
Kerasで作った画像分類の機械学習モデルをCore ML Toolsを使ってiPhone上で動作させる

Kerasで作った画像分類のモデルをCore ML Toolsを使ってCore MLに変換し、iPhone上で動作させてみたので、その方法を説明します。
今回使用したモデルは、Kerasのサンプルにあった簡単なモデルです。
簡単なだけに、自分で層を変えたり、パラメータを変えたりしやすいので、Core ML Toolsの理解を深めるには最適だと思います。
なお、今回の完全なコードは下の場所にあります。Note Bookになっていますので、上からそのまま実行できます。
https://gist.github.com/TokyoYoshida/c6ded6ea17db0d223d5e97161db41ec1
また、今回は画像分類ですが、さらに簡易的なモデルの変換をこちらに書いていますので、参考にご覧ください。
作るもの
最終的な見た目はこんな仕上がりになります。

猫の映像をみて、98%の確率で猫であると言っています。
0.38%の確率で船にも見えるようです🚢
モデルの概要はこんな感じです。
<モデル概要図>
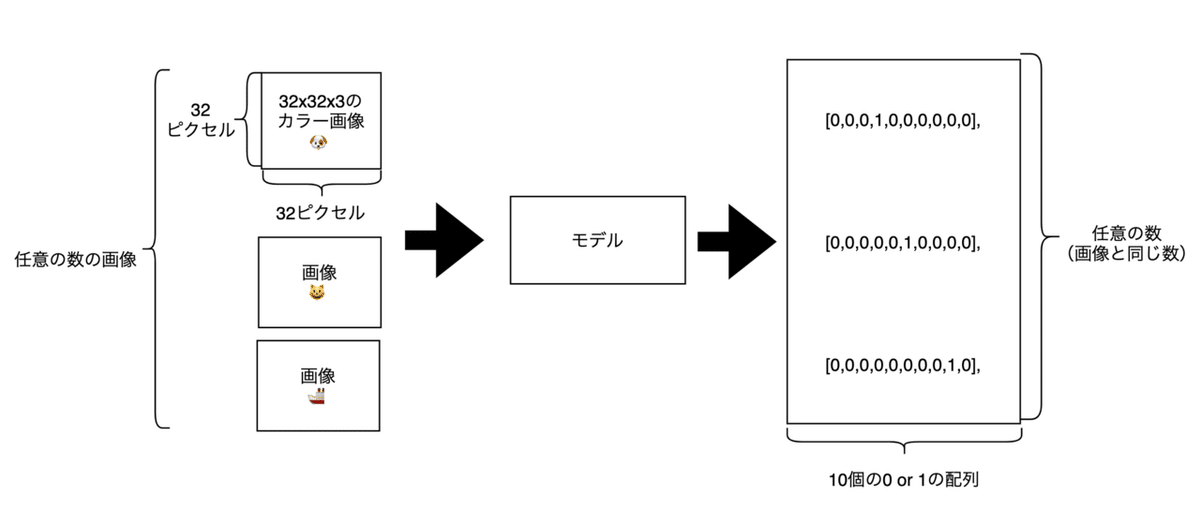
入力データとしては32ピクセルx32ピクセルx3(RGB)の画像を任意の数用意し、教師データとしてはそれぞれの画像の答えとして猫や犬、船といった情報を0 or 1で表現した10個の配列を画像の数だけ用意します。
データセットは、CIFAR-10という既存のものを使用しています。
これをモデルに与えて訓練することで、画像を分類できるようにします。
手順
Google Colaboratoryで作っていきます。
1. Google Colaboratoryに接続し、ノートブックを作成する
こちらからColaboratoryにアクセスします。
ファイルメニューからノートブックを新規作成します。
2. 必要なモジュールをインストール & インポートする
Colaboratoryの中に書いていきます。
まずは、インストールです。
!pip install tensorflow-gpu==1.14.0
!pip install -U coremltools
!pip install keras==2.2.4tensorflowはgpu版を選択しています。今回は学習に時間がかかるのでcpu版だと厳しいです。
手元で試したところ、gpu版はcpu版の10倍以上の速度でした。
GPUが使える状態にあるか確認してみます。
import tensorflow as tf
tf.test.gpu_device_name()
> /device:GPU:0/device:GPU:0などと出力されたらGPUが使える状態にあります。
次に、必要なモジュールをインポートします。
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras import layers
from keras import backend as K
from keras.utils import np_utils
import keras
import numpy as np
import math3.訓練データの読み込みと正規化
CIFAR-10のデータを読み込みます。
from keras.datasets import cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
num_classes = 10画像を正規化します。
これをしておかないとほとんど学習してくれません。
