 数字が全然違う? 見るところによっていろいろと言う人が多いうえ興味も無いので実はよく覚えていないんだけど、まぁとにかくそんなかんじで、急拡大する巨大な売買市場で資産化困難だったデジタル塵がジャンジャン取引されるようになったのもその理由の一端だ。そういうことでなんとまぁ大盛り上がりしてしまっている。なにしろ理屈の上ではデータならばどんなゴミにも価値を付けることが可能になり原資となるデータは理論上無限に作り出せるので信用創造の限界点は青天井、マネタリーベースの急拡大が止まらない。バブルか? バブル来ちゃうのかぁ〜! もう皆のワクワクが止まらない……というところなのだが、ただ、あまりにも急速に取引が拡大したため関係者のモラルがハザードして、いろいろとやらかしてはいるようだけど……まぁそれもともかく。
で、これと、DeFi(Decentralized Finance)の技術なんかによりガス代に代表されるような金融コストも下がっていっていろいろなことが整ってくるので……まさしく絵に描いた餅の収益化もいよいよこれから本格化してしまうのではないのか……これはもしかして儲かってしまうのではないのではないだろうかということで、日本でもコンテンツ関連企業のみならず、いづみや……あ、大分前に名前が変わったんだっけ……まぁそれはともかく、そういうデザイン用品なんかの開発製造販売企業までをもNFT経済圏のゲームプレイヤーに名乗りを上げさせてしまうという事態に発展。ましてや金融業いわんや……と、まぁ、そんなのを含めていろいろとみんなが浮き足立ってきているという今日この頃、いかがお過ごしでしょうか……なんて、そういう感じ。多分、あいかわらず、何を言ってるかわからないかも知れないけど、noteの中でルビが付けられる新機能が追加されたのでコレを利用することで前より少しはローコンテクスト出来ているはず……え? 還って分かりづらくなった? まー、でも、これ、量子云々や素数方程式の発見どころかエルサルバドルするだけでいろいろな前提が……ゲフォン、ゴホン……いや、いや、何も無いですよ〜、ホント雑談が多くてすみません。
それで、そのFont CommunityのNFTベースのマーケットプレイスのサービスはというと……現在はまだベータバージョンなので、この先どう転ぶかサッパリわからないのだけれど、彼ら……と言う言い方も感情的被害者意識を刺激するので彼ら彼女らにしたほうがいいのか順番を彼女ら彼らにするほうがいいのか「ら」ってついてるんだから当然女も含まれているよとかソレなら彼女らだけでもおかしくないのかとか社会的に公正でも中立でもないオレみたいな人間がどだいソコに気を遣う必要があるのかとかこんなアホなコトにエネルギー使いすぎると主張すべき内容すらアホに見えて逆に実質的な差別的行為そのものの軽視に繋がるので本末転倒も過ぎるだろうとか抑々社会や言語に公正も中立もネエ! え〜、そこから? とか、ホントいろいろ考えすぎると、くだらなすぎてもうほんとうに千葉県警の啓発動画ぐらいにどうでもいいけど、まぁともかく、その彼らの計画しているはなしというのはちゃんと上手く回っていくようだと多言語対応化なんて小さな話に留まらず業界全体を破壊的創造してしまうほどの爆発力のある内容なんだそうけど……って、そのあたりの話はもっとちゃんとした人にキチンとやってほしいくらいだけど……まぁ、機会があればそのうち。
さて、それで、こちらは、まぁ、その小さな話の続き。そんな、いろいろと見合わないコストのかかる多言語対応なんだけど、それでもUnicodeでは全ての多言語を一律に扱うことを目的としているので、これを利用するとラテン文字をベースに発音記号を追加するだけで、英米語からフランス、オランダ、ドイツ、イタリア、チェコ、スロバキア、ポーランド、スペイン、ポルトガル、カタルーニャ、バスク、スウェーデン、デンマーク、ノルウェー、フィンランド、アイスランド、エストニア、ラトビア、リトアニア、ポーランド、ハンガリー、ルーマニア、トルコ、クリミア、アゼルバイジャン、ベラルーシ、エスペラントから東洋のベトナムに至るまで、実に多種多様な何十種類にものぼる言語対応をひとつの規格にまとめてしまうことができる。ただ、実を言うとUnicodeのこの言語仕様のため各国の文字を個別に取り出そうとする場合、グリフのコードはさまざまなUnicodeブロックに散らばってしまい「あら大変」という恐ろしいことが起こるのだけれど、まぁ、その話は長くなるのでまたそのうち。
