
【好き勝手DIG】データベース_RDBの歴史編

SQL Serverを学んでいるだけだとつまらん. そもそもデータベースって何?から始める.
どんなものにでもストーリー, 歴史があり、変遷を経て現行状態・状況が形成されている.
ルーツ(なんで生まれたんだろうか), 分岐を含めたフォーク, 進化変遷を辿ることで解像度が高くなる.
歴史, 変遷を辿ることで、原理・原則・ゲームルールが理解できていくはず.
まあ, とにかく楽しみたいって感じ!!
データベースとは?
使途・存在意義
検索や蓄積が容易にできるよう整理された情報の集まり。 通常はコンピュータによって実現されたものを指す。(https://ja.wikipedia.org/wiki/データベース )
構成要素
データベースを実現するには、DBMSの理論だけでなく、それをソフトウェアとして作成する必要があるし、それはOSや言語に影響をうける。さらにハードウェアに実装する必要がある。(http://www.kogures.com/hitoshi/history/db-gaiyou/index.html)
データ管理方法(構造), データ保存のファイル(データ本体), データが保存されるファイルの管理アプリケーション(実現を担うソフトウェア), ソフトウェアが動くハードウェア, OS, OSの言語, データ演算プログラムって感じで分けて考えることができそう。
データベースでの大事な概念
単語ベースだけど列挙してみる。物理的データ独立性, 論理的データ独立性, トランザクション処理, データ完全性, セキュリティ, 障害復旧, 最適化, 分散データベース。( https://ja.wikipedia.org/wiki/データベース管理システム#DBMSの機能 )
データに対する一つの論理的操作の事をトランザクションと呼ばれるけど、ACIDっていう性質をもつべきと言われている。不可分性(Atomicity), 一貫性(Consistency), 独立性(Isolation), 永続性(Durability)である。
あとはシステム(サーバー)の非機能要件も存在する。機能性, 信頼性, 使用性, 効率性, 保守性, 移植性, 障害抑制性, 効果性, 運用性, 技術要件。( https://ja.wikipedia.org/wiki/非機能要件 )
ぼやき
ミッション、意識すべき点を「データベースでの大事な概念」にもち、その手段として構成要素を工夫していくことが大事なんだな...
ソフトウェア以前ってどうやって管理していた

1950年以前はパンチカードを使ってデータの保存を行っていた。極端に言えば、上記の画像のような。
そして、書き込みや読み込みはプログラムがインストールされた機械で行っていた。データ、つまりパンチカードの管理は人の手で行われていた。当時はオフィスの1つのフロア全部がまるまる、パンチカードを保管したり機械に読み込ませたりするために使われた。パンチの穴は2進数, 10進数で計算するプログラムに対応する形で位置されていた。
The management of data first became an issue in the 1950s, when computers were slow, clumsy, and required massive amounts of manual labor to operate. Several computer-oriented companies used entire floors to warehouse and “manage” only the punch cards storing their data. These same companies used other floors to maintain sorters, tabulators, and banks of card punches. Programs of the time were setup in a binary or decimal form, and were read from toggled on/off switches at the front of the computer, or magnetic tape, or even punch cards. (https://www.dataversity.net/brief-history-data-management/)
ちなみに、パンチカードも種類があり、進化の変遷がある。(https://ja.wikipedia.org/wiki/パンチカード#ホレリスのパンチカード)
データの保存先(ストレージ)の種類もパンチカード意外にもたくさんある。( https://ja.wikipedia.org/wiki/補助記憶装置#ストレージの例 )
個人の推測
とにかくデータの管理は、集約とか構造化されておらず、フォーマットに対して記述がされていたのがパンチカードで、それの管理や他プログラムとのつなぎこみを人の手を使ってやっていたって感じ(かな)。
後述する言語の発展とともに、人で担っていたデータ管理もプログラム化がスピードアップしていったと推測される。
プログラム言語の状況は?