# 正規化
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255.0
x_test /= 255.0なお、kerasには画像を正規化する便利な関数が用意されていますが、今回はモデルへの入力を自分で掌握したいので、自前で処理を書きます。
いったんデータを表示させてみます。
import matplotlib.pyplot as plt
cifar10_labels = [
'airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck'
]
for index, img in enumerate(x_train[:30]):
plt.subplot(3, 10, index + 1)
plt.imshow(img)
plt.axis('off')
plt.title(cifar10_labels[y_train[index][0]])
plt.tight_layout()
plt.show()こんな感じで表示されます。

4.入力データと教師データを準備する
まずは、教師データを0 or 1のデータ(One-hot表現といいます)に変換します。
y_train = np_utils.to_categorical(y_train, num_classes)
y_test = np_utils.to_categorical(y_test, num_classes)次に入力データを準備します。
KerasのImageDataGeneratorを使います。これを使うと、イメージを回転させたり、横に移動させたり、反転させたりして画像を水増しすることができます。
train_datagen = ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(
featurewise_center=False,
featurewise_std_normalization=False,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True)
train_datagen.fit(x_train)
test_datagen.fit(x_test)featurewise_centerやfeaturewise_std_normalizationが正規化のためのパラメータですが、今回は使わないのでFalseを設定しています。
5.モデルを作成する
モデルの作成に入ります。
モデルは、こちらにあるサンプルとほぼ同じものになります。
畳み込み層とプーリング層を重ねて最後に全結合層を通して活性化関数としてsoftmaxを使用して各ラベルの確率を出しています。
なお、モデルの作成の前にコールバックの設定をしていますが、コメントに説明がありますので割愛します。
interrupt_save_path = 'bk_model.h5'
img_width, img_height = 32, 32
epochs = 1
batch_size = 32
if K.image_data_format() == 'channels_first':
input_shape = (3, img_width, img_height)
else:
input_shape = (img_width, img_height, 3)
def make_model(input_shape, num_classes):
inputs = keras.Input(shape=input_shape)
# Image augmentation block
x = inputs
