Powerautomate Desktopで英文翻訳

はじめに
無料で使えるMIcrosoftが提供しているRPAツール「Powerautomate desktop」試してみました。
今回のタスクは、「英文翻訳」です。
英文のPDFファイルからテキスト(英文)を抽出
テキストをファイルに保存する
テキストを1500文字(仮に設定しています)に分割する
分割したテキストをGoogle翻訳にコピーして翻訳
翻訳されたテキスト(日本語)をコピー
翻訳されたテキストをファイルに保存する
という流れになります。
まず1500文字ですが、仮です。任意に書き換えてください。とはいえ、Google翻訳は5000文字が限界数ですので、それ以下で設定してください。
またなぜGoogle翻訳なのか?
それは以下のリンクを見つけたからです。
https://no-voids.hatenablog.com/entry/20211031
こちらではPDFから翻訳したい部分をコピーしてそれを翻訳しています。
またこちらに書かれていますが、Google翻訳ではファイルから翻訳も対応しているものの、PDFファイルでは改行コードの問題もあるようです。
そこでファイル(複数)からテキストを読み込み、翻訳するように修正してみました。
フローの作成
フォルダー内のファイルを取得
今回はPDFデータをDドライブのDataフォルダーに、結果をDドライブのresultフォルダーに保存する、設定で書かれています。
こちらのフォルダー名も任意に書き換えてください。
まず左のアクションから、「フォルダー」→「フォルダー内のファイルを取得」をMainにドラッグアンドドロップします。
ドラッグアンドドロップしたらMain上の「フォルダー内のファイルを取得」をクリックします。
これからも、アクションからドラッグアンドドロップしたら、クリックして入力という手順になります。
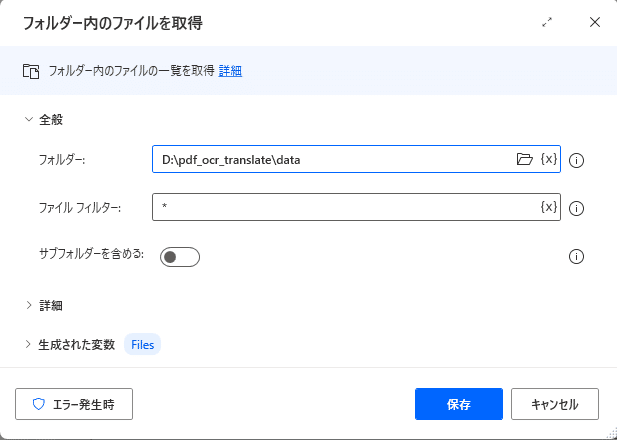
