
Hugging Face 小さいモデルでパフォーマンスを大幅に向上した、画像と言語を融合した新時代のAI「Idefics2」をリリース

Hugging Face社は、テキストと画像の任意のシーケンスを入力として受け取り、テキストレスポンスを生成する汎用マルチモーダルモデル「Idefics2」をリリースしました。このモデルは、画像に関する質問に答えたり、視覚コンテンツを記述したり、複数の画像に基づいたストーリーを作成したり、文書から情報を抽出したり、基本的な算術演算を行うことができます。
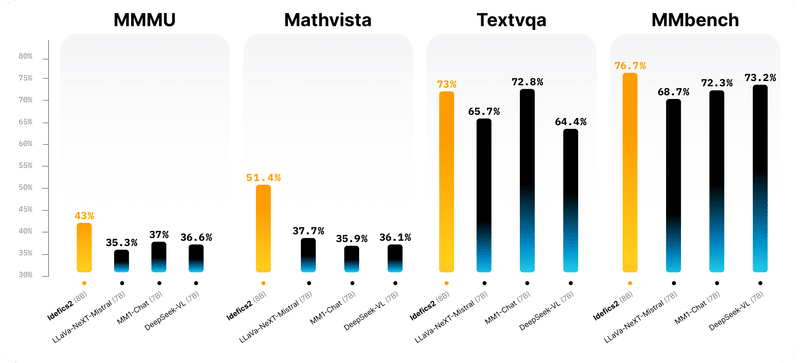
Idefics2は、8B(80億)のパラメーター、オープンライセンス(Apache 2.0)、および強化されたOCR(光学文字認識)機能を備え、マルチモーダリティに取り組むコミュニティのための強固な基盤を提供します。視覚的質問応答ベンチマークにおいては、そのクラスサイズのトップであり、LLava-Next-34BやMM1-30B-chatなどのはるかに大きなモデルと競合します。
また、Idefics2はTransformersに統合されており、多くのマルチモーダルアプリケーションに対して簡単にファインチューニングが可能です。モデルはすぐにHubで試すことができます。
Idefics2は、WikipediaやOBELICSなどのウェブドキュメント、Public Multimodal DatasetやLAION-COCOなどの画像キャプションペア、PDFA、IDLおよびRendered-text、WebSightなどの画像からコードへのデータなど、公開されているデータセットの混合物で事前トレーニングされています。OBELICSデータセットのインタラクティブな可視化により、データセットを探索することができます。
Idefics1と比較して、Idefics2は画像をそのネイティブ解像度(最大980 x 980)とネイティブアスペクト比で操作し、NaViT戦略に従っています。これにより、コンピュータビジョンコミュニティで歴史的に行われてきた固定サイズの正方形に画像をリサイズする必要がなくなります。さらに、SPHINXの戦略に従い、非常に高解像度の画像を分割して渡すことも可能です。
OCR能力も大幅に強化され、画像や文書内のテキストを転写することを要求するデータを統合しました。また、適切なトレーニングデータを用いて、チャート、図表、文書に関する質問に答える能力も向上しています。
Idefics1のアーキテクチャ(ゲート付きクロスアテンション)から離れ、視覚機能を言語バックボーンに統合するプロセスを簡素化しました。画像はビジョンエンコーダに供給され、学習されたPerceiverプーリングとMLPモダリティプロジェクションに続きます。そのプールされたシーケンスは、テキストの埋め込みと連結され、画像とテキストの(交互の)シーケンスを取得します。
これらの改善により、Idefics1と比較して、10倍小さいモデルであるにもかかわらず、パフォーマンスが大幅に向上しました。
詳細内容は、Hugging Faceが提供する元記事を参照してください。
【引用元】
【読み上げ】
VOICEVOX 四国めたん/No.7
この記事が気に入ったらサポートをしてみませんか?