# Entry block
x = layers.Conv2D(32, 3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
for size in [128, 256, 512, 728]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(size, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
x = layers.SeparableConv2D(1024, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
if num_classes == 2:
activation = "sigmoid"
units = 1
else:
activation = "softmax"
units = num_classes
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(units, activation=activation)(x)
return keras.Model(inputs, outputs)
model = make_model(input_shape=input_shape, num_classes=num_classes)次にモデルをコンパイルして訓練をします。
また、tryとexceptでKeyboardInterrupt例外を拾っています。これは、途中で訓練をやめたくなった時でも、訓練したところまでのモデルを保存するためのものです。
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
try:
model.fit_generator(
train_datagen.flow(x_train, y_train, batch_size=32),
steps_per_epoch=len(x_train) / batch_size , epochs=epochs,
validation_data=test_datagen.flow(x_test, y_test, batch_size=32),
validation_steps=len(x_test) / batch_size,
callbacks=[early_stopping, tansorboard_cb, checkpoint]
)
except KeyboardInterrupt:
model.save(interrupt_save_path)
print('Output saved to: "{}./*"'.format(interrupt_save_path))
6.TensorBoardでモデルの情報を確認する
TensorBoardを呼び出します。
# TensorBoardの有効化
%load_ext tensorboard
# なぜかアンインストールしないとエラーが出るのでアンインストールしておく
!pip uninstall tensorboard-plugin-wit
# TensorBoardの起動
%tensorboard --logdir ./logs訓練の状況は省略します。
モデルを見てみます。だいぶ大きなモデルなので、入力(一番下のあたり)と出力(一番上のあたり)を見ていきます。
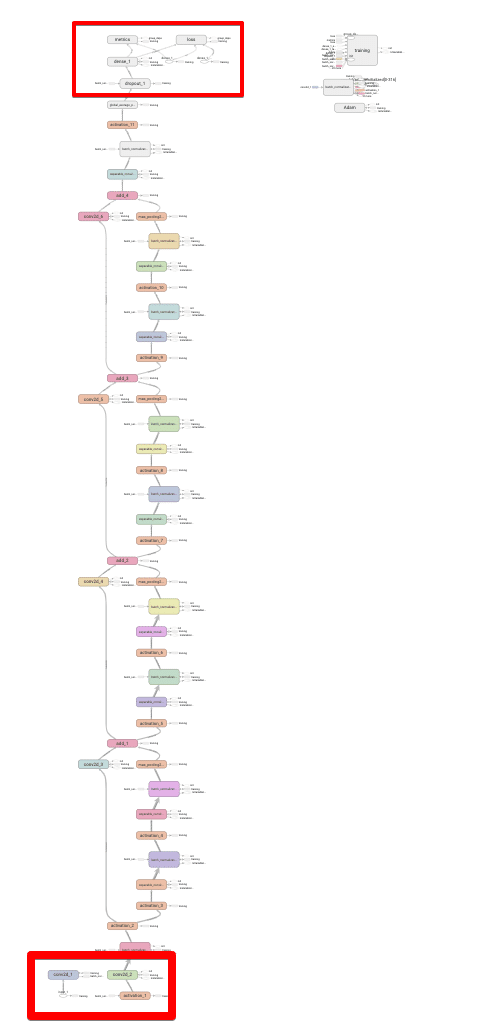
入力部分を見ていきます。input_1とあるところが入力部分です。
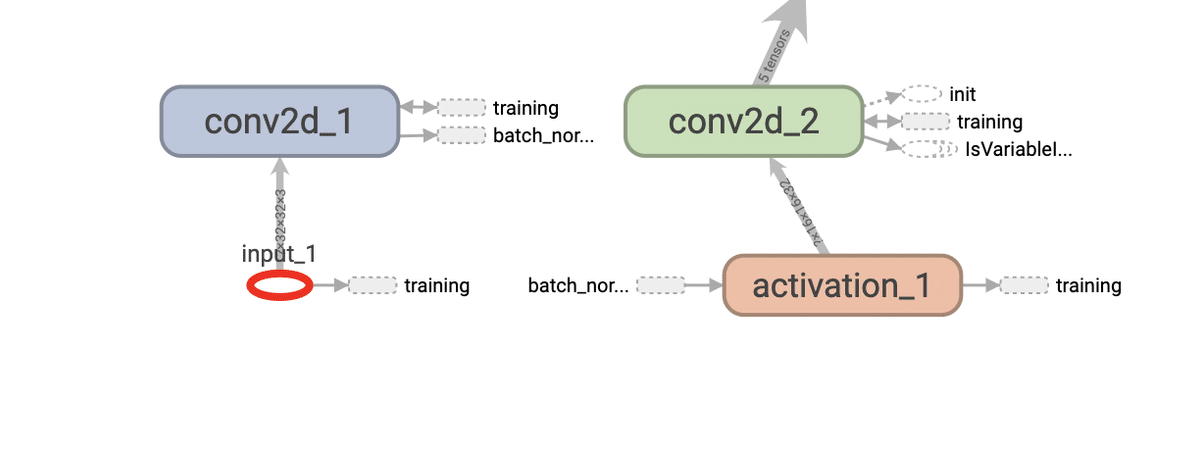