それで、まぁ、これに多少追加文字を加えれば、アイルランドからアフリカの文字表記にも不自由しない立派な多言語対応のフォントセットを作ることだけはできる。19世紀に西ヨーロッパが世界の大半を植民地化した関係で、地球上で東欧、中東、極東を除くあらゆる場所がラテン文字の影響下におかれてしまっているという事情もあるので、仮にラテン文字だけのフォントセットであっても、これをもって100を越える言語に対応などと謳っても……詐欺にはならない……と、思う、多分。とにかく、これがアルファベットにダイヤクリティカルマークを付加するだけの簡単なお仕事で済むので……自作のフォントにそんな仕掛けを施しておいても損はないよという……まぁ、そういうお話だ。
といっても、さてさて、本来、そもそも発音記号とダイヤクリティカルマークは概念としては別枠なので別種の集合になるのだけれど、まぁ論理積として重なる部分は大きいので、そこのところ意味や発音は違うけど形は同じだからまぁ良いよねというUnicodeの仕様と相俟って、まぜこぜに理解しても、アレがアレってこともないっちゃぁ〜ないのだろうけど、ただ、細かい事を言い出すとそれはそれで色々面倒なことももちろんいろいろあることはある。なので、先に注意しておくと今回のはなしは書いてるうちにそのあたりの区別が段々ボヤボヤっとしたかんじになってくるかもしれないので……いや、まぁ、いつものことだけど、ホント、ちゃんとした知識はちゃんとしたところでというのは良い子のみんなのお約束だからね……というわけで注意書きも済んだので始めようか。
コンピュータのために符号化された初期のアルファベットの体系は8ビットのデータからパリティビットを除いた7ビット128種のキャラクタからさらに16進2列分の制御文字分を除いた印字可能な96文字……削除とスペースを印字と捉えればだが……の範囲で構成されていた……この量は現代英語で必要とされる範囲の文字を扱うだけならばまったく問題はなかったのだけれど、欧州圏全体に拡張するといささか心許なくて、発音記号を合成した他の文字を挟む余地もほとんんどなかった。というか、まぁ、そもそも、初期のコンピュータが主に英語圏で開発されていたということもあって、最初はあまりそのことに関しての優先順位が低かったり必要を感じていなかったということもあった。これはまぁ、ラテン語由来の体系としては何故か奇跡的に英語がダイヤクリティカルマークを必要としていない書記体系として完成してしまっていたという偶然もあるのだけれど、世界を見渡すと、逆に、この日常的に発音記号を使用しないという文字の方が実は少数派だったりする。例えば日本語ですらここまでの文中に既にもう相当数のダイヤクリティカルマークと長音記号や捨て仮名という拗促音などの表記記号等が潜り込んでしまっている……ので、ここで代わりに本文をそれのないフォントに代替してしまうと残像に口紅を……っなんてことになってしまい、まぁ、たとえば仮にここまでの文章でそれをするとすると、ちゃんと表記されない率という、つまり符号誤り率に直すと、なんと、これが一割にも達するということになる。まぁこれだと情報伝達の信頼係数が低すぎて、電電公社に納品する通信線なら一発で不良品扱いになる。いや、ちょっと何を言っているんだかわからないけど。