フォルダー横のファイルをクリックして、PDFが保管されているフォルダーを指定します。

今回はDドライブの pdf_to_translate 内にある dataフォルダーがそのフォルダーになっています。
これでフォルダー内のファイルリストが 「Files]という変数に格納されます。
変数の設定
このあと「Files」から順番にファイルを取り出します。そのために変数を設定します。
アクションから「変数」→「{x}変数の設定」を先程の下にドラッグアンドドロップします。
ドラッグアンドドロップしたら「変数の設定」をクリックして設定します。
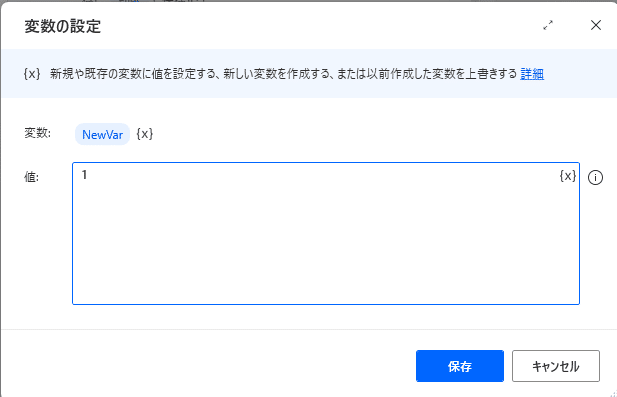
変数「NewVar」(設定されています)に値を入れます。
値欄に「1」(半角)を入力してください。
入力したら「保存」をクリックします。
ファイルの読み込み
「Files」から順番にファイルを読み込むので、ループ(繰り返し)の設定をします。
アクションから「ループ」→「For each]をドラッグアンドドロップします。
「For each」をクリックしてください。
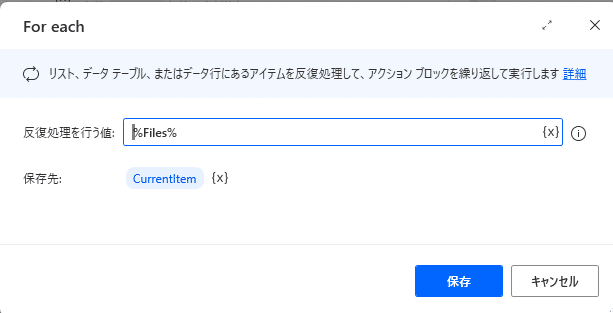
反復処理を行う値 を設定します。右側の{x}をクリックしてください。
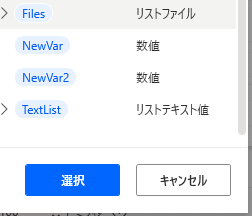
いろいろ変数が表示されていますが、皆さんは「Files」と「NewVar」しかないと思います。
ファイルの読み込みなので、「Files」をクリック
色が変わったら、下の「選択」をクリックしてください。
変数「%Files%」と入ったと思います。
これで、Fileを1つ取り出し、CurrentItemという変数に代入されます。
PDFからテキストの抽出
「For each」と「End]の間に、アクションから「PDF」→「PDFからテキストを抽出」をドラッグアンドドロップします。
クリックして設定します。
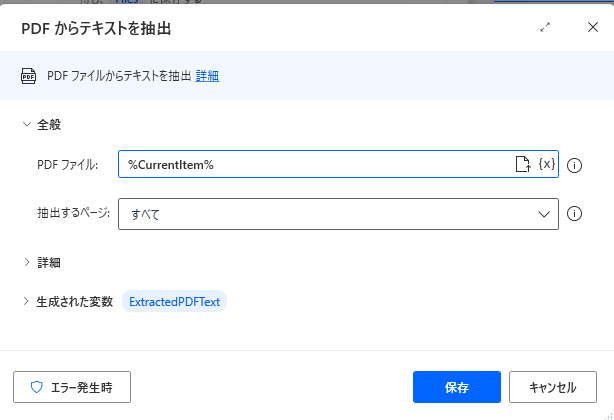
