モバイルアプリエンジニアのためのTensorFlow 2.x 入門 (3) - 最小実装でモデルを作って学習させる

モバイルアプリエンジニアの方がTensorFlowに入門するための連載記事です。
今回はいよいよ機械学習のモデルを作ってトレーニングして推論までしてみます。
この入門は、Google Colaboratoryを使います。使い方は第1回にありますので、そちらをご覧下さい。
過去の記事はこちらからご覧下さい。
モデルを作る
まずは、最小実装でモデルを作ってみます。
0〜5の範囲の数字を入力すると、偶数か奇数かを判定するモデルです。
<モデルのイメージ>
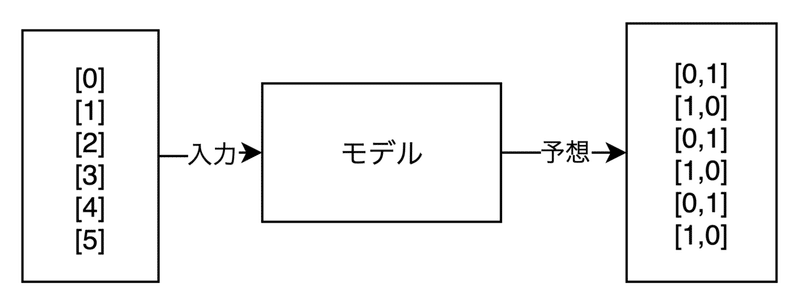
出力は、偶数=[0,1]、奇数=[1,0]となっています。これはOne-hot表現とよばれる表現方法です。
さっそくモデルを作ってみましょう。
# ライブラリのインポート
import tensorflow as tf
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
# 入力データは、0〜5の範囲の乱数を20個作る
# 例:[[1],[4],[0],[0]・・・・]
x_train = np.random.randint(0, 5, (20, 1))
# 教師データは、入力データから偶数 or 奇数を判定して作成する
# 例:[[1,0],[0,1],[0,1],[0,1]・・・・]
y_train = np.where( x_train%2 == 0, [0,1], [1,0])
# モデルを作成する
model = keras.Sequential()
# ユニット数512の全結合層で、活性化関数はrelu、入力の形はサイズ1の配列
model.add(layers.Dense(512,input_shape=(1,),activation='relu'))
# ユニット数256の全結合層で、活性化関数はrelu
model.add(layers.Dense(256,activation='relu'))
# ユニット数2の全結合層で、活性化関数はsoftmax
model.add(layers.Dense(2,activation='softmax'))
# モデルのコンパイル。最適化関数はadam、損失関数categorical_crossentropy、評価関数accuracyを指定
model.compile('adam', 'categorical_crossentropy', metrics=['accuracy'])
# モデルのトレーニング。訓練データ(x_train)、教師データ(y_train)を与え、学習の繰り返しは700回、バッチサイズは8、検証データの割合は0.2
model.fit(x_train, y_train, epochs=700, batch_size=8, validation_split=0.2)
Pythonの記法やnumpyの使い方については割愛しますがコメントを読めば分かるようになっています。
TensorFlowの部分について説明します。
まず、冒頭でKerasを読み込んでいます。
from tensorflow import kerasKerasは機械学習のフーレムワークで、もともとTensorFlowとは独立していましたが、現在はTensorFlowに統合されています。
現在も単独でKerasを使うことは出来ますが、今後はTensorFlow経由で使うことになりそうです。
このあたりの事情はこちらに詳しく書いてありました。
TensorFlowは様々な方法でモデルを作ることができますが、今回は一番簡単なKerasのSequentialモデルを使用しています。
# モデルを作成する
model = keras.Sequential()このSequentialモデルはとても簡単で、あとはDenseなどの全結合層をaddしていくだけでモデルを作ることができます。
# ユニット数512の全結合層で、活性化関数はrelu、入力次元は1
model.add(layers.Dense(512,input_shape=(1,),activation='relu'))
# ユニット数256の全結合層で、活性化関数はrelu
model.add(layers.Dense(256,activation='relu'))
# ユニット数2の全結合層で、活性化関数はsoftmax
model.add(layers.Dense(2,activation='softmax'))全結合層などニューラルネットについての説明は範囲外なので割愛しますが、他の教材で学習した概念との対応をつけやすいように、このモデルの図を描いてみました。
<モデルの全体図>
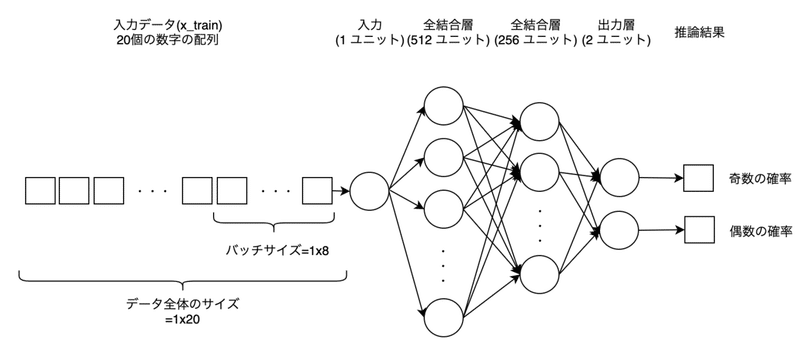
入力データ(x_train)から推論結果までデータのユニット数が描かれていますが、データの形状(shape)はハマりどころでもあるので詳しく説明します。
入力データは、0~5の数字が20個ならんだ配列でshapeは(20,1)になります。トレーニングでモデルに流し込む時はバッチサイズは8(訓練時のfitメソッドのbatch_sizeパラメータで指定)なので、20個の配列を8個ずつ切り出してモデルに流し込みます。shapeは(8,1)です。
