
世界で一番利用されているフォント

世界で最も使用されているとか、世界で最も頻繁に利用されているフォントは何かという質問には、よっぽど気の狂ったへそ曲がりでもなければ誰に聞いてもたいていは、まぁ概ねヘルベチカという答えが返ってくるはずだ。多少気の利いた人か詳しい人にでも尋ねれば、Helvetica以外にもArial、Avenir、Baskerville、Bodoni、Calibri、Cambria、Courier、Didot、DIN、Franklin Gothic、Frutiger、Futura、Garamond、Gilroy、Gotham、Inter、Minion、Noto、Roboto、Times New Roman、Univers、Verdana……まぁ、こういうのは挙げていくとキリが無いんだけど、この辺りの名前のどれかが聞けたりすることがあるかも知れない。ただまぁ、この手の質問は聴く場所と訊く人と聞き方を少し間違えただけでこれらの書体の蘊蓄を永遠と聴かされ続けるという羽目におちいったりもするのだが、現代ではそういった弊害を回避できる便利なシステムが存在するので、このあたりは普通にAIにWhat is the most used font in the world?とかMost Popular云々とでも尋ねれば、一人の犠牲者を出すこともなく回答が与えられ、この解答はもうこれはこれでHelvetica一択ということにはなっている。

ただ、このことに関しては、俺みたいな気の狂ったへそ曲がりにはフォントに対する人気投票のようなその手の答えに違和感があり、この件に関しては個人的には別の解釈が存在する。
で、それは何かと言うと、それは現代の最も著名な伝説的書体デザイナーの手によって、おおよそ半世紀ほど前に制作されたフォントで、その制作後瞬く間も無くもの凄い勢いで全世界を席巻し、たとえ本は一冊も読まないなどと豪語するような人間でも日常生活においてはこの文字を一日たりとも目にすることなく過ごすということがはなはだ困難なほどに普及していて、そのように誰もが頻繁に目に触れているにも関わらず、水や空気のように常に消費され続けてしまうため、こういう質問が来るとそのことが多くの人々の記憶の中からスッポリと抜け落ちてしまい、Most Popularと尋ねられても、そのリストに名前が挙がることすらないという、AIの解答すら騙してしまえるという程の恐るべき認知の罠の仕掛けられているという書体だ。このフォントは、ファミリー化することがもはや当たり前のようになった現代においても、たった一つのスタイルしか保持しないという強い矜持を持ち、ありとあらゆる場所に現出しては蜻蛉の様に消えていくと……まぁ、この辺りまで言えば察しのいい人は気が付いたと思うけど、その名をOCR-Bと謂う。
フォントの名前を聞いただけでは、フォント名ならHelveticaやFuturaくらいならどこかで聞いたことがあるけどね……という程度の認識の人には、それと比べるとあまりにも知名度は低いので説明しないとよくわからないかも知れないけど、見れば一目瞭然でまぁ、以下のフォントだ。

と、最初に随分大袈裟なことを言った割には、なんか拍子抜けするような手品の種で申し訳ないのだけれど、コレが世界で最も頻繁に使用されているフォントだ。全体に対する使用面積が小さいうえ、すぐにゴミ箱へ直行してしまうので、記憶にも記録にも残らないかもしれないけれど、パッケージされるほぼ全てのオブジェクトに使用され、常に生産流通しつづけていて国境にも人種にも性別にもトレンドにも左右されることがないので、人気や流行に左右されるフォントの使用実績よりオブジェクトの生産高に応じて使用実績の濃度がどんどんと可算無限集合に限りなく接近し……うん、まぁ、なんか納得いかないという人には子安武人ボイスで「おまえは今まで消費したバーコードの枚数をおぼえているのか?」とでもいわせてもらうけど、まぁ、そういうわけなので、今回のお題はこのフォント……というか、まぁこのフォントを日本語化したOCR-Kを作るはなしをしようと思っているのだけれど、このOCR-Kも厄介は厄介で、OCR-Bよりは当然使用実績の濃度は低くなるので日本一とはいえないけれど、そこそこ利用されているハズ……にも関わらず、フリーはともかく、メジャーどころのフォントクラウドにすらすぐ簡単に使えるものが登録されていないというのはどういうコッチャと……まぁ、似たようなフォントならいくらでもあるからまぁ良いちゃいいんだろうけど……そういうことなので、どうなっているのかはよくわからないので、こっちで勝手に作ってしまおうという勝手なおはなしです。ハイ。