上の画面のように、「PDFファイル」欄は{x}から 「CurrentItem」を選択してください。
「抽出するページ」は「すべて」にしておくとファイル全体を読み込みます。
これでファイル中のテキストが変数「ExtractedPDFText」に保存されます。
テキストをファイルに書き込む(任意)
ここは任意です。抽出されたテキストをファイルに保存します。
ファイル保存がいらない方は飛ばしてください。
アクソンから「ファイル」→「テキストをファイルに書き込む」を「PDFからテキストを抽出」の下にドラッグアンドドロップします。
クリックして設定します。
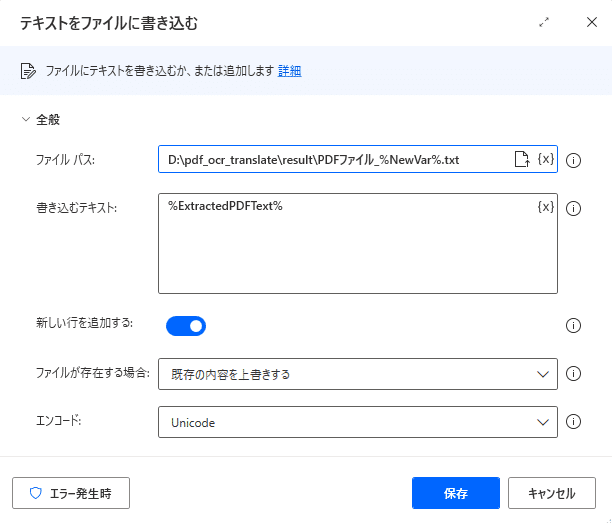
「ファイルパス」の選択、まずは右のファイルアイコンをクリックします。すると「ファイルの選択」画面が開きます。
ファイルの保存先を選択し、ファイル名今回は「PDFファイル_数値.txt」、数値はFilesの読み込み順としたいと思います。
ファイル名に、「PDFファイル.txt」として「開く」をクリックしてください。
ファイルバスにフォルダー名と「PDFファイル.txt」が表示されています。
画面上で「PDFファイル」のあとに「_%NewVar%」を追加します。
これで、順番の変数「NewVar」を使って、複数PDFファイルがあっても別のファイルに保存されるようになります。
設定したら「保存」をクリックします。
テキスト分割のための変数設定
今回想定しているのは「英語論文」です。
そのため文字数は結構多くなります。
文字数で分割し、それを翻訳ツールにコピー、翻訳する流れにします。
文字数で分割し保管するために新たな変数「NewVar2」を設定します。
アクションから「変数」→「変数の設定」をドラッグアンドドロップしてください。
変数の設定をクリックし、設定します。
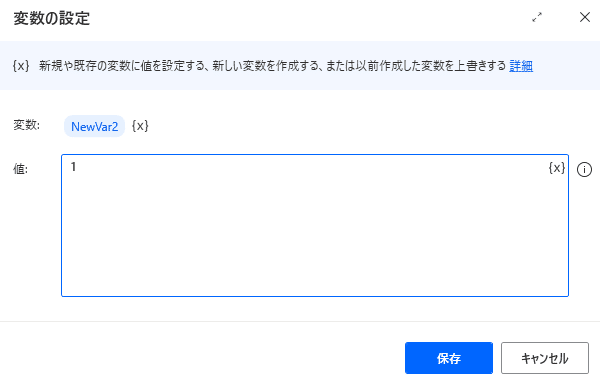
自動で「NewVar2」が入っているので、値をセットします。