とは言うものの、実は一割足らないどころか、他人の話なんて一割耳に届けば会話は成立するので、無くてもたいして困らないという向きもあることはある。残像が口紅したところでかなりの程度まではなんとかなるんだよということは筒井康隆も証明するところではある……といことでケースによってはたとえ本文書体だとしても余計な文字を作らないことで活字字母の制作費を削減して費用を安く済ませよう……なんてことも過去にはあった。イヤ、今でもあるところにはあるけど、まぁ、ともかく、それなので、日本がまだまだ貧乏だった明治大正昭和の初め頃には拗促音や濁点等を使わないという表記方法も一般的に普通に存在した。今でも「キヤノン」と書いて「キャノン」と読ませるという小学校三年生と小学校三年生より賢くない人には理解できない謎ルールとして歴として現存している。
また、物理的な性能の限界という理由で、初期の勘定系システムなどでは濁点付きの文字を1文字扱いすると必要なキャラクタが一気に増えてASCIIの範囲では計算機能力が不足するので、濁点等を分離して、それを計算上の1キャラクタとして扱うことにして50音プラスアルファの扱いで……まぁ、そういったこともあった……というか全銀のレイヤー上 は今だにその前世紀のルールで稼働しているんだよ……なので、各銀行は今ではそのため口座データに対して逆の変換作業が必要になっているのだけれど、そういう事情で、名前に濁点が付くか付かないかで文字数の勘定が一致しない……つまりいろいろなところで舟橋(4文字)だったり舟橋(5文字)だったりするのを本人があまり拘っていなかったりしていたりしたりすると、後々とんでもないことになったりするのだ。大丈夫「りそな銀行」に口座があるなら今がまさにそれだから……って、それ大丈夫じゃないやつ〜!
まぁ、それでも概ねは、そうなっていても困ること無く生活は出来ているよね……と言う話で、ただ、そういったかんじの貧乏性の名残でもって、いまでもルビを振り出すときにその区別を了としないという編集者も一部で存在していたりすることがある。つまり脱水症状ではなく脱水症状とルビを振らないといけないわけだが、まぁもう少し細かくいうと脱水症状でないと怒られたりもするのだけれど……え? 違いがわからない? う〜ん、まぁ、そういうところだよね、怒られるのは。

そういうことなので、あっても、なくても、いいような記号という意識の人も多いのでオーソグラフィーが決まりにくいところでもあり、さらには英語みたいに発音と綴りとのギャップなんか気にしないという言語圏の中で育ってしまった連中には発音符なんてなんのために存在するのかすら意味不明になってしまっているのではないか……とも愚考するんだよね。
それで、こういう認識の文化圏にいると、こういう符号なんてフォントデザインを汚すだけのゴミみたいなものにも見える……という感じなので、なるべく目立たないように作りたくもなるだろうけど、世界中を見渡すと多くの言語で文字の諸要素の建て付けは、ベースになるグリフに枝葉となる記号を付加してそれで一文字を形成するという構造を持つもののほうが実を言うとずっと多いので、枝葉を軽視するようなことをすると後でいろいろと困ることも多い。これには認知科学的な問題もあって各言語圏の人類が文字の字形を脳がどう処理しているかのおはなしにも関わってくるのだけど……これを、はじめるとまたながくなるからなぁ……まぁ、簡単な話で言うと日本語のように読むときに左右の脳をフル回転させる必要のある文字と主に左脳だけで言語処理が完結する文字とでは構成要素をどうするのが有効かという違いがあって、人が文字の中にダイヤクリティカルマークを認識した場合、言語圏によってこれをどちら側の脳が処理を担当するかという違いの……って、いや〜簡単な話で終わりそうに無いなぁ……まぁ、いいや、この話はまたこんど。
