
大量にあるヘルプページの記事をZendesk API+GAS+Textlint(Python)を使って一括でトンマナ校正を頑張る

この記事では、Zendeskのヘルプページ情報の取得と表記ゆれチェックを一括で行うために頑張る話です。アドホックな用途で、しかも一発限定モノではありますが、このアイデアが、ざっくり誰かの役に立てば幸いです。
困っていること

細かいトンマナを修正したいと思っているけれど、ヘルプページの記事数もそれなりに増えていてちょっと気が重い。さらに、後で修正したトンマナが不適切だと感じることが度々あります(個人の問題だけど)。再度修正することになるのではないか(自己正当化ムーブ)と、修正をしないまま、早1年が過ぎてしまいました。。。
Tech的なアプローチで、この自己正当化ムーブを打ち破れないかを検討して出来上がったものが今回の記事になります。
やりたいこと
ヘルプページのトンマナ校正を行うために各記事の表記ゆれを一括検出したい
Zendesk Guide上の複数の記事情報をAPI経由で一括で取得
取得した記事毎の「タイトル」と「本文」を `.md` 形式のファイルで保存
各ファイルに対して textlintを実行し、検知エラーを各ファイルへ追記
👇お忙しい方は実行結果へ👇
Zendesk Guideの記事を一括で取得
この作業に関して以下記事の「Zendesk GuideのArticle情報を取得(ヘルプページ)」で実施します。詳細は以下記事参照
textlintの設定
textlintとは何か?
今回のトンマナ校正の前提となるツールのtextlintです。詳細は以下参照。
textlintはMarkdownなどテキスト向けのLintツールで、テキスト版ESLintみたいな感じのツールです。
textlintのVscode拡張機能も存在します。ただし、Vscode拡張機能は、エディタ上の文章をリアルタイムにチェックする用途を主としており、今回の一括チェックには利用できない気がしました。
node.jsをインストール
textlintを利用するにはnode.jsをインストールしておく必要があります。
# WSL2のUbuntu環境
$ lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.6 LTS
Release: 20.04
Codename: focalそのままapt install nodejsするとバージョンが古いのでNodeSource経由で最新のLTSバージョンを指定します。
$ curl -fsSL https://deb.nodesource.com/setup_18.x | sudo -E bash -
$ sudo apt install nodejs -ytextlint + prhで辞書登録を行う
検出したい表記を登録します。
上記を参考にして、textlintとtextlint-rule-prhをインストールします。
$ npm install -g textlint textlint-rule-prhprh.ymlを作成して、`.textlintrc`というtextlintの設定ファイルに `prh.yml` へのファイルパスを指定します。
{
"rules": {
"prh": {
"rulePaths": [
"./prh.yml"
]
}
}
}`prh.yml` にトンマナを記載します。
version: 1
rules:
- expected: 申込み
pattern: 申し込み
- expected: お客さま
pattern: お客様
- expected: スクリーンショット
pattern: キャプチャ
- expected: スクリーンショット
pattern: 画面イメージ
- expected: ひとり
pattern: 一人
- expected: ひとり
pattern: 一名
- expected: 問い合わせ
pattern: 問合せ様々なルールを設定可能なようですが、今回は簡単な登録のみです。
適当にNGワードを含んだ文章を作成します。
# hoge.md
お客様からの問合せはこちらで対応いたします。
画像キャプチャをご確認の上で、お問合せください。
なお参加可能なのは一名のみになっております。
こちらの画面イメージもあわせて参照ください。実行
ターミナル上で textlint <filename> で実行します。NGワードがあれば検出されます。
$ textlint hoge.md
/mnt/c/apps/textlint-project/hoge.md
1:1 ✓ error お客様 => お客さま prh
1:7 ✓ error 問合せ => 問い合わせ prh
2:3 ✓ error キャプチャ => スクリーンショット prh
2:17 ✓ error 問合せ => 問い合わせ prh
3:10 ✓ error 一名 => ひとり prh
4:5 ✓ error 画面イメージ => スクリーンショット prh
✖ 6 problems (6 errors, 0 warnings)
✓ 6 fixable problems.
Try to run: $ textlint --fix [file]ターミナル上の表示ですが、Errorで行数が表示されるので便利です。
取得テキストを `.md` 形式のテキストファイルで保存
Zendesk Guideから取得した記事情報がGoogleスプレッドシートにセットされています。それら記事毎にMarkdown形式のファイルとして保存します。
Pythonとgspreadライブラリを利用して、ローカルフォルダに保存します。
ディレクトリ構成
$ tree -L 2 -I 'node_modules'
.