値に「1」を入力し、保存を押します。
テキストの分割
アクションから「テキスト」→「テキストの分割」をドラッグアンドドロップしてください。
テキストの分割をクリックして、設定します。
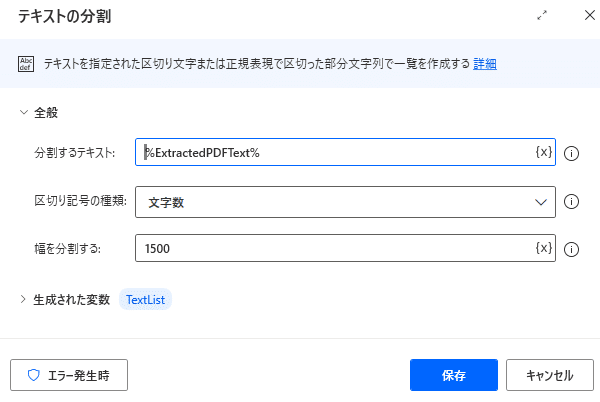
上の画面のように
分割するテキスト {x}でExtractedPDFText」を選択
区切り文字の種類 文字数
幅を分割する 1500
を入力し、「保存」をクリックします。
幅が設定の文字数です、任意に決めてください。
これでテキストが複数のテキストに分割されました。
各テキストを読み込んでは翻訳する流れを次から作っていきましょう。
分割テキストの読み込み
アクションから「ループ」→「For each」をドラッグアンドドロップしてください。
ドラッグアンドドロップした「For each」をクリックします。
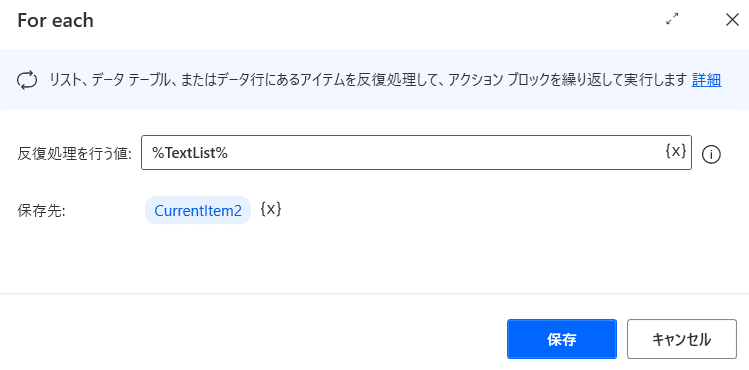
上のように、反復処理を行う値に「%TextList%」を、保存先はそのまま「CurrentItem2」を使います。
変数は{x}から選択して入力可能です。
これで分割したテキストを読み込む準備ができました。
次にブラウザーを立ち上げて、翻訳してきます。
Microsoft Edgeの起動
記事の通り、まずは守破離ということでEdgeでGoogle翻訳を起動します。
アクションの「ブラウザー自動化」→「新しいMicrosoft Edgeを起動」をドラッグアンドドロップしてください。
「新しいMicrosoft Edgeを起動」をクリックします。
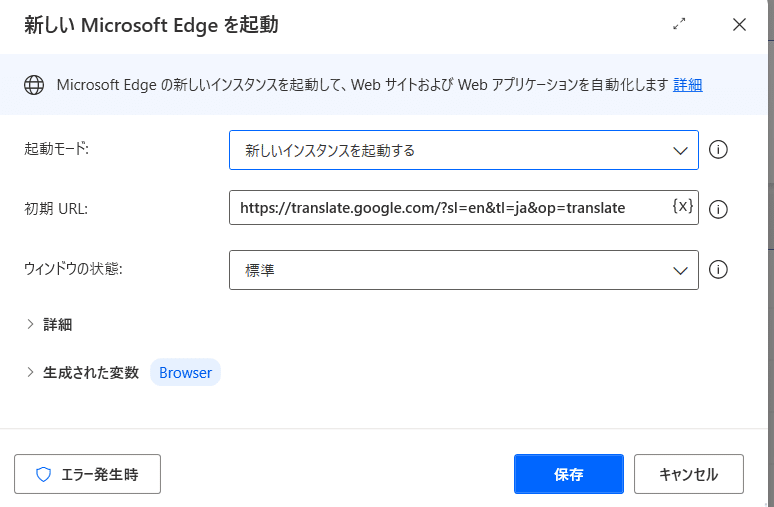
上のように設定していきます。
ちょっと面倒なのが初期URLの設定です。
以下の順番で行うと楽に設定できます。
別にEdgeを立ち上げてください。
Google翻訳を検索して表示します。
言語を元を英語、変換先を日本語にセットします。
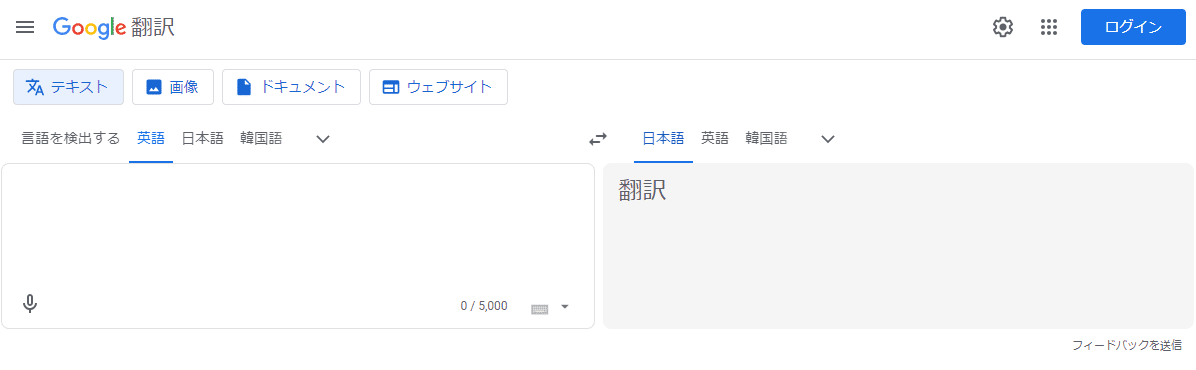