で、そういうややこしいはなしはともかく、というわけで、大昔から多言語世界であった欧州大陸でウホウホ言っていたバルバロイ達が帝国の文明を受容する過程で、どうも自分たちの話している言語を単純にラテン文字に置き換えただけの表記では発音の区別すらいろいろと出来ないということから始まったイレギュラーな工夫が発音記号……と、言いたくなるところなんだけど、文字に補助記号を振るという発想自体はラテン語以前からあり、古代ギリシアにはポリトニックシステムというかなり洗練された方法が存在していたのだが、あまりにも複雑で時代が下るにつれ忘れ去られて、現代ではギリシア語もギリシア文字もモノトニックなシステムに成り下がってしまったけど、ギリシアが世界史の中でもっとも偉大であったその当時はこの補助記号を二階建て三階建てにしてあらゆる音をラベル付けして……あ〜、そうだ、それでいうと楽譜に纏わる面白い話もあるけど……まぁ、それもいいや、とにかくそういう複雑なことも行われていたので、古典文献学なんかだとこのあたりの知識が足ら……まぁ、どんどん脱線するなぁ、まぁ、その話も置いておくとして、そういうことで、その偉大なギリシア文明に当てられていたローマ人自身もラテン文字の欠陥についてはある程度は認識していたはずで、足らないところをギリシア文字の借用で済ましたり分音記号として小っちゃい字をベース字母の上に重ねたりして表現することがあった。このやりかたは後にジャーマンミューテーションの母音交替記号に流用されたので、古い独語のテキストではウムラウト記号がその形……というような話をどこかで聞いた覚えがあるのだけれど、出典資料がとっちらかって何処行っちゃったかわかんなくなった……まぁ、とにかく、ラテン文字のダイヤクリティカルマークの変遷もルーツをちゃんと辿れるかと言われるとなかなかそう単純なはなしにはならない……それに、こういった分音記号の表記方法がローマ帝国的には何処までオーソグラフィーだったのかどうかは、いってるこちらにも本当にふわふわとした知識しか無いものだからもうなんだかよくわかっていないのだけれどね。
で、ローマ時代の文字記録でまともに残っているものは看板文字の金石文よりは遥かに主流の情報伝達手段であったはずの紙蚊帳吊を使ったものの記録の残存資料が……って、まぁ、残っているモノも多くなく、かなり限定されるのでこのあたりのことも……本当のことを言えばまだ、よくわからないことがいろいろとあるらしいということぐらいしかよくわからない。ただ、そういったことで、仮定の話でするのもなんだけど、そのあたりの記号を付加した表記方法が当時普通に通用していたという前提でいうならば現代英語の特殊性のほうが益々より際立ってくる。ダイヤクリティカルマークの要らない文字はありません! 括弧英語を除く……みたいな? まぁ戯れ言はともかく、それで、そういった眼でローマ時代の碑文とかを注意深く見てみると激しく突き出たただの引っかき傷もアクセントマークだったんじゃないのとか、このティロの速記符号にも見えるような疵痕にも意味があるんじゃないの……というように大理石の傷すら発音符に見えてくるからね……まぁ、しらんけど。
で、あたりまえだけど、グリフを拡張していく過程で、存在しない音価に新しい文字を追加するということもないわけではないけれど、補助記号を使うという発想のある文字では、それよりは、既存の文字から意味を延伸したほうが、はるかに音がとりやすいので、通常はあたらしいデザインが追加されるということは滅多にはおこらない。
たとえばカナ文字なら日本語に本来存在しない有声唇歯摩擦音の「ぅぶ」っていう発音に、わざわざ新しい文字を発明するより「う゛」って書いてしまったほうが初見でも全然伝わるだろうからそうする合理的理由があるというのは 福澤諭吉でなくても誰でも思いつく。