1950年代以前、計算する側のプログラムは「Absolute Machine Language」と呼ばれていたらしい。絶対(完全?)機械言語っていう感じで、とにかく低級言語ってことだと思う。
その後、1950年代後半にアセンブリ言語が登場・普及した。1と0の複雑な文字列ではなく、アルファベットの文字が使えるようになり、人間にとって理解しやすい形になった。プログラムの開発を進めやすい形になった。それ以降、FORTRAN, Lisp, COBOL, BASIC, C, C++などが発展していった。
記憶媒体の状況は?
コンピューターの発展とともに記憶先(データ保存先)も紙脱却していった(電子化)していった。
たぶん、1940s辺りから技術としては実現可能な状態になった、と推測される。
たぶん、紙→磁気→光?ってなったのかな...( https://ja.wikipedia.org/wiki/補助記憶装置#ストレージの例 )
世の中、一般に普及したのはもっと先だと思われるが。
1944年 ツーゼがZ4を作成。メモリ部分は機械式に戻る。
1945年 ジョン・フォン・ノイマンのEDVACに関する報告書の第一草稿が発表。プログラム内蔵方式が提唱される。
1946年 ペンシルベニア大学で真空管を使って演算処理をするデジタル計算機ENIACが作成される。一般に広く知られた初のコンピュータ。( https://ja.wikipedia.org/wiki/コンピュータ#歴史 )
やっぱり、戦争ってのは技術発展・進化の側面から考えるとすごい効果的。
物理的にどのようなデータ管理をしているんだろうか?
実際にコンピューターの中でどのようにデータを管理しているんだろうか?
(勝手なイメージだけど)物理的にはデータ1つ1つはファイルとして保存されている。そして、そのファイルを管理するマスタファイルがいて全体を論理的に整理されているように管理している(んだろう)。要はファイルシステムを活用している。データのまとまりの大きさや、論理的な構造が設計次第で変わってくる(っていう感じ)。
参考
https://ja.wikipedia.org/wiki/ハードディスクドライブ#フォーマット
https://hnavi.co.jp/knowledge/blog/filesystem/
冒頭で記載したが、時代とともにデータの管理方法も進化してきた。データの一貫性はもちろん、人が扱いやすくとか、より効率的にシステムリソースを使うとか、耐障害の強度を上げたり、可用性を高めたりとか、大規模データを扱うとかっていうニーズに答えるべく進化が促されてきた。
論理的にどのようなデータ管理をしているんだろうか?
データモデル理論がどんな発展を遂げてきたか、である。管理を実現するデータベース管理システムも含めて言及していく。
列挙すると、hierarchical database/構造型(階層型)データベース, network database/ネットワークデータベース, relational database/関係データベース, object-oriented database/オブジェクト指向データベース, XML database/XMLデータベース, multi-dimensional database/多次元データベース, columnar storage/列指向データベース,in-memory database/インメモリデータベース。
データベース概念の登場
MaGee「源泉ファイル」(1959年)の論文にて、データを構造化して、管理を効率的・容易にできるというメリットが言及された。構造型データベース(Structural Database)の概念の登場。
データを集約して構造化することにより、データの重複を防ぎ管理が容易になること、データとプログラムを分離することによりプログラミング作成や保守が容易になることなどを示した。( http://www.kogures.com/hitoshi/history/db-gaiyou/index.html )
「Journal of the ACM Volume 6, Number 1, January 1959」に、「Generalization: Key to successful electronic data processing」という論文を発表しており、ここからデータベースの歴史がはじまります。この論文はコンピュータに蓄積されるさまざまなデータを源泉ファイル(source file)という概念に集約することにより、データの重複の回避とシステム拡張の効率化が可能になると書かれています。また、実際にシステムとして構築した場合、莫大なファイルから効率よくターゲットとなるデータを検索するための効率的な手段が要求されることやデータの保守技術や機密保持の技術が必要になることなども書かれています。いわば、この論文はデータベースシステムの概念を書いたものである( https://monoist.atmarkit.co.jp/mn/articles/0805/20/news108.html )