この画面にしてから、表示されているURLを選択してコピーします。
このコピーしたURLを初期URLにペーストしてください。
これで常に英語から日本語変換のページが選択できます。
起動モード 新しいインスタンスを起動する
ウィンドウの状態 標準
生成された変数 Browser(そのまま)
にします。
設定が終わったら「保存」をクリックしてください。
翻訳
Google翻訳の英語側にテキストをコピーペーストして翻訳を行います。
アクションから「ブラウザー自動化」→「Webフォームの入力」→「Webページ内のテキストフィールドに入力する」をドラッグアンドドロップしてください。
最初見つけられない場合があります。
その場合は、「Webフォーム入力」左の「>」をクリックしてみてください。
格納されているメニューが表示されます。
ではクリックして設定していきます。
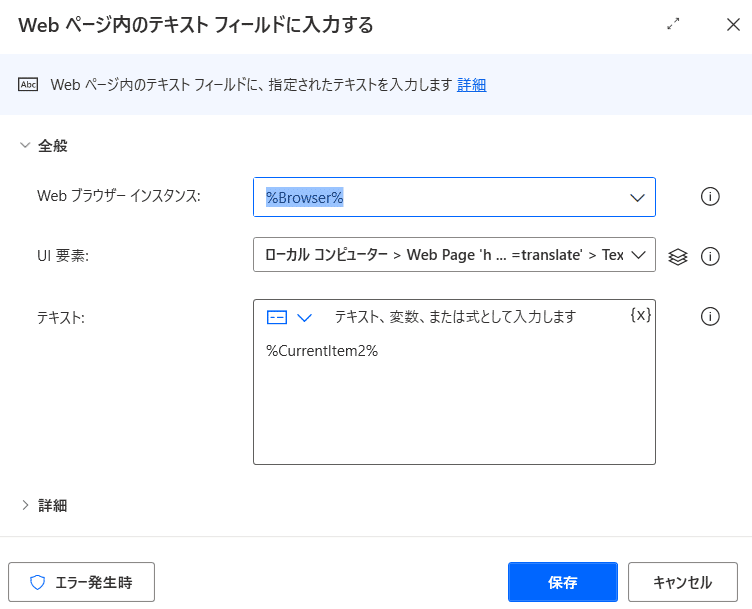
ここで面倒なのが、「UI要素」です。
まず画面UI要素ボックスの右側、下向きの山をクリックします。UI要素画面が表示され、ブラウザーのUIを選択できるようになります。

UI要素画面で、「UI要素の追加」をクリックしてください。
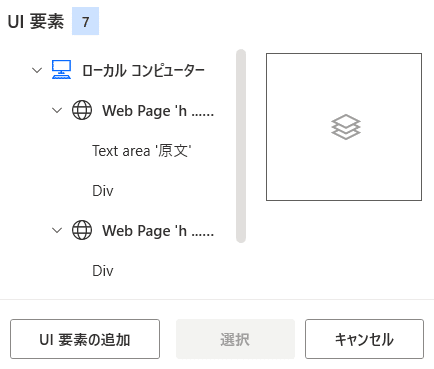
するとEdge画面に赤枠が表示されUI要素が選択できるようになります。
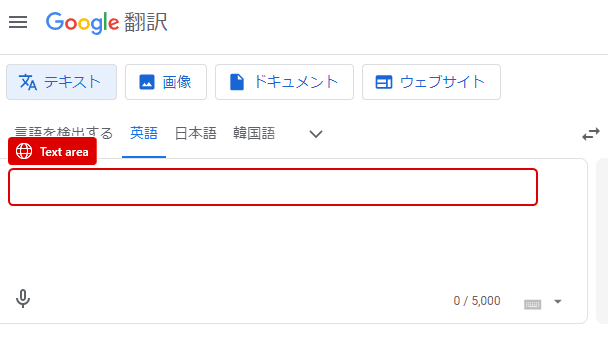
画面上のように、英語欄で「Text area」を表示されたら、キーボードの「CTRL」ボタンを押しながらマウスを左クリックします。
すると「Text area」がUI要素として設定されます。
「ブラウザーインスタンス」 %Browser%(選択)
「テキスト」 %CurrentItem2%(入力)
設定したら「保存」をクリックしてください。
これで自動的にテキストがコピーペーストされ、Google翻訳が自動的に翻訳してくれます。