input_1の詳細はこのようになっています。

typeはDT_FLOATで、shapeは、{-1, 32, 32, 3}となっています。
-1は任意の数です。
なので、shepeは次のような形になっていることがわかります。
任意の数✕幅32ピクセル✕高さ32ピクセル✕色3チャンネル(R、G、B)
となっていることがわかります。これは上に書いた<モデル概要図>と一致しています。
次に出力側を見てみます。dense_1が出力部分です。
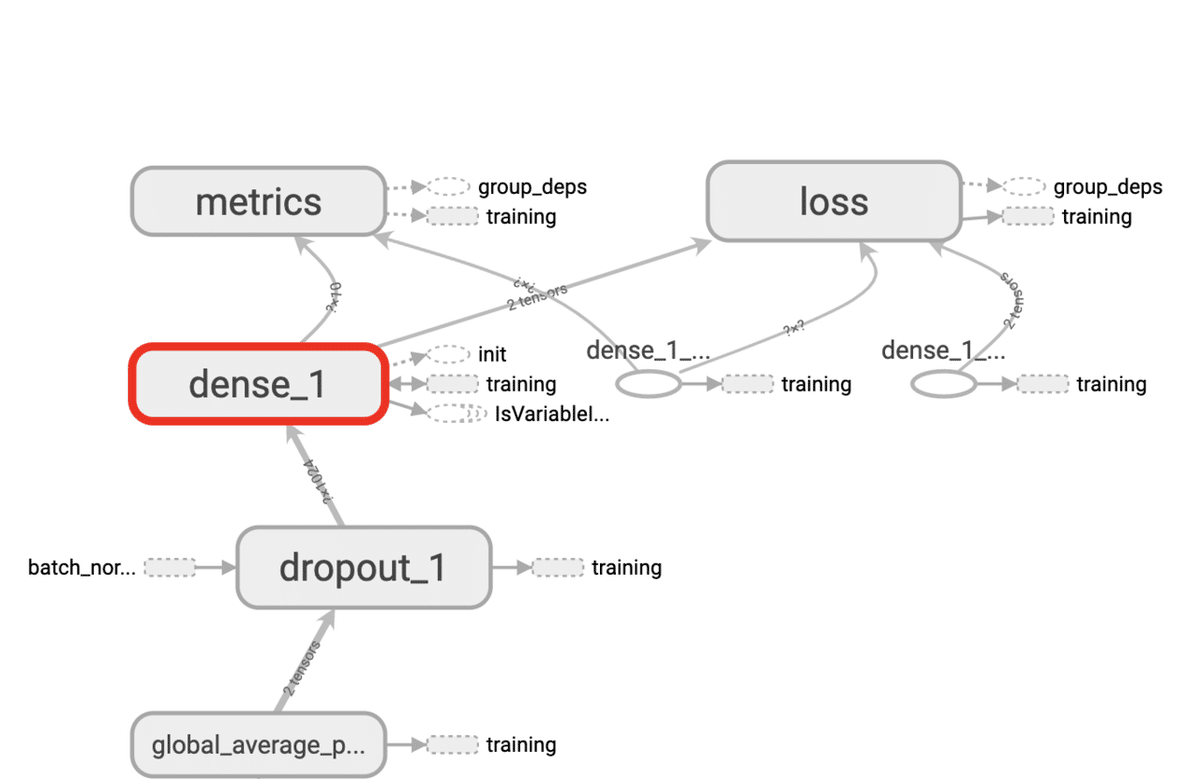
dense_1の詳細はこのようになっています。
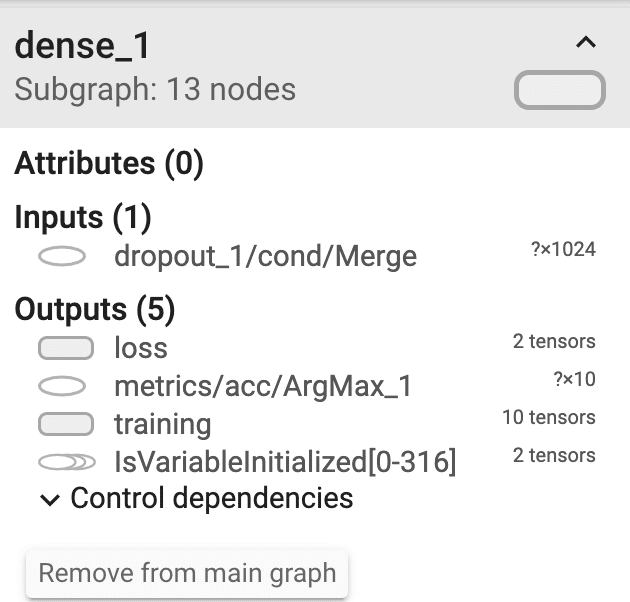
metricsに出力しているのが、実際の確率情報です。(metricsはモデルの評価関数です)
shapeは、?✕10となっているため、任意の数✕10種類のラベルとなっていることがわかります。これも<モデル概要図>と一致しています。
7.Colaboratory上で予想してみる
iPhoneで動作させる前に、Colaboratoryで実際に予想してみます。
np.count_nonzero(np.argmax(model.predict(x_test),axis=1) - np.argmax(y_test, axis=1) == 0)/len(x_test)
> 0.83Epochを30回程度で訓練した場合、83%の正答率となっていました。もっと訓練をすれば正答率も上がりますが、時間がないのでこれくらいにします。
なお、あまりに正答率が低いとiPhone上で動作させたときに、モデルの質が悪いのか、変換に失敗しているのかの区別がつかなくなるので、それなりにモデルの質を上げておく必要があります。
8.Core ML ToolsでCore MLに変換する
Core MLに変換する前に、一旦モデルを保存します。(今回は訓練済のモデルがあるのでこの作業は不要ですが)
model.save('my_model.h5')次に、モデルを読み込んでサマリーを出します。
from keras.models import load_model
keras_model = load_model('my_model.h5')
keras_model.summary()
# 出力結果
# __________________________________________________________________________________________________
# Layer (type) Output Shape Param # Connected to
# ==================================================================================================
# input_1 (InputLayer) (None, 32, 32, 3) 0
# __________________________________________________________________________________________________
# conv2d_1 (Conv2D) (None, 16, 16, 32) 896 input_1[0][0]
# __________________________________________________________________________________________________
# 〜略〜