いや、まぁ、ヴの普及における福澤諭吉の役割にケチを付けたいわけでは無いんだけど、ともかく、そういうわけで金石文だけで見ていると小文字どころか補助記号すら存在しないように見えるラテン文字のアルファベットでもギリシア文字の影響は少なからずあったはずで、字母を変えずに発音記号で足らないところをまかなっていくというやりかたで、東西ローマが分割して西側が崩壊してしまうと……って、話し始めるとここから先がまだまだ、長くなるので……まぁ、いろいろすっ飛ばすと、そういうわけで、この手の分野は正書法というか標準表記の揺れ、ローカライズされたルール、スクライブ個人の気分ですらもが如実に影響していて、どういうふうにダイヤクリティカルマークを入れると正解になるのかというそういう理屈を見極めるのが非常に困難……実はラテン文字のダイヤクリティカルマークに特化した文字研究なんて話を寡聞にして拙い知識の中で知りうる限り殆どのところ見聞したこともないというかんじなので巷間言われる俗説なんかが……イヤ、なんというか、ホント、良い資料があれば紹介して欲しいくらいなんだけどね……ということなので、よく、なんたらの発音区別符号はかんたらだからこうデザインしないと駄目みたいに偉そうにマウントとりにくるおっさんもいるけど、いや、それ、何時の年代の何処の国の常識だよ! って思わず突っこみたくなるから、ホント……調べてみるとわかることよりわからなくなってくることのほうがずっとずっと多い……で、まぁ、百歩譲って「××のスタイルのフォントのアキュートの場合はここのこれはこうなので、こうでないとおかしい」とか、そういう言い方をされるのならば、まぁ、まだわからなくもないのだけれど結局文字資料なんて書かれたものに対する遺されたものの割合が微々たるものなので……いや、まぁ、ともかく、そんなかんじで、時代が下って今日ではラテン文字にはHenry Sweetから文句言われるほどのわけのわからないIPAの補助記号やら、ラテン文字でアフリカの言語やベトナム語の表記をまかなうためのダイヤクリティカルマーク、アラビア文字やインドや中国の文字をアルファベットで表記するための工夫なんかも盛り盛りなうえ、さらにはUnicodeのCombining Diacritical Marksなどという恐ろしい仕組みを利用したりすると構造がモンスターが過ぎて、これ、もうダイヤクリティカルマークが本体なんじゃ無いかって言うくらいの補助記号の山に……と、まぁ、いろいろあるのですよ、これはこれで……Combining Diacritical Marksの使い方に関しても一言で説明しきれないくらい面倒な話もいろいろあるので、これもまたそのうち。
で、まぁ、いつも以上にはなしが散乱してしまって、なんか、いろいろごちゃごちゃ書いたけど、何が言いたかったかというと、そういうことなんで、発音記号に気を使うのも大事だけれどあまり気にしすぎて腰が引けるより、自分の感覚を優先してデザインしてもいいんじゃないのというくらいの緩いはなしをしたかっただけなんだけど、内容よりも、はなしの散らかり具合の方が緩いことになっている。まぁ、細かい事は気にしない……ということで今はストリートビューでも、ネットで検索しても、いろいろリアルに近い現地資料が出てくるからこのあたり、あ〜、現場感覚はこんな感じなのかもね……という、感想ぐらいに留めておいてから後は自分の中の調和のとれたルックアンドフィールを先んじてデザインするのでも問題無いとは思うけどね。まぁ、おおむねは……。
さて、それでは、話は具体的に行こうと言うことで、いつものコーナー。
そういうことなので、今回はASCIIの範囲から始めてダイヤクリティカルマークで一気に、それも簡単に、フォントを拡張してしまうのにはツールをどう扱えばいいかというお話。いちばん簡単な多言語対応だ。ベースにするのは下のフォント、頭の悪そうなイタリアンで申し訳ないけど、まぁご愛敬だ。

多くのフォント制作アプリケーションには、図形を再利用する機能が備わっている。Glyphsでいう、コンポーネントというやつで、要は作ったアウトラインを効率的に使い回そうという寸法だ。この機能を使ってオリジナルのAをべースにÄ、Ă、Á、À、Â、Å……、CをベースにĆ、Ĉ、Č、Ċ、Ç……といった具合に、ダイヤクリティカルマーク付きのフォントをサックリ仕上げてしまう。簡単に言えば参照元の複数のベースグリフからコンポジットグリフを生成するということで、コンポジットされたコンポーネントは意図的にリンクを破壊するまでは作業中はベースグリフと常に同期しているのでベースグリフを修正するだけですべてのコンポジットグリフに反映されるという仕組み。ただファイルを別のフォーマットへ変更する場合はリンクが破棄されアウトラインが分解されることもあるので注意が必要だ。