翻訳された日本語をコピーする
起動しているEdgeのGoogle翻訳画面で、英語欄に適当な英語を入れてください。画面では「This is a pen」と入力しています。
すると日本語欄に、翻訳をコピーするボタンが現れます。
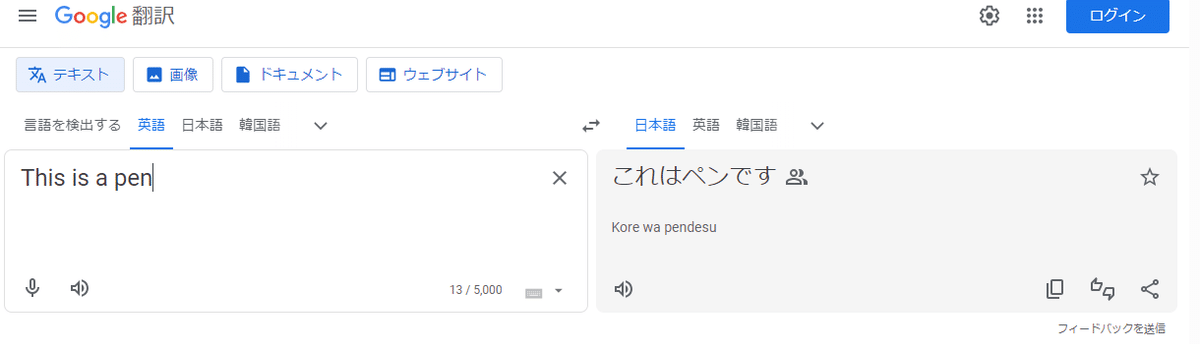
このコピーボタンをUI要素として翻訳をコピーします。
Powerautomate画面に戻り、アクション「ブラウザー自動化」→「Webページのリンクをクリック」をドラッグアンドドロップしてください。
UI要素からコピーボタンを選択していきます。
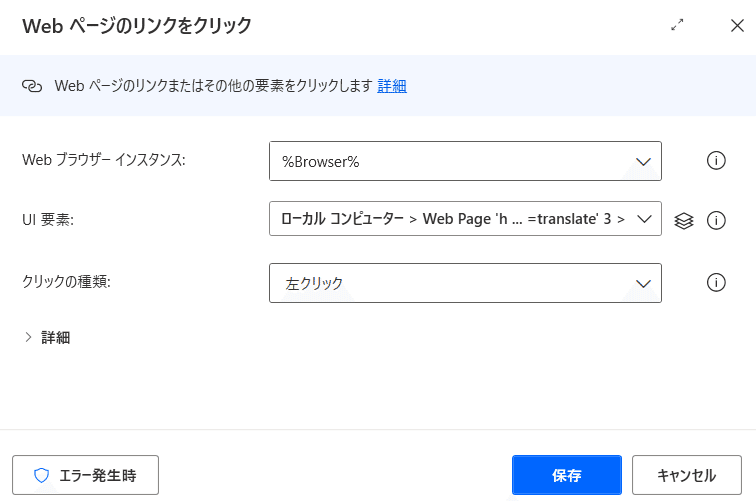
先ほど同様に、UI要素右の下山ボタンクリック、UI要素画面から「UI要素の追加」をクリックします。
Ege画面でUI要素が選択できる(赤枠が表示)ようになります。
では、コピーリングを選択しましょう。
下の画面のようになったら「キャプチャ」をクリックしてください。
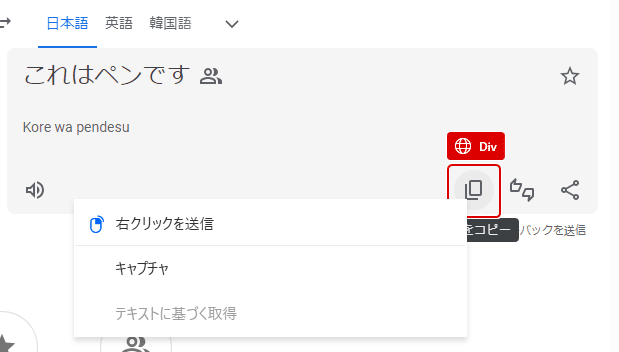
下のようにUI要素が追加されていればOKです。

残りを設定します。
「Webブラウザーインスタンス」 %Browser%(選択)
をセットして、「保存」をクリックします。
ここまでが山です。
コピーされたテキストを取得する
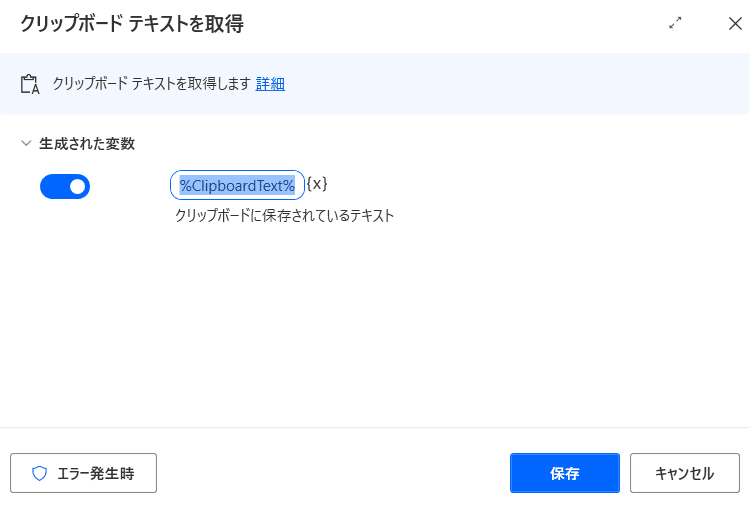
アクションから「クリップボード」→「クリップボードテキストを取得」をドラッグアンドドロップしてください。
ここは特に設定しなくてOKです。このまま保存します。
これでコピーされた翻訳をテキストとして変数 ClipboradText に格納します。
翻訳されたテキストをファイルに書きこむ
翻訳されたテキストを保存していきましょう
アクションから「ファイル」→「テキストをファイルに書き込む」をドラッグアンドドロップしてください。
「テキストをファイルに書き込む」をクリックして設定していきます。
