
Python で基本統計量を計算する

独学で Python を勉強して機械学習をやってみようと取り組んでいます。そのために、統計学を勉強しています。本記事では統計とはどんなものか?から初め、統計学の基本的な計算である「基本統計量」の計算を Python でやってみます。
統計学はどんなものか?
統計学がどんなものか調べてみました。
統計学は収集したデータを最適な方法で活用して、未知のデータを推測したり、次の行動を決断するための根拠にしたり、将来の動きを予測したり、するようなデータや特徴を導くための学問であると思います。
現代の情報社会は様々なデータで溢れていますが、そのままでは役に立たなかったりします。そこで統計学を用いてデータの意味を表現することで、社会に役立つデータになります。しかし、適切でない統計計算を用いてしまうと、全く意味の違うものになってしまい、本質を捉えることができなくなってしまうので注意が必要です。
統計学を用いた簡単な例
統計学の計算で一般的によく知られているものとして「平均値」があります。簡単な例として、A組に生徒が3人、B組に生徒が3人いたとします。テストの平均点を導出し、それぞれの組で今後どのような方針で授業を進めていくか検討したいと考えています。
各組のテストの平均点を計算したところ、A組もB組も65点でした。しかし、細かく点数をみてみるとA組は「100点、90点、5点」で、B組は「70点、65点、60点」でした。この場合、A組とB組の状況は明らかに違いますが、平均点はどちらも65点なのです。
この場合、統計方法として「平均値」を導出するのが適切なのでしょうか?
実際には点数の拡がり度合なども見ないと、今後の授業の方針として適切な方法は取れないと思います。B組ならば平均点に見合った授業をすれば良さそうですが、A組でそれをやってしまうと高得点の2人にはもの足りなく、5点の人には難しすぎてしまうかもしれません。様々な統計方法がありますが、この場合は最大値と最小値の差である「範囲」も計算すればA組とB組の特徴がより明確になるでしょう。
まとめると、統計学は適切な計算をすれば物事の本質を捉えることができますが、不適切な計算をしてしまうと本質を捉えることができなくなってしまうので注意が必要なのです。
統計学の分類
統計学を代表的なもので分類すると以下の3種類に分けられます。
統計学の分類
・記述統計学
・推測統計学
・ベイズ統計学
記述統計学
分かりにくいデータを、分かりやすいデータに変換して表現するのが記述統計です。収集したデータの特徴を、平均や分散、標準偏差などから求めます。
推測統計学
限られたデータから調査したい母集団全体の特徴を推測するのが推測統計です。収集したデータの特長を、サンプルデータをもとに推測します。例えば国民1万人のアンケート結果から、国民全体1億人の動向を推測します。
ベイズ統計学
ベイズ統計学は記述統計学や推測統計学と比べ、少し毛色が違います。記述統計学はデータの特徴をわかりやすく表します。推計統計学は限られたデータを分析して母集団全体を推測します。しかし、ベイズ統計学は必ずしも標本となるデータを必要とせず、データ不十分でも何とかして確率を導きます。
基本統計量
データの特徴を1つの数値に要約して示したものを統計量といいます。そして、統計分析における基礎的な数値を基本統計量といいます。以下に主な基本統計量を示します。以降では、Pythonで計算しながらそれぞれがどんな値なのか示していきます。
基本統計量
■分布の中心を示す
・平均値
・中央値
・最頻値
■分布の拡がりを示す
・範囲
・平方和
・分散
・不偏分散
・標準偏差
■分散の形を示す
・歪度
・尖度
平均値
一般に平均といえば相加平均(算術平均)のことを指し、「データの合計÷データの数」で求めます。数式にすると次式になります。
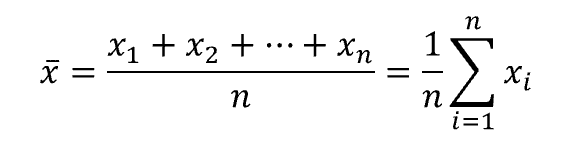
平均値には「相加平均(算術平均)」「相乗平均(幾何平均)」「調和平均」の3種類あり、それぞれの数式は次式になる。相乗平均は物価の上昇率など、率の平均を求めるような場合に使用される。調和平均はランニングコースなどを周回したときの平均速度を求める場合などに使われる。
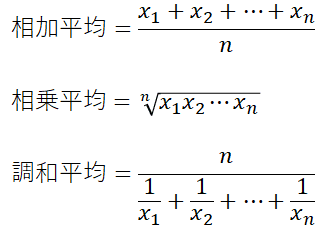
Pythonでは平均値(相加平均)を次のように計算できます。
# 平均値
data = [10, 20, 50, 60, 90]
total = sum(data)
num = len(data)
mean = total/num
print(mean)上記の例では次のような結果になります。
46.0また、Pythonの標準ライブラリである「statistics」を使うと平均値(相加平均)は次のように計算することもできます。
import statistics
# 平均値
data = [10, 20, 50, 60, 90]
mean = statistics.mean(data)
print(mean)結果は次のようになります。
46中央値
全データを並べたときに真ん中にくる値です。例えば、5人のテストの点数を並べたときに、「10点、20点、50点、60点、90点」となった場合は50点が中央値になります。Pythonでは次のように計算できます。
import statistics
# 中央値
data = [10, 20, 50, 60, 90]
median = statistics.median(data)
print(median)結果は次のようになります。
50最頻値
全データの分布をみたときに、データが最も集中している(最も頻度の高い)値が最頻値になります。5人のテストの点数が、「10点、20点、20点、60点、90点」となった場合は20点が最頻値になります。Pythonでは次のように計算できます。
import statistics
# 最頻値
data = [10, 20, 20, 60, 90]
mode = statistics.mode(data)
print(mode)結果は次のようになります。
20範囲
最も単純に分布の広がりを示す統計量が範囲になります。単純にデータの最大値と最小値の差になります。つまり、「範囲=最大値 ‐ 最小値」となります。
分散(標本分散)
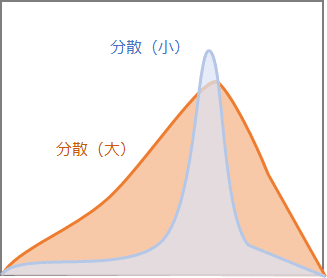
分散はデータのばらつき具合を示す値です。分散は各データの値と平均値の差分を 2 乗して合計し、データ数で割ります。このように平均値から離れた値のデータが多ければ多いほど、分散が大きくなります。つまり、それはデータの分布が拡がっているということを意味します。少々雑な図ですが、イメージは下図のようになります。
分散を数式で表すと次式になります。