もっとも、フォントをTrueType出力する場合に限っては、TrueTypeがオーバーラップされたコンポーネントを内部で保持するので、下の図のようなめっちゃバラエティ溢れるフォントでも、じみに圧縮率を高める鬼な工夫がほどこされる。なので、この場合ならフォント情報のカスタムパラメータにKeep Overlapping Componentsを設定して出力すればその被害は最小限に抑えることができるようにはなって……まぁ、程度にもよるけど、そういった情報を破壊しないように保存することもできる。これを明示的にでもなんとかしようとする場合OpenType featureのmarkとmkmkの理解が必用になるけど、まぁ、そのあたりの解説は今はいいか……。

ダイヤクリティカルマークの種類は、アキュート、ダブルアキュート、グレイブ、サーカムフレックス、トレマ、リング、ハーチェク、チルダ、ブレーヴェ、マクロン、ドット……なんかがベースグリフの上に乗って、セディーユ、コンマ、アンダードットが下に、オゴネク《鼻母音》が右下、まぁ記号に付けたルビは適当なので今は気にしなくて良い。あと、ストロークやホーン、フック等々が、まぁまぁ基本的な記号というところだけど、もちろん他にもいろいろある。で、いろいろあるけど、言語によってどの記号をどの音にあてるかというのも当然またいろいろあるわけだ。ただ、Unicodeでは基本的に意味や発音とかは気にしないで形しか見ていないので、チルダを鼻母音でとったり日本語の古いローマ字表記のやりかたのようにサーカムフレックスを長音記号に見立てるという言語でも、使うグリフはUnicode上では同じ場所にコードが割り振られてしまうということになる。それが嫌ならOpenTypeに言語対応を仕掛けておいて、ついでに仏語のトレマと独語のウムラウトでは点点を打つ高さが本当は微妙に変えた方が良いので、それにあわせて位置を僅かに調整しておくとか……まぁ、そういう方法も無くは無いけど、大抵のフォントでそんな面倒くさいフラグを立てたりはしないので……というか、殆どのユーザもよっぽどのことが無ければウムラウトの位置なんて考えもしないので、サーカムフレックスとキャレット、トレマとウムラウト、ハーチェクとカロンのように同じ形だとグリフが区別されなかったりする……このあたりにも記号の呼び方や使い分けが混乱してしまう一因があるのだけど、まぁ、伝われば呼び方なんて、チョンチョンでもニョロでもツンでもピョンでもなんでもいいという人は、本当に無理に気にする必要もない……そういうことが大切なのはプロフェッショナルなフォントデザイナーの中でも頂点の中のほんの一握りだけなので、ごちゃごちゃ言ったけどこのあたりの対応は対応させたい言語に合わせて使いたい形のダイヤクリティカルマークを用意しておけば……まぁ、だいたい準備完了ということになる。

ただ、フォントの制作時にダイヤクリティカルマークのコンポーネントグリフを最初に準備しておいたほうが作業的には楽……というだけで、大抵のアプリケーションは後からいくらでも文字を追加してリンクをアンカーすることは出来るので、最初に全部揃える必用も無い。セオリーの問題や、美学的なアポリアもあるけど、今回のフォントのようなデザインの場合、絶対に守るべき20のルールもクソもないので、それよりはアンカーのためのリンクが混乱しないようにグリフの名前の付け方に十分気をつける必要がある。
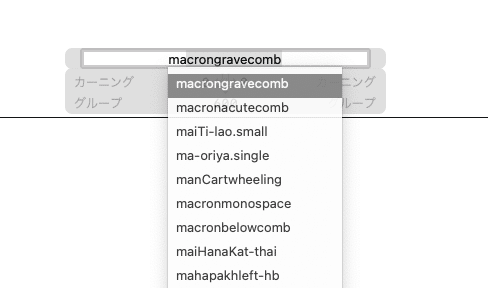