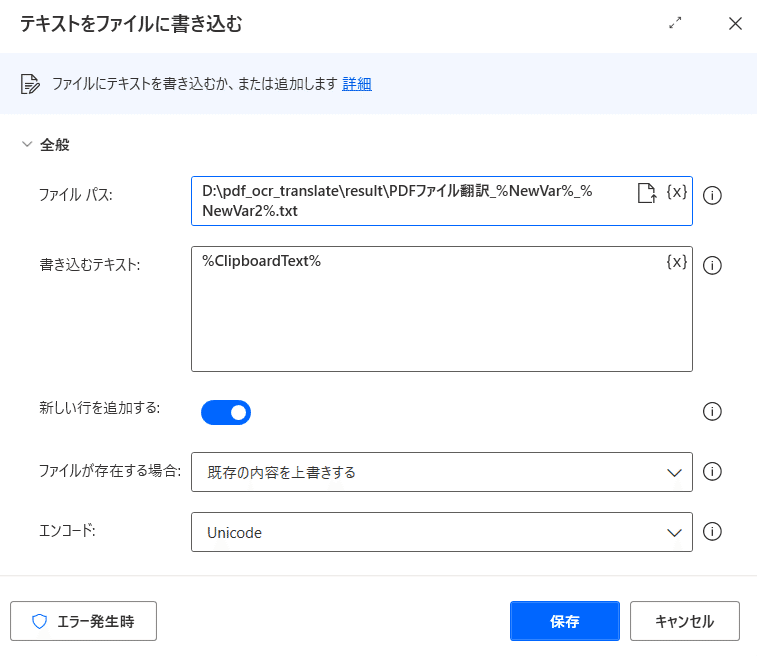
今回は PDFファイル翻訳‗PDFのNo‗テキストのNo.txt として保存していきます。
ファイルパスのファイルをクリックしてください。
保存先を指定し、PDFファイル翻訳.txt として「開く」をクリックしてください。
ファイルパスに「PDFファイル翻訳.txt」が表示されましたね。
では、翻訳のあとに、数値を追加していきます。
ファイルNo は NewVar 、テキストNoは NewVar2 です。
「_%NewVar%_%NewVar2%」と追加してください。
書き込むテキストは ClipboradText ですので選択してください。
設定が終わったら「保存」をクリックします。
Edgeを閉じる
自動的にEdgeを閉じます。そうしないと沢山のEdge画面が立ち上がったままになります。
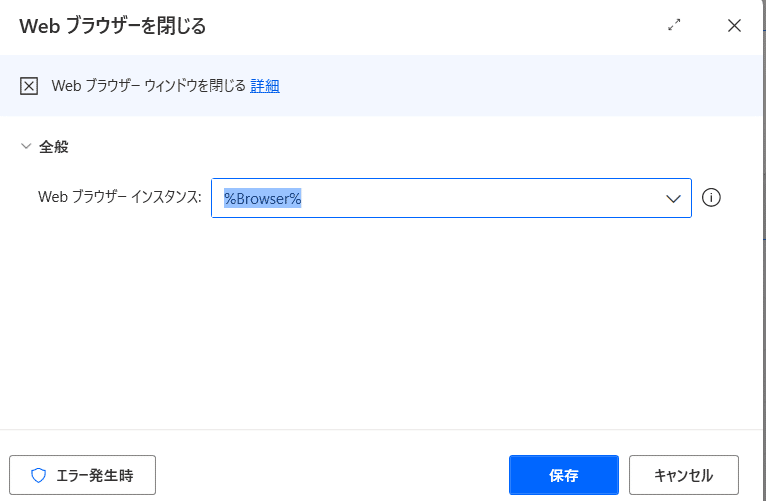
アクションの「ブラウザー自動化」→「Webブラウザーを閉じる」をドラッグアンドドロップしてください。
ここも特に設定の必要はありません。
Webブラウザーインスタンスが %Browser% となっていることを確認して「保存」をクリックします。
変数 NewVar2 を1つ大きくする
ループを回しますので、1ループが終わるごとに変数を1あげます。
アクションから「変数」→「変数を大きくする」をドラッグアンドドロップしてください。
「変数を大きくする」をクリックします。
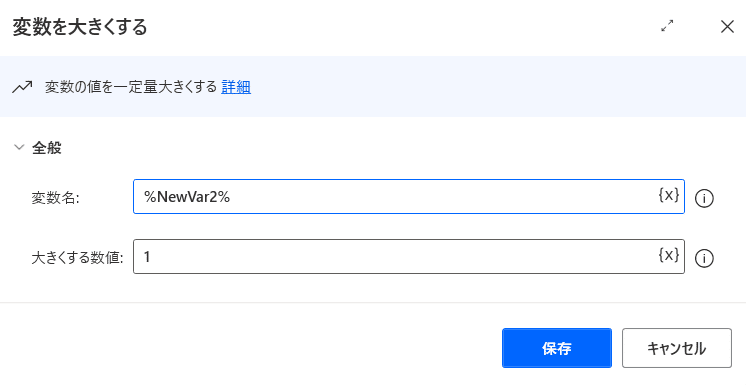
変数名 %NewVar2% (選択してください)
大きくする値 1 (入力してください)
としてください。
設定したら「保存」をクリックします。
変数 NewVar を大きくする
次はファイルの変数を大きくします。
これで次のファイルがファイルリストから読み込まれるようになります。