さてまぁ、とはいっても、実際の処、利用されているとはいっても、この手のはなしはホントウはホントにフォントが使用されるということは、どういうことなのかというところの定義のとこからはなしはじめなきゃいけないんだけれど、まぁ、ここまでの話は与太噺の類いなので、きちんとした統計がとれるようなことでもないから、まぁそこはあれとして……ともかくここでの結論では「OCR-Bは世界一」……ということにして強引に話を進める。
さて、この世界一のフォントの名前のOCRというのは、いまさら言うまでもないだろうけど、Optical Character Recognition/Readerことオプティカル・キャラクター・レコグニション/リーダーの頭文字で画像データの文字の部分を認識し機械で扱い可能なテキストデータに変換するというテクノロジーのコトだ。日本語では光学的文字認識とか光学文字認識ともいう。コンピュータの発達と共に機械と人間の双方で対話が出来る文字の必要から生まれた書体で、いわば機械にわかるようにデザインされたコンピュータ用UDフォントともいえるのがこのOCR書体だ。白黒でデジタル模様のコードだけだと機械にはわかっても、人間様にはわからないのでこういう文字が必要になるということになる。
で、この文字は今を溯ること60年近く前にOCR読み取り装置のために欧州コンピュータメーカー協会で規格標準化され、Adrian FrutigerによりMonotypeで開発された活字体で、名前の後ろにBが付いているのでお察しの通りBがあるならAがあり、こちらはATFことAmerican Type Foundersで同じく1960年代に設計され、米国のANSI(American National Standards Institute:米国国家規格協会)によってANSI X3.17-1981として標準化された。現在はそれぞれOCR-AがINCITSのInternational Organization for Standardization……つまりISOの1073-1:1976、OCR-Bが1073-2:1976(E)という規格になっていて……って、まぁそういう細かい事はどうでもいいんだけど、要は規格で字形が定められている書体なので、規格が決まっているから誰が作ってもだいたい同じような品質にはなる。まぁ、だいたいというところが厄介なんだけど、細かいはなしに関しては、余裕があれば後で説明する。

ちなみに、見ればわかるだろうけど話の途中に出てきた、OCR-Aというのはクレジットカードにエンボスしてあったりする数字でよく見る以下の書体。まぁ最近のクレジットカードはセキュリティのためカード番号をプリントしなくなっているのでカードで見たことないという人もいるかもしれないけどこういう字形。まぁ、これなら見ればわかるよね?
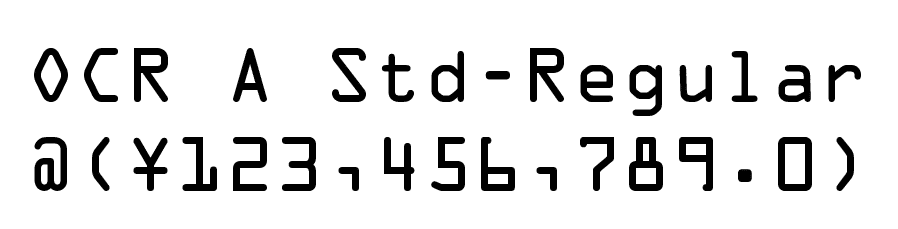
で、そういうわけなんだけど、現代ではコンピュータでも人間様でも認識できるということを目的としたその光学認識技術というものも格段に進歩が進んで、こういう単純な図形のフォントでなくても、機器での文字の読み取りに関しては、全く問題無くなったから、もはや専用のフォントが必要かどうなのか……と言うところまできていることもあるのだけれども、機械に優しいということはデータ処理に時間がかからないということでもあるので大マラソン大会のゼッケンナンバーに利用して、ドローンで上空から撮影した映像から、全ランナーを瞬時に識別分析して……え? その手の用途ならRFIDタグで充分?……いや、まぁ、そうかもしれないけど……ともかく今でもまだバーコード以外にも、請求書やカード番号とか、銀行のナントカとか、税務署の払い込み通知とか、まぁキッチリ、カッチリが求められるような、機械とお金の絡むようなところではそれなりに利用されてはいる。また、その特徴的な外観の所為で、特にOCR-Aは現代でも映像作品の字幕やタイトルなどでも効果的に使用され、おそらくOCR-Aの書影はバウハウス以降では最も成功した新しいスタイルの字形としても認識されてしまったので、それ以降の書体設計のトレンドを一新したということもいえる。