Glyphsではこれに、それぞれ「ナントカ」combという名前をつけグリフに_topアンカーとかを設置しておくことで、出力時にグリフ幅が0に変更されこの場合ベースグリフのtopアンカーを設置した位置へコンポーネントグリフが自動で配置されて楽チン……というふうになる。グリフ名はうろ覚えでも最初の何文字かを入れると補完されるので、newGlyphしたらグリフ名を適当に打ってからケツにcombって付いているものを選択すればOK。発音記号のシステム自体がよくわからなければ、足らないグリフを作るとき、下の図のようにして先に発音記号だけ作ってしまえばアプリが勝手に名前をつけてくれるから、まぁ、そういうやり方もあるよという話。この名前は場合によって変わるケースもあるで、Unicodeから例外的な扱いをされるようなマイナーなグリフの場合必ずしもこれが正解にならなかったりもするけど、まぁ、それでもあまり変なことをしてもトラブルの元になるので、こういう場合は素直に従っておく。

アンカーの構造は単純でベースグリフに名前の付いたアンカーを、発音記号には同じその名前にアンダーバーを先頭に付けておけばアンカー同士はそのアンカーの位置を基準点としてガッチャンコするという仕組みだ。

で、まぁ、例えばÄの場合、Aとdieresiscomb(Diaeresis≒Tréma≈Umlaut)の二つのグリフがあれば、diacriticsのreferenceのrecipeを参照してÄのフォントを指定すると、Aのtopアンカーとdieresiscombの_topアンカーの位置でÄを自動生成してくれたりするようになっている。大抵の場合説明はこれで終わりなのだけれど、フォント作成アプリケーションのdefaultに最初から用意されていないような特殊な合成グリフを作りたい場合は、アンカーを無視していちいち手作業を始めるか、なんとか+なんか=新しいグリフ……のような指示を予めdefaultのデータベースに追加しておく必要がある。
これには他にも、その場しのぎの別の方法があって、Glyphsの場合は新規グリフを作成する場合はOption+Command+Shift+Nや、フォントビュー下の+ボタンをポチッとする以外に、Command+Shift+Gもしくはメニューのグリフを追加…で表示されるウインドウから複数のグリフをスペースや改行で区切って入力することで生成できるのだけど、そのとき が ぎ ぐ げ ご と入力するのではなく、演算子を使って(ka-hira+voiced-kana=ga-hira ki-hira+voiced-kana=gi-hira ku-hira+voiced-kana=gu-hira ke-hira+voiced-kana=ge-hira ko-hira+voiced-kana=go-hira)と入力すれば、か き く け こ のグリフに濁点の合成されたダイヤクリティカルな、が ぎ ぐ げ ご が自動生成される……当然それぞれのグリフは先に存在しているコトが前提だけど、かきくけこがあるのにいちからがぎぐげごを作らなくてもいいんじゃないのという人向けのはなし。まぁ、そういう方法もある。゛

さりとて、そのアンカー位置をグリフ一個一個に設置するのもこんどはそれはそれで面倒そうなので、そういうことをしなくてもいいように、自動で必要なアンカーを割り振ってくれるという機能も当然存在する。大抵は、どんなフォント制作ツールでもプロ用アプリならdefaultのままでも必要十分なアンカーが設定されているはずなので、よっぽど変なフォントでなければこういうところは自動設定一発で済むようになっている……はず。

Glyphsの場合、こんな感じ。グリフを選んでメニューからアンカーの自動設置を選ぶだけ。アンカーの名前も含め全部オートマティック。ただし自動で振られたアンカーの位置や名前が気に入らないということは往々にしてあることなので、結局個別に手作業することになったりするのだけど、まぁ、ゼロから作るよりは簡単でしょ?