アクションから「変数」→「変数を大きくする」をドラッグアンドドロップしてください。
場所は下のようにします。
テキストのループ と ファイルのループ の間
End と End の間にドラッグアンドドロップしてください。
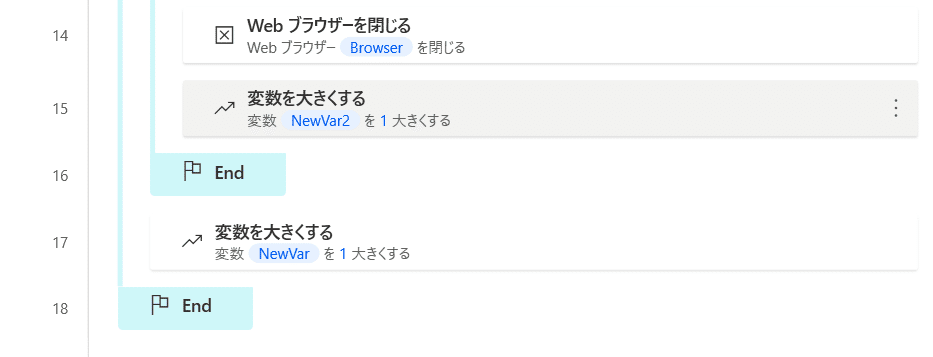
「変数を大きくする」をクリックします。
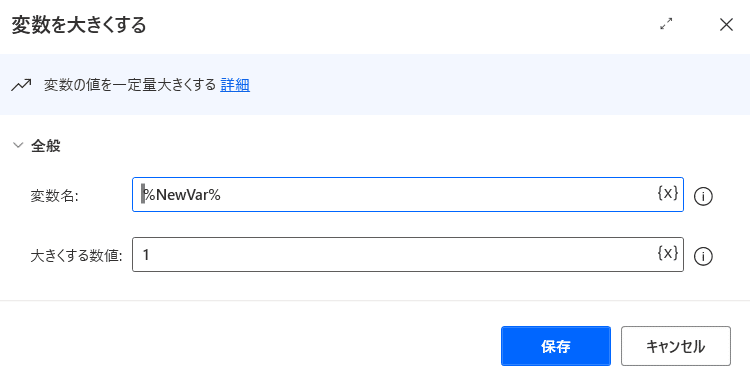
変数名 %NewVar% (選択してください)
大きくする値 1 (入力してください)
を設定します。
設定したら「保存」をクリックします。
これでフローの作成は完了です。
上から順番になっています。

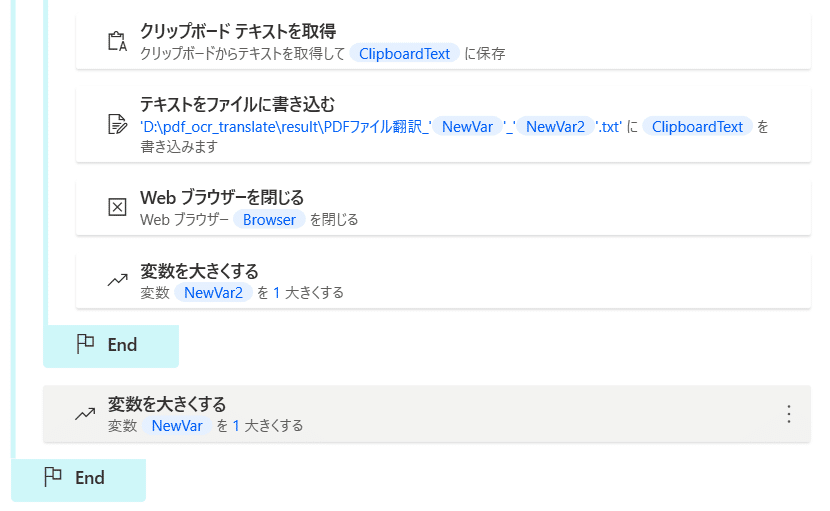
順番通りに進めていただくと、このようなフローになっていると思います。
フローをフロッピーアイコンで保存しておいてください。
お疲れ様でした。
実行してみる
では実行してみましょう。
data フォルダーに英語のPDFファイルを入れてみてください。
何個でもOKですが、まずは1つから
私は論文ファイルを入れてみました。
では実行ボタンをクリックしてください。
自動的にフローが実行されると思います。
完成していると下のようにかえってくると思います。
PDFファイル が 英語のテキスト
PDFファイル翻訳 が 各翻訳された日本語
となっています。
最後に
本当はもう少しブラッシュアップしたいところですが、まずは実行できました。
使ってみてください。
ブラッシュアップしたい点
テキストの分割方法 今は文字数ですが、章単位などにできるとうれしいですね。
要らない部分を削除する 参考文献とかヘッダー、フッターは削除したいですね。
図表の切り出し 論文などでしたら図表も別に保存したいところですね。
Powerautomateさわりはじめなので、今後勉強していきたいと思います。
ご意見、ご感想、こうしたほうが、などコメントいただけると嬉しいです。
この記事が気に入ったらサポートをしてみませんか?