まぁということなので、このOCR-A字形を見ても今の人たちにはそれほど変には感じないかも知れないけれど、当時は過度に機械に優しくしすぎたせいで、その頃の一般人の常識的な意識からはあまりに斬新すぎて、醜いだの不快だの見苦しいだの悪趣味だのと……まぁ言ってみれば人間の目と脳には全然優しくなかったので、それとは違ってもう少し普通の人にもわかるようにデザインした……とされているほうの書体がOCR-Bというわけだ。

まぁ、そういうふうなことなんだけど、ただ斬新とはいってもOCR-Aなんかは実をいうとまだましなほうで、これ以前の1950年代に小切手なんかの処理の効率化のために開発されたコンピュータのための磁気インキ文字認識方式の……これはMICRというのだけれど、その0.013インチ砲試伍号改弐型と呼ばれる……じゃなかった、そのMICRのE-13Bと呼ばれるフォントともなると、これはもう殆ど機械の都合だけで出来上がってしまってもいるので、ここまで割り切るとさらにデザインがどうこうなどとはいえる代物ではなくなってしまっている。

MICR方式にはもう一つCMC-7という字形のフォントもあるのだけれど、こちらもこちらでかなり酷いことにはなっている……まぁ、この手の規格なるものはだいたい一つの経済圏の中ではどれかに統一しないと不便なことにもなるので、北米英国日本やアジア各国ではCMC-7を一般的には使用しない。当然JISの規格にも規定がない。日本では多分このCMC-7字形を見たことがないという人も多いんじゃないかな? CMC-7はE-13Bに対抗して欧州大陸……まぁ主にフランスやイタリア、南米などでE-13Bに替わってMICRフォントとして採用されていて、他にイスラエルでもCMC-7が採用されているので、パレスチナ人はE-13Bを採用することにした。いくらミサイル打ち込むほど仲が悪いからといってすぐお隣同士でこういうことをすると一般庶民には大変不便で困ったことにはなるので今のイスラエル国内では例外的に両方の規格が同時に利用可能になっている。また、欧州でも困ったことはあって、というのはこの規格が定められたのが€統一以前だったため……って、まぁ、このあたりの話は脱線が過ぎるからいいや……ともかく、そういうことで、OCR-Aは最初はOCRクラスAという数字のみの規格を想定していたというようなこともあって、E-13Bを光学認識用に単純にリデザインしたというような感じでもあり、数字字形に関してはE-13Bから多大な影響を受けてしまっていた。これが多分グリフをアルファベット全体に拡張する過程でも影響してしまったのでこんなデザインの字形になってしまったというその原因の一端ではあるのだろうとは思うのだけれど、そのおかげでクリエイターなら誰もが夢見るこういう斬新なスタイルのオリジナルな意匠が創作されアルファベットのデザインのトレンドの一ページに新たに追加されるという事態にはなった……とは思ってはいるんだけども……まぁ、そこの話もいいや。
さて、そこで、翻って日本では、やはり同様の用途で使用するためにJISこと日本工業規格……まぁ、今は産業規格と名称が変わったんだけど、その産業規格の〄X9001にOCR-AとB相当の字形の英数字、X9002に13インチ伍号弐型ことE-13Bを、そしてX9003にドメスティックな仕様に対応した今回のはなしのはじめのほうでも触れたカタカナ字形のOCR-Kという書体が規格化されている。
この文字はカタカナしか無いんだけど、欧文と数字はOCR-BもしくはOCR-Aと合成フォントを作るということが推奨されている……のだけれど、まぁこのあたり規格がまったく別ということもあるので上手く並べようと思ったら多少は工夫が必要になる。
ということで今回はこのカタカナを含めた日本国内仕様準拠のOCR-B+Kを制作……といっても、光学特性を測定するようなお高い機械の持ち合わせなどないので、検査、デバッグもまともにしてはいないから、これで正しくOCR書体としての用途に使えるかどうかと言うと、まぁやってできないこともないだろうけど、その辺りは残念ながら保証の限りではない。