defaultの設定がどうしても気に入らないということであれば、Glyphsの場合各種データ属性の修正はGlyphData.xmlを書き換えてすることになっているので、アプリ内のそのファイルを修正する。ただしオリジナルを上書きしちゃうと面倒なことになるのでコピーを別のところへもっていってそっちでゴニョゴニョ修正するという感じ。Glyphsはアプリのオリジナルのxml を読み込んだ後UserのlibraryのApplication SupportのInfoフォルダー内にGlyphData.xmlがあれば、それで設定を上書きし、さらにフォントのデータの.glyphsファイルが存在するひとつ上の階層、.glyphsと同階層のInfoフォルダの中、.glyphsと同階層とそれぞれxmlが存在しないかを確認して、あれば最後にその設定で上書きされる。
ネットを探せばそれなりにカスタムしたxmlも見つけることはできるけど、そんなに複雑なことをしているわけではないので、自分でカスタムするのもそれほど難しいことは無い。だいたいのことは見ればわかるのでなんとかなるとは思う……けど、逆に言うと見てもわからない場合は弄っちゃ駄目だからね! あと、まぁ当たり前だけど、xmlを書き換えた後は再起動もお忘れ無く。

コンポーネントの位置合わせを個別に手作業で調整する場合メニューから自動整列を無効化しないとコンポーネントがロックされたままになるから……って、まぁ、このあたりの説明はなくてもわかるよね? それで、ここからフォントに新しいグリフをどんどんと追加する。Glyphsの場合、さっきの図にもあるようにフォントビュー左のサイドバーから任意のグリフを選択して生成ボタンを押すだけだ。GlyphDataの設定次第というところもあるけど、defaultの状態でもかなり多くの合成グリフがあっというまに完成する。ただ、さっき英語に発音記号はありませんなんて戯れ言をほざいていたけど、小文字のiとjは若干イレギュラーで、文字の頭にdotが振ってある合成グリフと見ることができる。これに’、え〜っと、例えば小文字の i を dotlessi とdotaccentcomb のコンポーネントでつくるコンポジットとして考えて、ドットのない小文字の i を予め用意しておけばiacuteやicircumflex、igraveとかもdotlessiとのコンポジットとして一挙に出力される。

まぁ流石に一発でどうにかなるものでもないけど、これでグリフ数で五百をオーバーし、対応国別数では五十カ国を軽く越えるというフォントがあっという間に完成する。たぁ言っても作っている人間が世界中の言語をネイティブに駆使したり、現地の言葉の細かい機微がわかるわけもないので、このことに意味があるのかと言えば、作った本人ですらあまりあるようにも思えない……まぁ、出来るからやってみた後悔はしない……みたいなことしか言えないのだけれど、ただ、まぁ、ここまですると、たとえ多言語対応を考えないようなファンシーな書体であってもデザインの破綻が如実に可視化されるので、リリースする予定は無くても問題点がハッキリして、デザインの行き詰まりを突破するヒントにもなったりするので、そういう観点からもこの手のテクニックは覚えておいても損は無い……ということもあるかもしれない。
まぁ、このフォントに関してはそれ以前の問題が山積みだけど、逆に考えれば、流石にこんなアホなデザインを繰り出して膨大な書記体系をカバーしようと考える人もいないと思うので、これはこれでコツコツやってりゃ何かにはなることもあるかもしれない……ぐらいのことは、考えたりもするけど。ただ、そのコツコツがなかなか出来なかったりするんだよね。駄目なことに。まぁ、それでもNFT化すればどんな塵芥にも価値は付く……付くんじゃないかな……多分……まぁ、そのあたりもホントよくわからんのだけれど。
この記事が気に入ったらサポートをしてみませんか?