# __________________________________________________________________________________________________
# global_average_pooling2d_1 (Glo (None, 1024) 0 activation_11[0][0]
# __________________________________________________________________________________________________
# dropout_1 (Dropout) (None, 1024) 0 global_average_pooling2d_1[0][0]
# __________________________________________________________________________________________________
# dense_1 (Dense) (None, 10) 10250 dropout_1[0][0]
# ==================================================================================================
# Total params: 2,791,874
# Trainable params: 2,783,138
# Non-trainable params: 8,736上から入力層(input_1)が始まり、最後に出力層(dense_1)があり、shapeも先程TensorBoardで見たものと同じになっています。
Core MLに変換します。これが本稿で一番重要な部分です。
from coremltools.converters import keras as converter
class_labels = cifar10_labels # 最初の方で設定した識別用のLabelを指定する
# Core MLに変換する
mlmodel = converter.convert(keras_model, # 今回作成したモデル
output_names=['cifarProbabilities'], # 予想の出力に名前をつける。swiftから変数名としてアクセスできるようになる
class_labels=class_labels, # 予想結果の分類ラベル
predicted_feature_name='cifarName', # 分類の出力に名前をつける。swiftから変数名としてアクセスできるようになる
input_names=['input_1'], # 入力層に名前をつける
image_input_names='input_1', # 入力層のうち、画像の入力を指定する
image_scale=1/255.0, # 画像を正規化する
use_float_arraytype=True, # doubleではなくfloatとして扱うようにする
)
# 保存する
coreml_model_path = 'my_model.mlmodel'
mlmodel.save(coreml_model_path)ポイントは2つあります。
Core ML Toolsの引数のポイントその1
1つは、input_names=['input_1']で入力層に名前をつけ、image_input_names='input_1'で入力層のうち、画像の入力にあたるものを指定しているところです。
この指定がないと、iOSのプロジェクト側では入力は画像ではなくMulti Arrayとして扱われてしまいます。VisionFrameworkを使用する場合、入力は画像の形にする必要があるので、この指定を入れます。