その後、親子関係が1:Nだったり、M:Nの構造のデータベースが開発された。
階層型データベース/Hierarchical Database
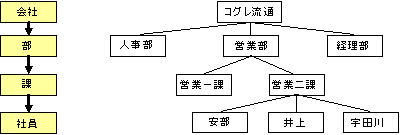
網型データベース/Network Database
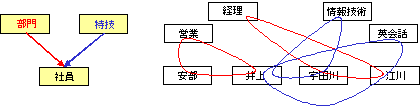
ちなみに、現実にデータベースが製品として登場するのは,1964年
1964年に,当時米GE(General Electric)の主任技師であったC.W.Bachman氏を中心に開発された,GE-225で稼働する最初のデータベース管理システム(DBMS)であるIDS(Integrated Data Store)です。このIDSは,ネットワーク・データモデルと呼ばれるデータモデルを持つデータベース( https://xtech.nikkei.com/it/article/COLUMN/20070312/264602/ )
そして、おなじみの関係データベース(Relatoinal Database)が登場
1969年 コッド RDBに関する最初の論文
HDBやNDBはデータベースを設計する段階で、[* 親子の結合を固定する静的結合なのに対して、RDBは処理を実行する段階で結合する動的結合である。]そのため、実行時の効率は悪いが、柔軟な処理ができる利点がある。( http://www.kogures.com/hitoshi/history/db-gaiyou/index.html )
参考
エドガー・F・コッド( https://ja.wikipedia.org/wiki/エドガー・F・コッド )の過去の経歴はかなり面白い。
関係モデル( https://ja.wikipedia.org/wiki/関係モデル#モデル )
関係データベース( https://ja.wikipedia.org/wiki/関係データベース )
二項関係( https://ja.wikipedia.org/wiki/二項関係#関係とグラフ )
Codd(コッド)から始まった関係型データモデル,(Relatoinal Database)
数学でいう「関係」の概念に基づいたデータモデルである。すなわち,データベースに含まれるべきすべてのデータを複数個の表形式で表現し,これらの表を「関係」と見なすことにより,データベースを集合論的に定式化したものである。以前のデータモデルが,ポインタとか繰返し構造のような物理構造に伴う複雑な構成要素を持っているのに対し,関係型モデルは「関係」という構造のみに基づき,それ以外の構成要素を全く必要としない,極めて単純化されたものであったため,発表当時は関係者の間で非常に大きな反響を呼んだ。( https://www.accumu.jp/back_numbers/vol12/データベースの理論とその発展.html )
その後、RDBへのアクセスを可能にした言語、SQLの登場
1974年 IBM、SEQUEL言語の開発、IBM、System RでのRDB実装
SEQUELはRDBをアクセスするための言語。後にSQLと改名され、1987年にISO/JISの規格になる。( http://www.kogures.com/hitoshi/history/db-gaiyou/index.html )
他企業も乗っかってくる。
1989年 Microsoft SQL Server
1993年 Microsoft SQL Server for Windows
MIcrosoftがサーバに乗り出してきた。RDBを搭載するサーバを次々と発表する。
その後、NoSQL, オブジェクト指向データベース, XMLデータベース, 多次元データベース, データウェアハウス, インメモリデータベース, 列指向データベース...などと周辺領域合わせて発展したきた。
なぜ"関係"モデルという名前なの?
集合論では昔から「二つの集合の直積の部分集合」のことを「2項関係」と呼んでいたからです。コッドはそれを n 項に拡張しただけです。彼は数学者でもありましたから、当然、集合論の関係の概念も知っていて、名前を借用した ( http://mickindex.sakura.ne.jp/database/db_whyname.html )
RDBが動的である、というのはうなずける。特定の範疇をもって集合としてデータをまとめ上げる(関係)。そして、それらを必要に応じて動的に結合を行って別の関係を作り出して、データ表現を行うっていうこと。
合わせて、読みたい
https://www.accumu.jp/back_numbers/vol12/データベースの理論とその発展.html
参考
https://ja.wikipedia.org/wiki/データベース
http://www.kogures.com/hitoshi/history/db-gaiyou/index.html
https://www.dataversity.net/brief-history-data-management/
この記事が気に入ったらサポートをしてみませんか?