また、分散の数式は次のように変形することもできます。

Pythonでは次のように計算できます。
# 平均値
data = [10, 20, 50, 60, 90]
total = sum(data)
num = len(data)
mean = total/num
# 分散
v = 0
for d in data:
v = v + ((d - mean)**2)/num
print(v)結果は次のようになります。
824.0また、「numpy」を使って次のように計算することもできます。
import numpy as np
# 分散
v = np.var(data)
print(v)結果は同様に以下の値となります。
824.0偏差
偏差は個々のデータを平均値の差です。つまり「個々のデータ - 平均値」で計算します。Pythonでは次のように計算できます。
# 平均値を計算する関数
def mean_calc(data):
s = sum(data)
n = len(data)
return s/n
# 入力データ
data = [10, 20, 50, 60, 90]
# 平均値を計算
mean = mean_calc(data)
# 偏差を計算
diff = []
for i in data:
diff.append(i - mean)
# 結果を出力
print(mean)
print(diff)結果は次のようになります。
46.0
[-36.0, -26.0, 4.0, 14.0, 44.0]標準偏差
標準偏差は、分散の平方根をとった値です。標準偏差を求める意味は、元データと単位を合わせた値にするためです。分散は計算過程でデータの値と平均値の差分を2乗します。2乗することで元データと単位が異なってしまうため、分散の平方根をとって標準偏差を導出することで元データと単位を揃えることができ、分散よりも扱いやすい値になります。
![]()
Pythonでは次のように計算できます。
import numpy as np
# 平均値を計算する関数
def mean_calc(data):
s = sum(data)
n = len(data)
return s/n
# 入力データ
data = [10, 20, 50, 60, 90]
# 平均値を計算
mean = mean_calc(data)
# 偏差を計算
diff = []
for i in data:
diff.append(i - mean)
# 分散
v = np.var(data)
# 標準偏差 (分散の正の平方根)
std = np.std(data)
print(std)結果は次のようになります。
28.705400188814647おわりに
本記事では、統計とはどんなものか?から初め、統計学の基本的な計算である「基本統計量」の計算を Python でやってみました。今後、機械学習を勉強していくうえでの基礎として身につけておきます。今まで統計って真面目に考えたことがなかったのですが、所感としては、「何をしたいか」の目的を明確にし、適切な統計計算を行うことが非常に重要であると感じました。また、Pythonで統計計算をするのはプログラムの書き方を覚えるだけでできますが、それよりも、その数式が何を意味しているのか理解することが重要だと感じました。今後も勉強しながら記事を書いていこうと思います。
以上
何かお役に立てたら、サポートしていただけると嬉しいです!モチベーションを高めて、アウトプットしていきます!