
OpenAI GPT-4の内部表現を1600万個の解釈可能なパターンに分解し概念を抽出

AI技術の急速な進展にも関わらず、ニューラルネットワークの内部構造を理解するのは依然として困難です。特に、自然言語処理モデルのような複雑なAIシステムでは、内部のニューロン活動がどのように意味を持つのかを解明するのは難しい課題となっています。これに対し、OpenAIはGPT-4の内部表現を分解し、人間にとって理解しやすいパターンを特定する新しい手法を開発しました。今回、1600万個もの特徴を検出し、これに基づく研究を公開しました。
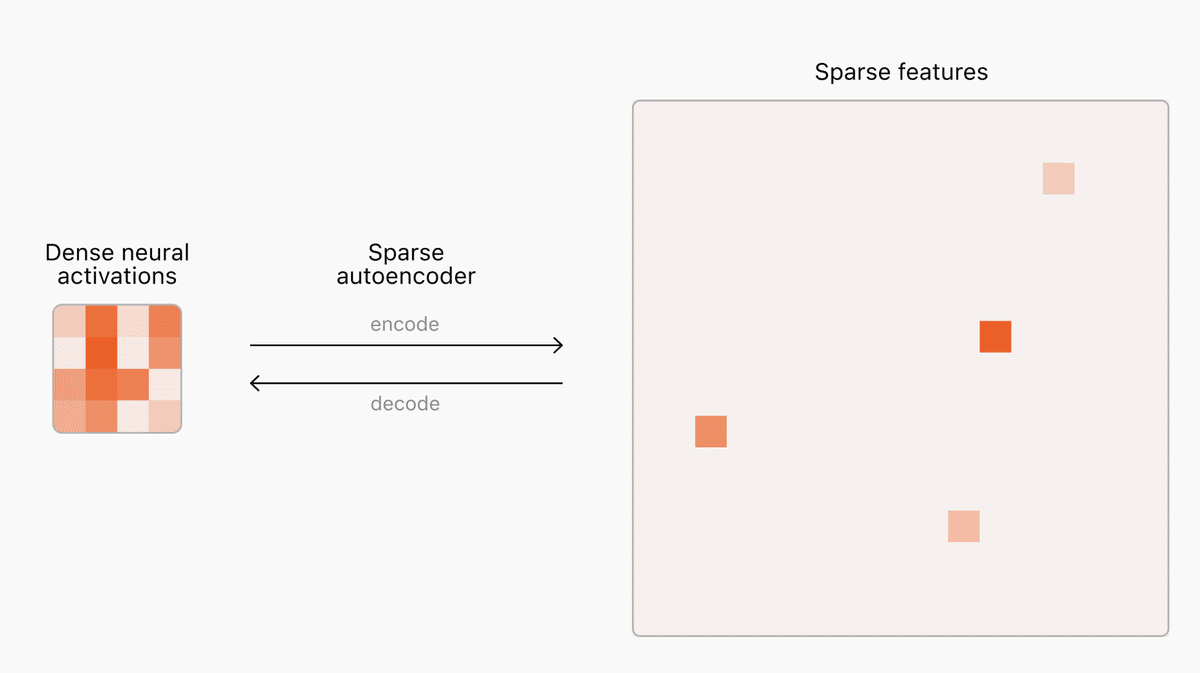
従来のエンジニアリングでは、例えば自動車のような製品はその部品ごとに設計、評価、修正が可能で、予測可能な動作をします。しかし、ニューラルネットワークの場合、その設計はアルゴリズムを通じて間接的に行われるため、得られたネットワークの内部構造は理解しにくく、分解して理解することが困難です。このため、AIの安全性を確保するためのアプローチも自動車の安全性を確保する方法とは異なります。
ニューラルネットワークの理解には、まず有用な計算の構成要素を見つける必要があります。言語モデル内部のニューロン活動は予測不能なパターンで活性化し、同時に多くの概念を表現しますが、現実の概念は文脈によって非常に少数のものしか関与しません。この問題に対処するために、OpenAIはスパースオートエンコーダーを用いました。これにより、モデル内の少数の重要な「特徴」を識別し、これらの特徴は人間にとっても理解しやすい形で概念に対応します。
OpenAIは、スパースオートエンコーダーを数千万の特徴にスケールさせる新しい手法を開発しました。この手法により、以前の技術よりもスムーズかつ予測可能にスケールが可能となり、GPT-4の1600万特徴オートエンコーダーの訓練に成功しました。これにより、各特徴を可視化し、特定の文書やフレーズに対する特徴の活性化を確認することができます。
例えば、GPT-4において「人や物事が欠陥を持つ」という特徴や、「価格の上昇に関連するフレーズの終わり」などの具体的な特徴が特定されました。
スパースオートエンコーダーは興味深い進展を示していますが、まだ初期段階であり、多くの課題が残っています。発見された特徴の多くは依然として解釈が難しく、概念に一致しない活性化や、妥当性を確認するための効果的な方法が不足しています。また、オートエンコーダーは元のモデルの全ての動作を捉えているわけではなく、モデルの行動を完全に把握するにはさらなるスケーリングが必要です。
OpenAIは、これらの課題に取り組むために研究コミュニティと協力し、スパースオートエンコーダーの訓練を支援するための論文、コード、および特徴可視化ツールを公開しています。最終的には、モデルの安全性や信頼性に関する新たな洞察を提供し、AIモデルの行動に対する強固な保証を与えることを目指しています。
OpenAIの研究は、AI技術の理解と制御に向けた大きな一歩となり、今後の進展に期待が寄せられます。
詳細内容は、OpenAIが提供する元記事を参照してください。
【引用元】
https://openai.com/index/extracting-concepts-from-gpt-4/
【読み上げ】
VOICEVOX 四国めたん/No.7
この記事が気に入ったらサポートをしてみませんか?