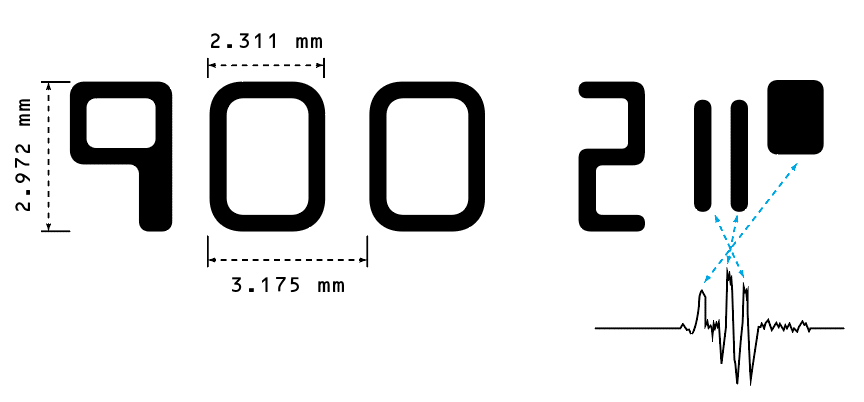
また、細部を言えば規格で字形が細かく定められているとはいえ、そのまま数値を入力するだけで線と線とがキッチリ接続して、そのままアウトラインをとって終了となるかというと、上の数値を入力してGeoGebraに作図させた下の図を見て貰えばわかると思うけど、指定通りにどこをどうやっても曲線と直線の接続で隙間やズレや不必要なコーナーが出来てしまったりすることはあるので、このあたりを細かく修正するという手順はどうしても必要になる。まぁ、こういうことがあるので、だいたいは誰がやっても同じような書影でできあがるということなのだろうけれども、残念ながら誰がやってもまったく同じものが出来上がるというわけでもない。いろいろと細部をどうするかは好みによる。まぁ、当然だけど。

また、句点読点長音記号は当然として濁点半濁点も一文字としてカウントするという仕様なので、このフォントで縦組に対応させようとすると、そもそもそういうことはまったく想定されてはいないのでそこにも無理が生じる。まぁ、今回はそれだと実用には困るので多少穢いトリックは仕込んでおいてはいるんだけど、そこもあとで解説しておく。あと、まぁ、OCR-Kは電算技術の発展の過程の都合のこともあってカタカナのみの仕様でひらがな漢字の規定が無いんだけど、そこも同様に実用上グリフが出ないと些か不便なので、漢字はともかくひらがなだけは光学認識のための日本語手書き文字書体の規格OCR-HHに準拠した……って、これもまぁ、個人的には制作途中なので、いつもおなじみの所謂フォントのお墓の中から、ひらがな文字の部分を抜き出して再利用している。こういうことをすると、それらのフォントを作ったときの気分的なモノをいまはすっかり忘れてしまっているということもあって、どうしてこうなっているのかがわからず、いろいろなところで整合性が無茶苦茶なことにもなるんだけど、まぁ、そのあたりもお察し。そういうことで、いろいろなところがちゃんとしていないということはあるにはあるんだけど、いつものごとく西塚涼子の作るフォント並みに余計なことだけは……いや、失礼。いや、まぁ、その、言っちゃったからなんだけど、そんな感じで余計な事だけはしているので、自分で言うのも何だけど、こちらのフォントのほうが市販のお高いOCR-Kよりは高性能で融通も利くようにはなっている……ハズ……なんだけど、厳密に規格のサイズを追い込んでいないなど、何度もいうけどそれに必要な検品を何もしていないので、ケースバイケースってこともあるだろうけど、何度も言うけどその手の用途で使用するのは厳禁ですよ!
まぁ、いろいろ駄目な問題もあるのはわかっちゃいるんだが、この手の産業規格化された書体はパブリックにも需用があることはあるので本当だったら科研費で作ったものをロハで利用できるようになっていればそこそこ国民の役には立つとは思うんだけど……なんだったら6億3千万円とはいわないので、お役所から補助金つくなら俺が代わりに公金チュウチュウしてもいいんだけど……って、いや、まぁダメだよねホント。
※Featuresの記述の一部に不具合があったのでファイルを修正しました(2023−12/26)
付録
というわけで今回のオマケのこの上のフォントのOpentypeFeatureについての簡単な説明。いつものごとく成り行き任せで機能を追加して逝っていることもあるので作った本人ですらどう機能するかわかっていないことだってあるのと換字のコンセプトやアルゴリズムがこれでいいのかというのは……まぁ、まだまだ問題はある。OpentypeFeature何て無視しておけば、昔のPSフォントよりはマシではあるけど……いやまぁ保証はしないけど。それからあとこのOpenType機能を有効にする方法についての解説はというと……って、まぁ、それを始めると長くなるから、そこはいいよね?
dlig 任意の合字。まぁ、いつものとおり余計な事をしないと死んじゃう病気なので当然のように余計な仮名文字が追加してある……といっても貂明朝アンチックみたいに全ての仮名に濁点と半濁点とかだの、ビックリマークの種類がやたら豊富だの……とかというほどでは全然ない。ここでは一文字分のサイズで収まるいくつかの合略仮名等を追加した程度に留まっている……のだけれど、普通に考えたら、これさえも迷惑このうえないので選択は任意になっている。デフォルトで無効。全ての合略仮名を全てリストアップするのは困難……というかまぁ多分不可能なことなのでこのあたりは何をやっても中途半端にはなる。また、この字形での合略仮名の一部の活字形は存在したことすらないはずのものなので、こっちで適当に好き勝手やっているだけだから良い子は真似しちゃダメだよ……仮名文字はこれにあとおばあちゃんの名前から蕎麦屋や寿司屋に至るまでに必要とされる変態……じゃなかった変体仮名と呼ばれる旧字形、島ことばとも呼ばれる沖縄の方言の表記に沖縄で提案されている船津文字こと新沖縄文字の15文字ほどの合略字、㌔とか㌢とかそういう感じの合字、あとそれら追加した字形含めてマンガの吹き出しから各地の方言の発音表記には必要になるため、西塚涼子よろしく全ての仮名に濁点半濁点を追加する……などなどと、やろうと思えばやれることはまだまだ幾らでも色々とあるにはあるのだけれど、まぁこのあたりもまたそのうち……ただ、合略仮名を追加した時点でもう既にこのフォントの制作コンセプトだけはブレブレになってしまってはいるんだけど……トホホ。