なお、image_input_namesはinput_namesのサブセットである必要があるため、input_namesで予め['input_1']を指定しています。
今回、この部分がなかなかうまく行かず、苦労しました。
Core ML Toolsには、NeuralNetworkBuilderというものがあり入力層を画像にするようなこともできるのですが、この方法では何故かうまくいきませんでした。コメントに残しているので、原因が分かる方は教えていただけると幸いです。
うまくいったかどうかは、次のようにNeuralNetworkBuilderを利用して入力層の情報を確認することでわかります。
import coremltools
spec = coremltools.utils.load_spec(coreml_model_path)
builder = coremltools.models.neural_network.NeuralNetworkBuilder(spec=spec)
builder.inspect_input_features()
# 出力結果
# [Id: 0] Name: input_1
# Type: imageType {
# width: 32
# height: 32
# colorSpace: RGB
#}colorSpaceがRGBになっているので、うまく設定できています。(うまくできていないときはここがMultiArrayとなる)
Core ML Toolsの引数のポイントその2
ポイントその2は、画像を正規化するために、image_scale=1/255.0としているところです。これは、冒頭部分で、画像のデータを1/255していることに対応しています。
# 正規化(再掲)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255.0
x_test /= 255.0このようにしないと、Core MLで推論するときに正しく推論できません。
9.モデルをダウンロードしてXcodeに読み込む
Colaboratoryからモデルのデータ(.mlmodelファイル)をダウンロードします。

Xcodeのプロジェクトへの読み込みは、こちらのプロジェクトを使用します。Core MLのモデルをDrag & Dropするだけで、カメラからいい感じに推論してくれる便利なプロジェクトです。
プロジェクトをcloneしてXcodeに読み込んだら、modelsフォルダの下に、ダウンロードしたCore MLのモデル(.mlmodelファイル)をDrag & Dropします。
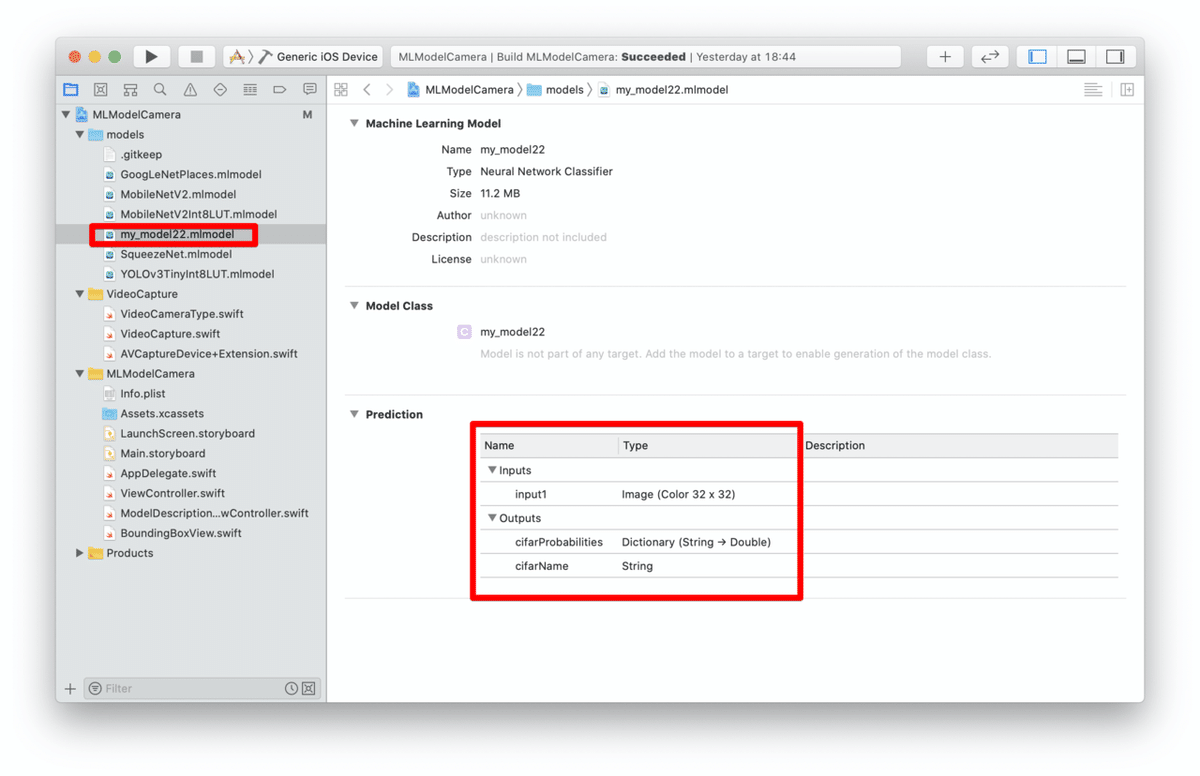
うまく読み込めていたら、Predictionの欄にモデルの入出力の情報が載ります。
input1は入力で、32✕32のカラーのImageになっています。
OutputsのcifarProbabilitiesはDictionary(String →Double)で、各ラベルごとの確率情報を、cifarNameが分類されたラベルの名前が入ります。
10.実行する
実行すると、仕上がりのところで紹介したような推論が始まります。
最後に、若干宣伝ぽくて恐縮ですが、私はフリーランスエンジニアをしております。このような機械学習をiPhoneデバイス上で動作させるといったお仕事もできますので、お気軽にご相談下さい。
連絡先名:TokyoYoshida
連絡先: yoshidaforpublic@gmail.com
この記事が気に入ったらサポートをしてみませんか?