モデルの入力はinput_shape=(1,)のところで指定しているように、値を1つだけ受け付けるようになっていますが、実際にはトレーニングのときにバッチサイズで指定した8個の配列をまとめて流し込むことができます。矛盾しているようにみえますが、モデルを作成するときには、バッチサイズを指定せずとも任意のサイズを受け付けるようになっているためです。shapeの表現としては(None, 1)となっており、Noneは任意の数を現します。
なお、ニュラールネットにバッチサイズ分のユニットを用意しているわけではありません。複数の入力値をまとめてモデルに与えて行列計算させ、それぞれの損失関数の値と勾配を計算したら、勾配の平均値を出して重みを1回だけ更新することで、効率的に学習をすることができます。これをミニバッチ学習といいいます。
入力を受け付けたあとはユニット数512の全結合層、256の全結合層を経由して、ユニット数2の出力層から活性化関数のsoftmaxにより推論結果が得られます。
このモデルの推論結果のshapeは(None, 2)です。Noneなのはバッチサイズに依存しているためです。例えば、モデルに[1,2,3,4]などのように4つの値を入力すれば4つの推論結果を返してくれます。
トレーニングのときはTensorFlowが教師データ(y_train)からバッチサイズ分を切り出して、推論結果と教師データを突き合わせて学習をしてくれます。
教師データは入力データと対応している必要があるので、shapeは(20, 2)で用意しておきます。
トレーニングと推論をする
トレーニングしてみましょう。
model.fit(x_train, y_train, epochs=700, batch_size=8, validation_split=0.2)
# 出力結果
# Epoch 1/700
1/1 [==============================] - 0s 138ms/step - loss: 0.6998 - accuracy: 0.3125 - val_loss: 0.7524 - val_accuracy: 0.2500
# Epoch 2/700
1/1 [==============================] - 0s 23ms/step - loss: 0.8142 - accuracy: 0.5625 - val_loss: 0.6879 - val_accuracy: 0.7500
# Epoch 3/700
1/1 [==============================] - 0s 20ms/step - loss: 0.6889 - accuracy: 0.6875 - val_loss: 0.6873 - val_accuracy: 0.2500
#
# 〜略〜
#
# Epoch 698/700
1/1 [==============================] - 0s 26ms/step - loss: 0.0568 - accuracy: 1.0000 - val_loss: 0.0474 - val_accuracy: 1.0000
# Epoch 699/700
1/1 [==============================] - 0s 24ms/step - loss: 0.0566 - accuracy: 1.0000 - val_loss: 0.0374 - val_accuracy: 1.0000
# Epoch 700/700
1/1 [==============================] - 0s 32ms/step - loss: 0.0590 - accuracy: 1.0000 - val_loss: 0.0540 - val_accuracy: 1.0000
# <tensorflow.python.keras.callbacks.History at 0x7f6bf09aca90>推論をしてみます。1を与えてみます。
# 推論を実行する。
model.predict([1])
# 出力結果
# array([[0.92613477, 0.07386521]], dtype=float32)推論結果として得られた確率が[0.92613477, 0.07386521]なので、奇数の確率が92%、偶数の確率が7%となっており、うまく推論出来ているようです。
モデルの入力は任意のバッチサイズで受け付けるので、複数の値をまとめて推論させることもできます。3と4をまとめて推論させてみます。
model.predict([3,4])
# 出力結果
# array([[0.7278953 , 0.2721047 ],
[0.10484059, 0.8951594 ]], dtype=float32)うまく推論できていますね。
最後に、若干宣伝ぽくて恐縮ですが、私はフリーランスエンジニアをしております。このような機械学習をiPhoneデバイス上で動作させるといったお仕事もできますので、お気軽にご相談下さい。
連絡先名:TokyoYoshida
連絡先: yoshidaforpublic@gmail.com
この記事が気に入ったらサポートをしてみませんか?