|── config.json
|── get_values_to_mdfile.py
|── package-lock.json
|── package.json
|── prh.yml
├── proofed_mdfile
│ ├── proofed_sentence1.md <─── 表記ゆれが検知の内容が追記されている
│ └── proofed_sentence3.md
|── run_textlint.py
├── mdfile <────表記ゆれが検知された場合、"./proofed_mdfile/"へ格納
│ ├── sentence1.md
│ ├── sentence2.md
│ └── sentence3.md
`── service_account.jsonGoogleスプレッドシートから記事テキストを取得してMarkdownファイルとして保存します。
import os
import datetime
import json
import pandas as pd
import gspread
from googleapiclient.discovery import build
def main():
ws = get_gspread_worksheet()
row_count, col_count = get_data_range(ws)
title_list = ws.range("C2:C{}".format(row_count))
body_list = ws.range("E2:E{}".format(row_count))
# もしmdfileディレクトリがなければ作成
mdfile_dir = "mdfile"
if not os.path.exists(mdfile_dir):
os.makedirs(mdfile_dir)
for title, body in zip(title_list, body_list):
if title.value and body.value:
# ファイル名に使用できない文字があったら空白に置換
available_title = ""
for text in title.value:
if text.isalnum():
available_title += text
else:
available_title += ' '
md_filename = "{}.md".format(available_title)
# mdfileディレクトリにファイルを作成
with open(os.path.join(mdfile_dir, md_filename), "w", encoding="utf-8") as md_file:
md_file.write(body.value)
# Google認証と、Googleスプレッドシート情報を取得
def get_gspread_worksheet():
gc = gspread.service_account(filename="./service_account.json")
wb = gc.open_by_key(SHEET_KEY)
ws = wb.worksheet('airticles')
return ws
# Googleスプレッドシートからシート内の記事テキストの範囲データを配列で取得
def get_data_range(ws):
sheet_data = ws.get_all_values()
row_count = len(sheet_data)
col_count = len(sheet_data[0])
return row_count, col_count
if __name__=='__main__':
PATH = os.getcwd()
CONFIG = PATH + "/config.json"
with open(CONFIG, "r", encoding="utf-8") as f:
json_load = json.load(f)
SHEET_KEY = json_load["client"]["sheet_key"]
main()実行後
実行後、 ./mdfile/配下に記事ファイルが作成されています。
$ ls -1 mdfile/
記事タイトル1.md
記事タイトル2.md
記事タイトル3.md
...
記事タイトル100.md補足
ローカルのファイル名に使用できない文字があった場合は保存できません。そのため空白に置換する処理を加えています。
if title.value and body.value:
# ファイル名に使用できない文字があったら空白に置換
available_title = ""
for text in title.value:
if text.isalnum():
available_title += text
else:
available_title += ' '
md_filename = "{}.md".format(available_title)textlintで一括チェックする
ここからやっと表記ゆれチェックに入ります。./mdfile/配下に作成された各Markdownファイルを全部チェックして、表記ゆれが検知された場合はファイル自体をコピーしつつ、ファイルの最下部へ検知内容を追記します。
textlintのコマンドを直接実行するために、subprocessモジュールを利用してPythonで繰り返し実行しています。
import os
import shutil
import subprocess
from subprocess import PIPE
def main():
files = os.listdir(input_path)
files_file = []
for f in files:
if os.path.isfile(os.path.join(input_path, f)):
files_file.append(f)
for file_name in files_file:
print(file_name)
result = subprocess.run(f"{cmd} {input_path}{file_name}", shell=True, stdout=PIPE, stderr=PIPE)
output_text = result.stdout.decode('utf-8')
# ファイルに校正が必要な場合のみ、replaced_textを実行
if "Try to run: $ textlint --fix" in output_text:
shutil.copy(os.path.join(input_path, file_name), os.path.join(output_path, file_name))
replaced_text = output_text.replace(replace_text_dir, "\n\n### 表記ゆれ in ").replace(replace_text, "")
print(replaced_text)
with open(os.path.join(output_path, file_name), "a+", encoding="utf-8") as output_file:
output_file.write(replaced_text)
if __name__=='__main__':
cmd = "textlint"
input_path = "./mdfile/"
output_path = "./proofed_mdfile/"
replace_text = "Try to run: $ textlint --fix [file]"
replace_text_dir = "/mnt/c/apps/textlint-project/mdfile/"
main()実行結果
表記ゆれが発生していたファイルが ./proofed_mdfile/配下にコピーされ、それらファイルの最下部に以下のように追記がされるようになります!
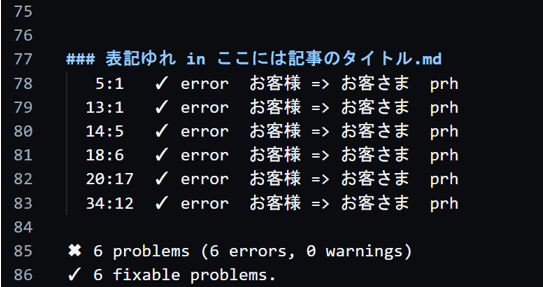
補足
output_text に `Try to run: $ textlint --fix` が含まれていれば"./mdfile/"内のファイルを、"./proofed_mdfile/"配下へコピーしています。
# ファイルに校正が必要な場合のみ、replaced_textを実行
if "Try to run: $ textlint --fix" in output_text:
shutil.copy(os.path.join(input_path, file_name), os.path.join(output_path, file_name))こうして表記ゆれが検知されたファイルのみに検知エラーが追記されるます。最後は目視で「エラーが適切か?」は確認する想定です。
最後に
何となく億劫だった作業を頑張れる気がしてきました。今後はtextlintのVscode拡張機能でコツコツ確認していくことで、自己正当化ムーブを未然に防げそうです。
この記事が気に入ったらサポートをしてみませんか?