frac 分数。スラッシュで区切られた数字を分数に置き換える機能。この機能の詳細は前回解説したと思うけど、まぁ、あんな感じ。後述するけど使用に際して注意点はある。こちらもデフォルトで無効。

ssXX デザインのセット。スタイルセットのメニューからフォントのデザインのバリエーションが選択出来るようにはなっていて、メニューに日本語もしくは英語で説明が出るので、まぁそれ見ればわかると思うけど……数字が4種類、アルファベットはOCR-A字形が選択出来るようにはなっている。一部工事中のメニューもあるので、まぁこのあたりのバージョンアップもまたそのうち。これらの機能もデフォルトで無効。数字は別のメニューからでも違う種類が表示されるようにはなっているけど、まぁこのあたりはご愛敬だ。

kern vkrn ペアカーニング。および縦組ペアカーニング。基本的にこの書体はモノスペースなのでカーニング情報なんていらないのだけれど、それだと分数表示機能に問題が発生する。デフォルトで無効なのでので分数表示を使用する場合には同時に文字詰めでメトリクスを選択しておく必要はある。fracの機能を発動させるときにカーニングも同時に詰めちゃうプログラムにしておけばいいじゃん……とも思ってはいたのだが、違う種類のLookupを同時に使うときの制約のせいなのか、なんか上手くいかないので手間はかかるけどこういう仕様。あと、普通の文字を詰めて使いたいのであれば、その他の文字に関してはillustratorなどでオプチカルで詰めることをお薦めする。
salt いくつかの字形にオルタネイトが存在する。小文字のmに関してはJISの規格にそれがあるので、その文字を追加している。

vert この機能は文字を縦書きした場合にデフォルトの字形を縦組用に調整された字形に置き換える。こちらはデフォルトで有効なので、通常はCSSを記述しなくても動作するけど、レイアウトソフトと違って、まぁ大抵のブラウザは縦書きなんかサポートしていないので、概ね気にする必要はない。まぁ、このフォントは縦書きすることをあまり想定していないので縦組に関してはほとんど機能を盛っていないのと、カタカナをどうするかで迷ってしまっているので、多少使いづらいということにはなっているような気もするんだけどね。

さて、まぁ、あと他にもなんかいろいろやらかしていたような気もするんだけど、とりあえず目立つところで言えば、こんなところ。実をいうとアルファベット含めJISにはないけどISOには規定があるので追加しておかなきゃいけないダイヤクリティカルマーク付きの文字とか合字とかもまだ必要にはなるのだけれど、このあたりもいろいろ言い訳することがいっぱいあって、まぁ、それも含めてあんまり色々やっていると年が明けちゃうということでもあるので……って、まぁそういうわけでクリスマス……は、過ぎちゃったかもしれないけど、お年玉代わりにでも受け取って下さい。常識的なことさえ守れれば好きに使ってもらって構わないんだけど、これも毎回注意するけど、フォントの利用は自己責任で。お願いしますよホント。あとSauceの追加……じゃなかったSourceの開示等、不明点ご要望ご希望ご感想ご抗議ご苦情などなどがございましたら全部まとめてコメント欄へお気軽に。
この記事が気に入ったらサポートをしてみませんか?